Webブラウザーだけで学ぶ機械学習の「お作法」:Webブラウザーでできる機械学習Azure ML入門(2)(3/4 ページ)
Azure MLの使い方を、機械学習の「お作法」に即して見ていきましょう。フローチャートと説明があるので、データを元にしたレコメンドの仕組みを確認できます。
お作法3:処理の定義、お作法4:データの学習
次に実際に機械学習の処理を見ていきましょう。本稿冒頭のML Studioの図で言うと、上から三つ目のエリアです。機械学習の処理を定義するには「Machine Learning」カテゴリにある「Initialize Model」「Score」「Train」の3つをセットで使うのが基本です。
それぞれの説明をしておくと、「Initialize Model」は機械学習のアルゴリズムによって、学習した内容を保持しているところだと思ってください。「Score」は学習の内容を利用し、入力されたデータに対して予測します。
簡単に言うと、結果を出すところです。
「Train」は学習用のデータを受け取り、「Initialize Model」で選択したアルゴリズムに受け渡します。また、「Score」に対して学習した内容を渡す機能も持っています。
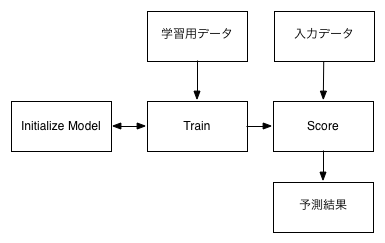
単純化した図でこのつながりを表すとこのようになります。中には「Train」と「Initialize Model」の部分が一緒になっているもの(今回使うMatchbox Recommenderはこれに該当します)もありますが、基本的にはこの構成であると考えてください。このような構成であることによって、「Initialize Model」の部分を置き換えることによって、さまざまなアルゴリズムでの検証が簡単にできるようになります。
このことを踏まえて、サンプルのMatchbox Recommenderを見て行きましょう。
上の段:機械学習の処理:Train Matchbox Recommender

今回のようなRecommenderについては、Matchbox RecommenderというアルゴリズムがAzure MLには最初から用意されています。
Train Matchbox Recommenderは、前述の「Train」機能と「Initialize Model」機能の両方を持ったものです。
ここからは、Train Matchbox Recommenderの機能を見ていきましょう。まず、箱を見ると、入力が三つに対して出力が一つであることが分かります。3つの入力のそれぞれの意味を見てみます。
まずは、左側にある○印が何なのかを調べてみましょう。入力を示す矢印の部分にマウスオーバーをすると、どんな項目で、何が必要なのかが表示されます。

詳しい説明はML Studio画面の右カラム、Propertiesの下の方に、ドキュメントへのリンクがあるので、クリックして参照します。

Train Matchbox Recommenderは「マッチボックスアルゴリズムを使ったベイジアン理論によるレコメンダー」である、と説明が記されている。ML Studio右カラムのメニューから、(more…)のリンクをクリックすると詳細説明を参照できる
ドキュメントを開いたときには「Expected Inputs」という項目が入力の詳しい説明になります。ここには、
- Training dataset of user-item-rating triples
- Training dataset of user features
- Training dataset of item features
と記載されいていることと思います。まず「Training dataset of user-item-rating triples」を詳しく見ていくと、Description(説明)の項目には、「Ratings of items by users, expressed as a triple (User, Item, Rating)」となっています。UserのIDとItemのIDとRatingを入れてほしいということのようですね。
実際にこの説明の通りになっているのかを確認するために、ここで、一つ戻って、「Train Matchbox Recommendar」の左側に接続されている「Split」の下左側の○印からどのようなデータが出力されているか確認してみましょう。ドキュメントの説明の通り、「userId」「placeID」「rating」の三つカラムの出力があることが確認できると思います。

このように、Azure MLでは出力と入力の形を合わせながらつなげていくことによって、機械学習の仕組みを作り上げていきます。
同様に、上辺中央の○印にはユーザーの特徴を示したデータセットを入力してくれとあります。そこで、接続元の「Project Columns」の出力をみてみましょう。今入力しようとしているデータはUserのIDの他に、緯度経度(latitude/longtitude)、関心(interest)と性格(personality)のデータが出力されています。

もう一つの上辺右側の入力である、レストランの情報も同じように見てみると、レストランのIDと緯度経度(latitude/longtitude)、価格帯(price)の情報が入力されているはずです。

ここまでのプロセスで、ユーザーの地理的情報と性格、関心、レストランの地理的情報と価格帯、またユーザーによる、レストランの評価のデータが結び付けられます。
こうした情報の入力によって、「Train Matchbox Recommender」の中では「こういう性格で、こういう関心があるユーザーであれば、このレストランに対してこのような評価をした」という実績情報を基に判断基準を自動的に学習していくのです。
Matchboxの詳しい情報を知りたい場合は
- http://research.microsoft.com/apps/pubs/default.aspx?id=79460
- http://research.microsoft.com/en-us/projects/matchbox/
- http://research.microsoft.com/pubs/79460/www09.pdf
を参照してください。
Copyright © ITmedia, Inc. All Rights Reserved.