アプリ開発者とインフラ技術者間のSRE的なコミュニケーション改善に役立つインフラ基盤とは:SREの考え方で“運用”を変えるインフラ基盤 大解剖(3)(1/3 ページ)
本連載では、「インフラの、特に基盤寄りの立場からSRE(Site Reliability Engineering)の活動を行い、Webサービスの価値を高めるためにはどうしたらいいか」について、リクルートの新たなインフラ基盤を例に見ていきます。今回は、インフラ基盤の技術的解説とともに、出始めている成果、今後の展望についてお話しします。
本連載「SREの考え方で“運用”を変えるインフラ基盤 大解剖」では、「インフラの、特に基盤寄りの立場からSRE(Site Reliability Engineering)の活動を行い、Webサービスの価値を高めるためにはどうしたらいいか」に悩んでいる方々に向けて、リクルートの新たなインフラ基盤である「RAFTEL Fleetサービス(以下、Fleet)」を作ることになった背景と狙い、そして「いかにしてFleetを作り上げたのか」について順に紹介しています。
前々回はFleetが生まれた背景と解決したい課題を紹介し、前回はFleetの構成要素の1つ「Fleet Management Console」(Fleetコンソール)を紹介しました。
最終回となる今回では、残るもう1つの構成要素である「Fleetインフラ基盤」の紹介とFleetで出始めている成果、今後の展望についてお話しします。
Fleetインフラ基盤の概要と特徴
前回も触れましたが、Fleetインフラ基盤は、高い信頼性を持ちながら自動化を支えるものです。大きくソフトウェアコンポーネントと物理コンポーネントに分かれています。
- ソフトウェアコンポーネント
- VMware vSphere ESXi
- VMware vCenter Server
- VMware NSX(以下、NSX)
- F5 BIG-IP Virtual Edition(以下、BIG-IP VE)
- 物理コンポーネント
- 物理ストレージ
- 物理スイッチ(下層ネットワーク)
- 物理サーバ
- 対既存インフラ接続物理ルーター
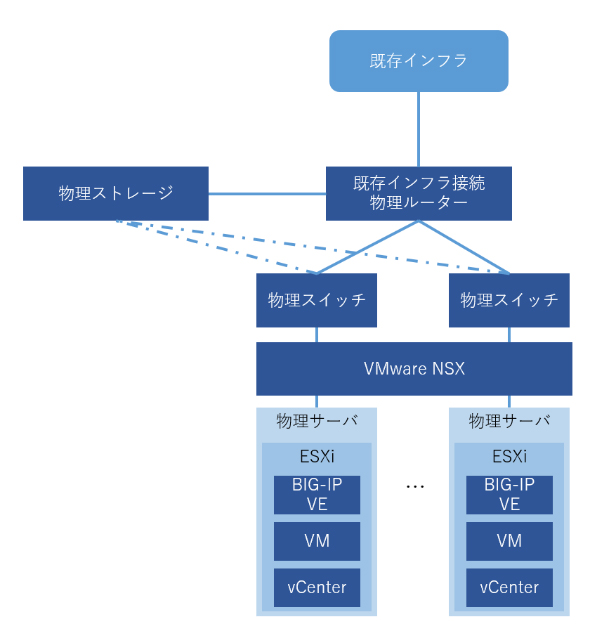
特徴としては、物理コンポーネントのほとんどは、既存のオンプレミスインフラ「RAFTEL」の機器を流用しており、これを下層にしてその上にソフトウェアコンポーネントで仮想的なインフラを作り出している点にあります。
つまりFleetは新規のオンプレミスインフラではありますが、実態としては既存のインフラ基盤の物理資産を生かし、その上に構築した仮想的なインフラとなっています。
これらのコンポーネントには、インフラリソースの払い出しや設定変更を「Fleetコンソール」からオンデマンドに行うことで高速化、自動化を実現できる製品を採用しています。
特に、インフラリソースの払い出しや設定変更に時間を要していた“ネットワーク”に関連するコンポーネントを、仮想化可能、API払い出し可能としたことが既存のオンプレミスインフラRAFTELで実現できていなかった「Fleet」ならではの特色と言えます。
“理想的”なネットワーク設定の自動化を実現するために行った3つのこと
ここからは、「Fleetがいかにしてネットワーク設定の自動化を実現したのか」について、その詳細を3段階に分けて紹介します。
【1】ネットワーク選びで押さえたい要点の洗い出し
Fleetのコンセプトである「即時提供によるリードタイムの解消」「開発者が希望する好きな設定を可能に」「そもそも依頼者が自ら設定することで申請を不要な世界観に」をオンプレミスで実現するにはどんなネットワークが必要なのか? どんな製品を選ぶべきか? 議論を重ねて導いたわれわれなりの答えが下記です。
- 初期投資額を抑制する
ミニマムスタートができてニーズに応じて拡張可能かつリクルートのサービスを支えるための十分な性能を有すること - すぐに作って、すぐに捨てられるネットワークを実現する
新しいアイデアをすぐに試せて、終わったらすぐに捨てられる使い方を想定 - 相互影響を排除する
ユーザーが直接ネットワークの設定を行うので、あるユーザーの操作ミスが各サイトの動作に影響を与えないこと - APIが充実している
FleetコンソールからAPIでの操作がメインとなるため - 完成度が高く長く使える
製品自体が未成熟であったり、製品の将来性が見込めず突然の販売停止などのリスクがあったりする製品は選ばないこと
【2】洗い出した要点に合わせた機器選定
この要件に基づき機器選定した結果が図1の構成です。選定のポイントをまとめると下記のようになります。
「初期投資額を抑制する」ために、繰り返しますが、下層にはRAFTELの既存物理機器をそのまま使用しました。
「すぐに作って、すぐに捨てられるネットワークを実現する」ために、主要コンポーネントであるロードバランサーやファイアウォールについては、物理機器ではなく仮想アプライアンス製品(BIG-IP VE、NSX)を導入しました。
「相互影響を排除する」ために、サイト間のロードバランサーについては、各サイト専用に仮想ロードバランサーを割り当てる設計としました。しかし、仮想ロードバランサーはSSL復号が苦手であるため、その機能を物理ロードバランサーにオフロードできる「Crypto offloading」機能を持つBIG-IP VEを選定しました。またBIG-IP VEの選定理由としては、既存のRAFTELがBIG-IPを採用しており、L7トラフィック管理の「iRules」をそのままBIG-IP VEに移行できる利便性も考慮されています。
「APIが充実している」ことから、ファイアウォールについては、NSXを選定しました。「セキュリティタグ」機能でサイト単位でファイアウォールルールを分割することもでき、スケールアウトで拡張が可能なことも選定を後押ししました。
【3】自動化すべき業務としなくていい業務の選別
「何の作業を自動化して、何を自動化しないのか」について、その振り分けを行いました。具体的には、頻繁に発生する下記の作業のみ自動化の対象としています。
- 新規仮想サーバのネットワークへの組み込み
- 仮想サーバの通信要件(ファイアウォールルール)の設定、変更、削除
- ロードバランス設定の追加、変更、削除
一方で、実施頻度が低い以下の設定作業は割り切って自動化対象外として、手動運用としました。
- 新規サイトのセグメント割り当て
- 新規サイトのロードバランサー立ち上げ
- 新規SSL証明書のロードバランサーへのインストール(ただし、ワイルドカード証明書を使うことで、一度インストールした証明書は複数のドメインで利用可能とした)
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 SREの現場はどうなっているのか――従来型の運用との決定的な違いとは
SREの現場はどうなっているのか――従来型の運用との決定的な違いとは
Site Reliability Engineering(以下、SRE)の現場はどうなっているのか。SREの日常的な仕事とはどのようなものなのか。開発エンジニアと運用担当エンジニアは、実際どのように役割分担し、協力し合っているのか。「SRE本」の監訳者などが語った。 エンジニア視点で説明する「メルカリ」、リリースから4年の道のり
エンジニア視点で説明する「メルカリ」、リリースから4年の道のり
2017年6月、執行役員 Chief Business Officer(CBO)に、元Facebookのバイスプレジデント ジョン・ラーゲリン氏を迎えるなど、国内はもちろんグローバル展開も加速させているメルカリ。世界に支持される同社サービスはどのように作られ、支えられているのか?――2017年9月に開催された技術カンファレンス「Mercari Tech Conf 2017」にサービス開発・運用の舞台裏を探った。 富士フイルムとメルカリSREが語る、「運用管理」という仕事の本当の価値と役割とは
富士フイルムとメルカリSREが語る、「運用管理」という仕事の本当の価値と役割とは
@ITは2017年12月12日に「@IT運用管理セミナー〜運用管理は『なくなる仕事』?」を開催した。本稿では、その内容をレポートする。