機械学習の前に重要なデータ抽出・加工に便利なPythonライブラリ「pandas」の基本的な使い方のチュートリアル:Pythonで始める機械学習入門(6)(4/4 ページ)
最近流行の機械学習/Deep Learningを試してみたいという人のために、Pythonを使った機械学習について主要なライブラリ/ツールの使い方を中心に解説する連載。今回は、データ分析の前処理などで便利に使えるオープンソースソフトウェア(OSS)のPythonライブラリ「pandas」を紹介します。
データの連結・結合
データの連結・結合について見てみます。まずはデータを用意します。
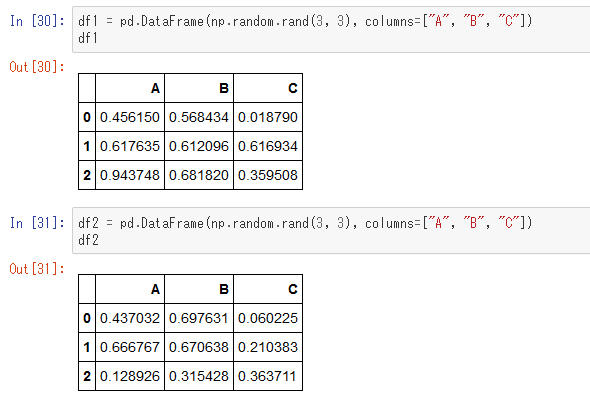
縦に連結する「concat」メソッド
df1とdf2を縦につなげてみます。
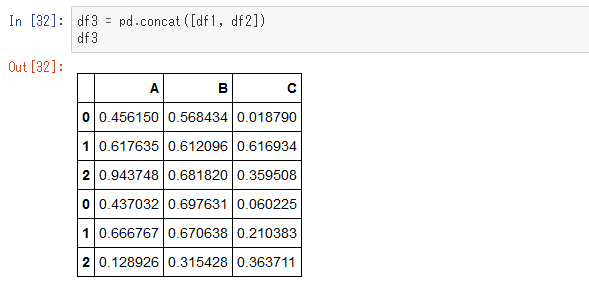
インデックスを振り直す「reset_index」メソッド
これで一応縦に連結されましたが、インデックスが変わってないのには違和感があるかもしれません。インデックスを振り直すには次のようにします。
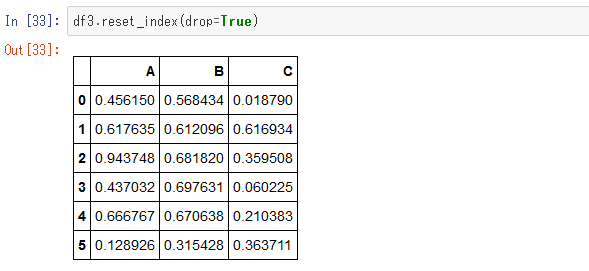
ここで「drop=True」というのは、古いインデックスを捨てることを意味します。
横に連結する「merge」メソッド
ここからは、表を横方向に結合する連作(SQLでいうと「join」に該当)を見てみます。キーとなる値を見て連結するので、キーとなるデータを付加します。
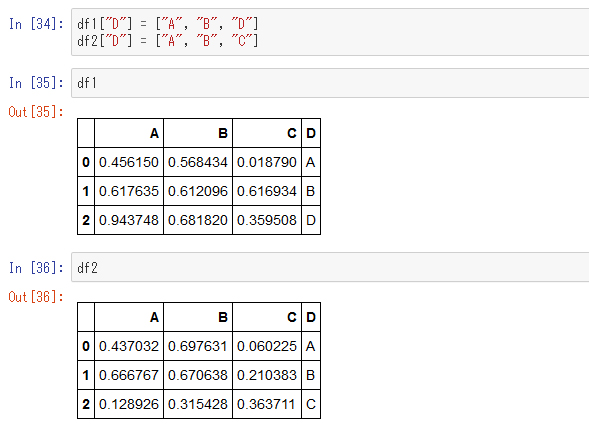
これを結合してみましょう。
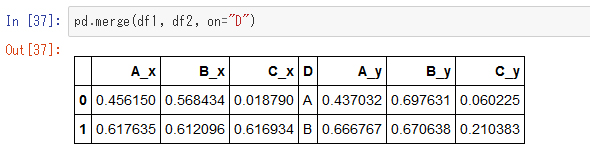
これはD列をキーにして結合しています。共通するキー値が"A"と"B"しかないので、それ以外の行が捨てられています。これはSQLでいうところの「内部結合」に当たる処理です。
次に、「外部結合」も試してみます。
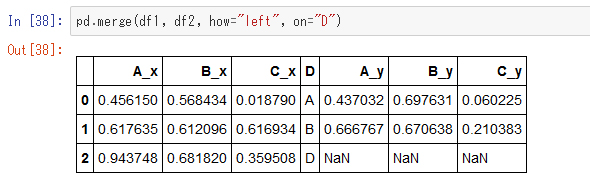
これはSQLでは「左外部結合」と呼ばれているもので、左側のデータdf1のキー値が全て生かされ、対応するdf2の行がない場合は「欠損値」として取り扱われます。
配列型への変換――valuesプロパティ
今までDataFrame型データのさまざまな処理の方法を見てきましたが、機械学習を使った処理について考えると、これらは前処理を簡潔にすることに向いています。
前処理が一通り終わって機械学習アルゴリズムを適用しようとすると、今度はNumPyの配列型の方が都合が良いことが多いです。そういう場合はvaluesプロパティを参照します。次がその例です。
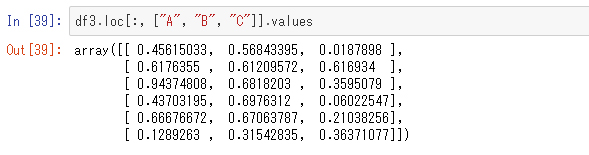
ここではA、B、C列だけを配列として取り出しました。これはNumPyで扱える2次元配列です。
まずはデータローダだけからでも始めてみよう
以上、pandasの機能のうち機械学習適用における前処理としてよく使われるであろう機能だけを絞って紹介しました。
pandasは非常に多機能であり、またインタフェースが独特なので使いこなすのはそれなりに難しいのですが、習熟すると処理の効率の面で強力な武器になります。詳細は公式サイトのマニュアルを参照してください。
初心者にはとっつきにくいかもしれませんが、とにかくデータローダが便利で使いやすいので、まずはデータローダだけを使ってみるところからスタートして、抽出にも少しずつ慣れていくというやり方もいいと思います。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
本連載では、さまざまなソフトウェアのインストール、実行するためのセットアップ設定、実行確認、アンインストールの手順を解説する。今回は、Pythonとは何か、Pythonのインストールとアンインストールについて解説。Pythonがよく使われる機械学習やビッグデータ解析を始める参考にしてほしい。 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。 Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。