事例で分かるデータ分析プロジェクトの進め方の基本:経営を左右するデータ分析入門(2)
ビジネスのデータ分析業務に12年ほど関わる筆者の経験に基づきデータ分析のプロジェクトがどのようなものかをお話しします。
前回の「4W1Hで分かる、ビジネスに本当に役立つデータ分析とは、どんなものか」では、「データ分析とは、そもそも何なのか」「何のためにやるのか」といったお話を紹介しました。連載2回目の今回は、データ分析のプロジェクトがどのようなものかをお話しします。具体的な内容ですが、まずプロジェクトのメンバーと座組みを示し、その後、プロジェクトの流れに沿って、概要を説明していきます。
今回の内容は、あくまで筆者の経験に基づくものですが、他のデータ分析者に聞いてみると、おおよそ同じような流れであるようなので、一般的なものに近いと考えていただいてもよいかもしれません。
メンバー(座組み)
- 事業側(分析結果を活用する側)
- 現場担当者:アウトプットを活用する人、仮説出しや施策への接続を担当
- 現場マネージャー:プロジェクト実施可否の意思決定、成果責任
- 分析側(カッコ内は、前回「Who」で説明した素養)
- プロジェクトマネージャー(コミュニケーション):プロジェクトの立ち上げ、マネジメント
- データアナリスト(サイエンス/エンジニア):データ処理と分析作業、アウトプット作成
データ分析プロジェクトの流れ
ここでは、データ分析プロジェクトの企画から、納品までの流れを説明します。
【1】データ分析で解決すべきビジネス課題を見つける
ここが全ての始まりです。事業側でニーズが顕在化して、分析側に声を掛けることもありますし、分析側から提案することもあります。それ以外にも、さまざまなパターンがありますが、今回は省きます。
【2】プロジェクトスコープの概要を決める
事業側と分析側で集まり、最初の話し合いを持ちます。解決すべき課題は何か、そのために必要となるデータはどんなものがあるか、どのような分析によって解決できるか、最終的なアウトプットは何にするかなどプロジェクトの大まかなスコープを決め、どのような、どれくらいの成果が期待できそうかについても考えます。
分析プロジェクトは、データがあってはじめて成り立ちますので、データのAvailability(利用可能性)は、ここで必ず確認しておきます。具体的にいうと、解決に十分なデータ(量・種類・質)があるかどうかの確認です。細かい確認はプロジェクト開始後に行うので、ここでは必要なデータが確実に存在し、入手可能であることを確認しておきます。
ここでデータが必要十分で、かつ「分析を行う意味がありそうだ」ということが見立てられれば、プロジェクトの立ち上げに進みます。
【3】分析企画を立てる
ビジネスでの他のプロジェクトと同じように、企画書を作成し、予算を確保します。またここで作成した企画は、その後の分析のためのラフプランになります。内容としては、以下のようなものを含むことが多いようです。
- (必要項目)
- ビジネス背景や課題:なぜ、このプロジェクトをやる必要があるのかを質的に評価
- キーとなるアウトプット:実務に活用できるイメージを直感的に伝える
- 効果の見立て:このプロジェクトによってもたらされる効果を提示(コスト削減幅、利益改善幅など)
- スケジュール・見積り工数/金額:「いつまでに、どの程度の費用でできるか」を提示
- (あると望ましい項目)
- 使用データ:どのようなデータを使うのかを提示
- 分析概要:どのような分析(手法)を、どのようなインフラ(ハード/ソフト)で行うのか、アウトプットを作成するのかなどを提示
- 座組み:登場人物とその役割を提示
- 詳細なスケジュール:どのような工程と時間で作業が進むのかを提示
企画にGOをもらうためには「いくらの費用で、いつごろ、どのようなアウトプットが出るか」「アウトプットを活用することで、どれくらいの効果が得られるか」を明確に提示することが重要です。これがしっかりしていれば、多少の困難はあってもプロジェクトはうまく進むはずです。
逆に、この部分が曖昧だと、何かの弾みで企画が通ったとしても、良いアウトプットが得られないリスクが高まります。これらを防ぐためには、「あると望ましい項目」をできるだけ検討しておき、企画の精度を高めておくことが重要です。
また、もう一つやるべきこととして、「期待値の調整」というものがあります。これは、プロジェクトが成功したときに、達成できることに加えて、達成できないことも明確にしておき、事業側の同意を得ておくということです。データ分析になじみがないと、上記の区別は難しいものです。
調整を行っておかないと、プロジェクトが終わりに差し掛かった頃に、「事業側ができると思っていたことが、実はできなかった」という不整合が起こることがあります。
【4】プロジェクトのキックオフに向けて、詳細な分析プランを作成する
無事、企画にGOが出たら、早速プロジェクトのキックオフに向けて、詳細なプランを作成します。これは、分析側が行います。【3】での「あると望ましい項目」の部分を、実際に作業ができるように、細かく割っていきます。
これは、スケジュールでいうと、企画書の段階では週ごとに矢羽で示したような簡単なスケジュール表だったものを、ガントチャートに落としていくような作業です。
【5】キックオフミーティング
プロジェクトに参画するメンバー全員が顔をそろえて、キックオフミーティングを行います。詳細プランに従って、工程やスケジュールの確認、座組みの確認、ゴールの再確認などを行います。士気を高めるために、ここで飲み会をするのもよいと思います(笑)。
【6】データ収集・整理・マート作成
データ分析は、データの準備が8割といわれます。これは、「良い分析を行うためには、データの準備を丁寧に行うことが重要である」ということを示しています。
データの準備は、「集める」「まとめる」「精査する」といった工程で行われます。もう少し具体的にいうと、分析に必要なデータを方々から集め、分析できるようにそれらを一つにまとめ、そこからおかしなデータを排除し、分析にかけられる状態にする工程です。
まず、「集める」です。分析で使うデータは、いろいろなところに散らばって存在しています。例えば、売上データはPOSシステムに格納され、プロモーション費用は会計データベースにあり、自社WebサイトのアクセスログデータはHadoopに、営業行動履歴データはAccessで管理されている、などなど……。個人情報管理に注意しなければならない昨今、これらの各データベースにアクセスし、集めるだけでも大変な労力です。しかし、次の工程で広く仮説を検討するため、工数が許す限り、多くの種類・長い期間のデータを集めておきます
これらのデータが無事集まったら、次は「まとめる」工程です。一言で言うと、これらのデータを、何らかのデータベースに一元化(一つのデータベースにまとめること)します。まとまったデータベースのことを、専門用語でデータマートと呼ぶことがあります。
この後の「精査する」は、次の工程で行われます。
【7】基礎集計、仮説出し
ここでは、集めたデータをいろいろな観点で集計します。集計を行う目的は、「データ精査」と「仮説出し」です。前回のお話に対応させるならば、ここでは「分析」を行うための「仮説導出」を行いながら、データをきれいにする作業を続けます。
集計してみると、データにおかしなところが次々と見つかります。例えば時系列で集計してみると、ある時点だけ急に値が大きかったり、小さかったり、突然傾向が変わったり、途切れていたり……。これらの状況を、事情を知っているメンバーと確認していきます(ここでは、事業側の施策担当者やデータ管理者がゲストで参加することもあります)。
ここでのポイントは、上記のような異常な変動が、取り除くべき「ノイズ」なのか、分析に含めるべき「事実」なのかを見分けることです。気になる部分は徹底的に質問して解明します。
例えば、傾向が突然変わっていたとしても、施策を変えた結果であれば、それは現実に起こったことなので、排除せずに分析にかけるべきです。一方、システムの不具合などで値が変わってしまったのであれば、それは現実に起こったことではなく「嘘の値」なので、何らかの方法で本来の値に補正する、おかしい部分を除去するなどの対応を行います。なお、ここでどれだけ頑張るかが、その後の分析の質に大きく影響しますので、気になる部分は徹底的に解明します。データ準備は、以上の工程を経て、ようやく終わります。
仮説出しには、「散布図」や「相関分析」をよく用います。どちらの方法も、2種類のデータの動きの近さを測定するものです。前者はそれを図示するもので、後者は数値化するものです。これらの例を下図に示します。
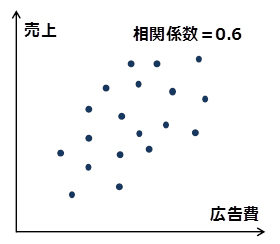
上図では、広告費が高いほど売上も高い傾向にある。相関係数も0.6と、正の方向で比較的大きい値
→「広告費を掛けると売上が伸びる」という仮説を立てられる
※相関係数:二つの系列(種類)のデータの変動の近さを示す指標で、-1〜1の値を取る。値が正の場合は、一方が大きいほどもう一方も大きい傾向があることを示す。負の場合は逆に、一方が大きいほどもう一方は小さい傾向がある。また、値の絶対値が1に近づくほど、それらの動きの連動性が強いことを示す。
これらの方法を用いて、仮説を作っていきますが、ここで作る仮説は、今後、絶対に変えてはいけないというものではありません。ここでは「ざっくりとした」仮説を作り、そこから先はデータに聞きながら(=分析しながら)、確度を高めていくといった感じです。
【8】分析作業
ここから、ようやく分析作業に入ります。通常は、課題に応じて分析手法は決まりますので、それで解析にかけていきます。解析作業で具体的に行うことは、「統計モデル」を作成することです。
「統計モデル」(以下、単にモデル)とは、実際の現象を何本もの数式で示したもので、いわば「仮説の束」といえるものです。これを観察することで、現実に起きていることの解釈や原因究明、今後の予測などを行うことができます。
モデルの作成は、統計的な妥当性と、事業側の持つ仮説をすり合わせながら行います。言い換えると、「事業側の仮説を、分析側で検証する」やりとりを繰り返すということです。具体的にいうと「分析側でモデルを作り、それを施策担当者に提示し、実務の観点からコメントをもらい、そこからさらにモデルを作成する」というやりとりを繰り返し、統計モデルを磨き込みます。
ちなみに、この過程で、新たな仮説が見つかることもよくあります(実務担当者が思いついたり、データから見えてきたりすることが多いです)。その場合は、工数とスケジュールの許す範囲で、その仮説を表すデータを取得し、分析に加えていきます。
このプロセスは、基本的にはやればやるほどよいので、工数が許す限り実施します。
【9】アウトプットの作成・納品
分析結果が確定したら、企画書、または詳細プランの中で決めていたものを作成します。よくあるアウトプットとしては、分析結果とそこからの知見などをまとめた報告書や、作成したモデルを組み込み、予測やシミュレーションを行えるようにしたツールなどです。
ツールの場合、分析を始めたころから時間も経っており、当初とはビジネス状況や分析の方向性が変わっていることもありますので、再度仕様を見直すこともあります。
前回の内容と併せて読んで理解を深めよう
今回は、データ分析のプロジェクトがどんなものか、流れに沿って説明しました。前回の内容と併せて読んでいただくと、データ分析についての理解を深めていただけます。
著者プロフィール

青柳憲治
リクルートテクノロジーズ ITソリューション統括部 ビッグデータ部 ビッグデータ1G
筑波大学大学院ビジネス科学研究科企業科学専攻(博士後期課程)
大学卒業後、マーケティング・コンサルティング企業に入社。約8年間、広告効果分析を中心としたマーケティング関連データの分析業務に携わる。
2012年1月よりリクルート入社。リクルートグループ全体のマーケティングの高度化を目指してデータ解析チームを立ち上げ、現在に至る。
また業務の傍ら、筑波大学大学院ビジネス科学研究科(博士前期課程)・同大学院企業科学専攻(博士後期課程)に所属し、先端的な統計解析手法を用いた計量マーケティングをテーマとして研究に取り組む。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。 Rは統計解析のブッシュナイフだ
Rは統計解析のブッシュナイフだ
今ほど統計解析が必要とされる時代はありません。オープンソースの統計処理言語・環境の「R」を使って実践的な統計解析のテクニックとリテラシーを習得しましょう! 読者にとってRは、世に溢れるデータの密林を切り開くための“ブッシュナイフ”となることでしょう(編集部) いまさら聞けないHadoopとテキストマイニング入門
いまさら聞けないHadoopとテキストマイニング入門
Hadoopとは何かを解説し、実際にHadoopを使って大規模データを対象にしたテキストマイニングを行います。テキストマイニングを行うサンプルプログラムの作成を通じて、Hadoopの使い方や、どのように活用できるのかを解説します 並列分散処理の常識をHadoopファミリから学ぶ
並列分散処理の常識をHadoopファミリから学ぶ
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載 ビジネスインテリジェンスとは何か
ビジネスインテリジェンスとは何か
ビジネスインテリジェンス(BI)の概要を解説した記事が多くのメディアで取り上げられるようになり、その基本的な理解は深まったと思われる。このような現状を踏まえ、本連載ではさらに一歩踏み込んだ内容として、データ分析の手法や注意点に焦点を絞った実践的な解説を展開する。(編集部)