Play偱懱摼偡傞RESTful傾乕僉僥僋僠儍偺婎慴抦幆丗Java偺忢幆傪曄偊傞Play framework擖栧乮5乯乮1/3 儁乕僕乯
僒乕僽儗僢僩乛JSP傪婎偵偡傞廳岤挿戝側Java偺Web奐敪偺僀儊乕僕傪曄偊傞寉検僼儗乕儉儚乕僋乽Play乿偵偮偄偰夝愢偟丄Web傾僾儕偺嶌傝曽傪徯夘偡傞擖栧楢嵹丅崱夞偼丄REST偺奣梫丄URI偺奣擮丄REST偱巊傢傟傞HTTP儊僜僢僪偲僗僥乕僞僗僐乕僪丄Play偱偺RESTful側愝寁丄幚憰忋偺栤戣揰側偳傪夝愢偟傑偡丅
REST傪棟夝偡傞偲丄Play framework偑暘偐傞
丂慜夞婰帠乽Play framework偺僐儞僩儘乕儔偺巊偄曽傪棟夝偡傞乿傑偱偼丄Java傪巊偆娤揰偐傜Play framework傪徯夘偟偰偒傑偟偨丅偟偐偟丄崱夞偼帇揰傪曄偊偰丄尵岅偵傛傞幚憰曽朄偱偼側偔Play framework偑摼堄偲偡傞僜僼僩僂僃傾丒傾乕僉僥僋僠儍偺僷僞乕儞偱偁傞乽REST乿傪僞乕僎僢僩偲偟偰徯夘偟傑偡丅
丂REST傪棟夝偟偨偆偊偱Play framework傪尒偰傒傞偲丄傛傝Play framework偑媮傔傞僔僗僥儉憸偑尒偊偰偔傞偐偲巚偄傑偡偺偱崱夞偼REST偺奣擮偵廳揰傪抲偄偰埲壓偺撪梕偱徯夘偟偰偄偒傑偡丅
REST偺奣梫
丂乽REST偭偰壗丠乿偲偄偆曽傕偄傞偐偲巚偆偺偱丄傑偢偼REST偵偮偄偰娙扨偵愢柧偟傑偡丅REST偲偼乽REpresentational State Transfer乿偺棯岅偱偁傝丄2000擭偵HTTP僾儘僩僐儖婯奿偺戙昞幰偺1恖偱偁傞Roy Fielding巵偑採彞偟偨暘嶶僔僗僥儉偵偍偗傞僜僼僩僂僃傾丒傾乕僉僥僋僠儍偺僷僞乕儞偺偙偲偱偡丅偦偺REST偺尨懃偵廬偭偨僔僗僥儉偺偙偲傪RESTful側僔僗僥儉偲偄偄傑偡丅
丂RESTful側僔僗僥儉偺摿挜偼丄僙僢僔儑儞傗僋僢僉乕側偳偱僋儔僀傾儞僩丒僒乕僶娫偺忣曬傪帩偪懕偗偢丄摨偠URI偱傾僋僙僗偟偨傜枅夞摨偠儕僜乕僗乮忣曬乯偑庢摼偱偒丄HTTP偱掕媊偝傟偨僐儅儞僪偺傒偱僔僗僥儉傪憖嶌偱偒傞偙偲偱偡丅
丂REST偱偺婎杮偲側傞尨懃偼4偮偁傝丄埲壓偺傕偺偵側傝傑偡丅
- 儕僜乕僗乮忣曬乯傪URI偱幆暿偱偒傞偙偲
- HTTP偱丄偡偱偵掕媊偝傟偰偄傞僐儅儞僪偲僗僥乕僞僗僐乕僪偵廬偭偰憖嶌偱偒傞偙偲
- 僗僥乕僩儗僗側僋儔僀傾儞僩丒僒乕僶娫偺傗傝偲傝傪偡傞偙偲
- 懠偺忣曬傊偺儕儞僋傪帩偮偙偲偑偱偒傞偙偲
丂崱夞偼REST偺婎杮尨懃偺偆偪丄1偲2偺乽儕僜乕僗乮忣曬乯傪URI偱幆暿偱偒傞偙偲乿乽HTTP偱丄偡偱偵掕媊偝傟偰偄傞僐儅儞僪偵廬偭偰憖嶌偱偒傞偙偲乿偵偮偄偰Play framework偲偺娭學傪愢柧偟偰偄偒傑偡丅
丂偪側傒偵丄懠偺3偲4偺2偮偺夝愢傪彍偄偨棟桼偱偡偑丄Web僔僗僥儉偵傛偭偰偼椺偊偽擣徹偑昁梫側僔僗僥儉側偳僗僥乕僩儗僗乮僙僢僔儑儞傗僋僢僉乕傪巊傢側偄忬懺乯偱偁傝懕偗傞偺偑擄偟偄傕偺偑偁傞偺偲丄儕儞僋偼晛抜丄奆偝傫偑巊偭偰偄傞偺偱丄崱偝傜弎傋傞傎偳偺偙偲偱傕側偄偐傜偱偡丅
儕僜乕僗乮忣曬乯傪幆暿偡傞URI偺奣擮
丂REST偺婎杮尨懃偺1偮偵儕僜乕僗傪URI偱幆暿偱偒傞偙偲偑偁傝傑偡偑丄偙傟偼摨偠URI偑帵偡忣曬偼忣曬尦偑峏怴傗嶍彍傪偝傟側偄尷傝丄枅夞摨偠忣曬偵側傞偲偄偆偙偲偱偡丅
丂偙偺儕僜乕僗偲URI偺娭學傪僀儊乕僕偟傗偡偄偺偼僼僅儖僟峔惉偲傾僪儗僗偺娭學偐偲巚偄傑偡丅椺偊偽丄壓婰偺傛偆側C捈壓偵偁傞乽僒儞僾儖乿偲偄偆僼僅儖僟偵擭寧擔偛偲偺婰帠偑偁偭偨偲偟傑偡丅
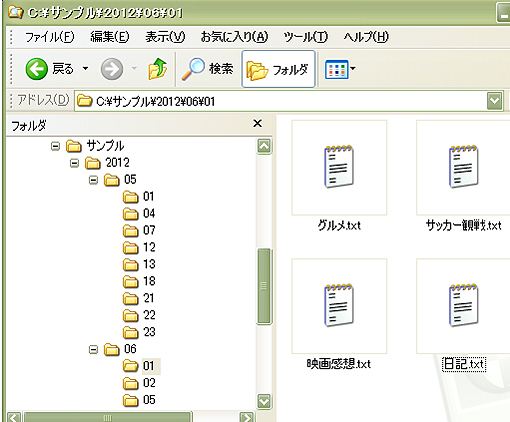
丂偙偙偱2012擭6寧1擔偺儕僜乕僗偵傾僋僙僗偟偨偄応崌偼丄傾僪儗僗偵乽C:\僒儞僾儖\2012\06\01\乿偲擖椡偡傞偲丄偦偙偺僼僅儖僟偵傾僋僙僗偱偒丄僼傽僀儖傗僼僅儖僟偺堦棗偑昞帵偝傟傑偡丅傑偨2012擭6寧偺儕僜乕僗側傜丄乽C:\僒儞僾儖\2012\06\乿偲傾僪儗僗偵擖椡偡傟偽丄偦偺寧偺奺擔乆偺僼僅儖僟偺堦棗偑昞帵偝傟傑偡丅
丂偙偺傛偆偵丄巜掕偟偨傾僪儗僗偵堄枴傪帩偨偣丄偦偙偵傾僋僙僗偡傟偽丄偦偺儕僜乕僗乮偙偙偱偼僼傽僀儖傗僼僅儖僟乯偑偁傞傛偆側偙偲傪URI偱昞尰偡傞偺偑URI偱儕僜乕僗傪幆暿偡傞峫偊曽偱偡丅
丂偦傟偱偼Web僔僗僥儉偱偼偳偆側傞偺偐丠 愭傎偳偺椺傪僽儘僌僒僀僩偵椺偊偰傒傑偟傚偆丅壓婰偺傛偆側URI傪巊偆偲丄擭寧擔偛偲偵僽儘僌婰帠偺儕僜乕僗傪庢摼偡傞傛偆偵愝寁壜擻偱偡丅
| URI | 儕僜乕僗 |
|---|---|
| http://乧乧/2012/ | 2012擭偺僽儘僌婰帠偺堦棗 |
| http://乧乧/2012/06/ | 2012擭6寧偺僽儘僌婰帠偺堦棗 |
| http://乧乧/2012/06/01 | 2012擭6寧1擔偺僽儘僌婰帠偺堦棗 |
丂傑偨丄擭寧擔偱偺嬫暘偗偱偼側偔壓婰偺傛偆偵僽儘僌婰帠偺僇僥僑儕偛偲偵儕僜乕僗傪庢摼偱偒傞傛偆偵偡傞偙偲傕壜擻偱偡丅
| URI | 儕僜乕僗 |
|---|---|
| http://乧乧/foods/ | 僌儖儊偵偮偄偰偺僽儘僌婰帠偺堦棗 |
| http://乧乧/sports/ | 僗億乕僣偵偮偄偰偺僽儘僌婰帠偺堦棗 |
| http://乧乧/movies/ | 塮夋偵偮偄偰偺僽儘僌婰帠偺堦棗 |
| http://乧乧/diaries/ | 擔婰偵偮偄偰偺僽儘僌婰帠偺堦棗 |
丂偝偰丄URI偱儕僜乕僗傪幆暿偱偒傞偙偲偵傛偭偰丄偳傫側棙揰偑偁傞偺偱偟傚偆偐丠
丂傑偢峫偊傜傟傞偺偼丄URI偱壗偺儕僜乕僗偑偁傞偺偐捈姶揑偵暘偐傝傗偡偄偙偲偑嫇偘傜傟傑偡丅椺偊偽丄儕僜乕僗偺巜掕傪慡偰僷儔儊乕僞偱巜掕偟偨応崌偵忋婰偺僽儘僌僒僀僩偱擭寧擔傪帵偡偵偼丄埲壓偺傛偆偵挿偔側偭偰偟傑偄傑偡丅
http://乧乧/blog?year=2012&month=6&day=1
丂偙偺掱搙側傜傑偩嫋梕偱偒傞斖埻偱偡偑丄偝傜偵擭寧擔偺傎偐偵挿暥偺傛偆側忣曬偑偁偭偨応崌偼丄僷儔儊乕僞偑偝傜偵捛壛偝傟挿偔側偭偰偟傑偄傑偡丅偦偟偰丄栚揑偺儕僜乕僗偵傾僋僙僗偡傞偨傔偵偼巜掕偡傞僷儔儊乕僞柤帺懱傪抦傜側偗傟偽側傜側偔側偭偰偟傑偄傑偡丅
丂偝傜偵丄URI偱儕僜乕僗傪巜掕偱偒傞応崌丄僽僢僋儅乕僋偺愝掕帪偺巇慻傒偑嶌傝傗偡偄偲偄偆棙揰偑偁傝傑偡丅傛偔偁傞偺偑慡偰忣曬傪POST儊僜僢僪偱慗堏偟偰偄偔僔僗僥儉偩偲丄傑偢URI偑曄傢傜側偄偺偱僽僢僋儅乕僋偡傞URI偑摿掕偱偒傑偣傫丅偦偆側傞偲枅夞僩僢僾儁乕僕偐傜偺慗堏偵側偭偰偟傑偄傑偡丅
丂僽僢僋儅乕僋偟偨偄儁乕僕偑僩僢僾儁乕僕偐傜怺偄儕儞僋傪偨偳傞応崌偼丄枅夞怺偄儕儞僋傪偨偳傜偹偽側傜偢丄儐乕僓乕偵偲偭偰巊偄彑庤偑椙偄僒僀僩偱偼側偔丄偐偮奐敪幰偵偲偭偰偼妋擣傗僥僗僩偡傞偺傕帪娫偑扗傢傟偰偟傑偄傑偡丅
Copyright © ITmedia, Inc. All Rights Reserved.