Lesson 1 機械学習を始めるための、Pythonデータ構造「多次元リスト」入門:機械学習&ディープラーニング入門(データ構造編)
Pythonの基本的な言語仕様では、データはどう表現できるのか? 単一の数値データから始め、1次元、2次元、……多次元と複数の数値データを表現できるリスト型のデータ構造まで、ステップ・バイ・ステップで見ていく。
ご注意:本記事は、@IT/Deep Insider編集部(デジタルアドバンテージ社)が「deepinsider.jp」というサイトから、内容を改変することなく、そのまま「@IT」へと転載したものです。このため用字用語の統一ルールなどは@ITのそれとは一致しません。あらかじめご了承ください。
はじめに
【これを学ぼう】Pythonデータ構造入門
先生! 確か以前に「機械学習では、特にデータが重要」って言ってましたよね?
そうよ。そもそもAI・ディープラーニングは、データの数値を数学の計算式を使って計算していく技術だからね。この連載では、Pythonでどうデータが表現できるかを、基礎から実践まで1つずつステップを踏みながら説明していくね。
読者対象
- 初めてディープラーニングや機械学習を学び始めるが、プログラミングも初めて学ぶ方
学習内容
AIの代表格である機械学習やディープラーニングは、もともとはデータ分析やデータサイエンスという分野の技術に過ぎない。つまり、データやビッグデータ(=クラウドなどに溜まる、2010年以前では考えられないくらい膨大なデータのこと)が常に必要になるのだ。
そこで本連載では、「データ」に焦点を絞り、プログラム内でデータを扱うための、Python言語仕様の「リスト型」の基本構造から、実践で活用することになるライブラリ「NumPy」の使い方までを、ステップ・バイ・ステップで紹介する。
実行環境
本連載は、Pythonコードを手元で実行しながら、読み進めることを想定している。
Pythonコードの実行環境としては、Google Colaboratory(以下、Google Colab)を用いる。Google Colabは、インタラクティブシェルを活用したノートブック形式のオンラインPython実行環境で、(2018年12月時点では)誰でも無償で利用できる。初心者や学習者にはうってつけの環境である。
Python言語のバージョンは3系を使うことを想定している。Pythonのバージョンについては、『機械学習&ディープラーニング入門(Python編)』のLesson 1で解説している。
デモとサンプルコード
本連載のすべてのサンプルコードは、下記のリンク先で実行もしくは参照できる。
Python言語におけるデータの構造
連載初回の今回は、「Pythonの言語仕様であるリスト型とは何か?」、さらに「そのリスト型が、元々の1次元(1D)から、2次元(2D)、3次元(3D)、……多次元(N- Dimension)へと、次元数を増やせる」ということを理解してほしい。
まずは原点に立ち返って、「データとは何か」から整理していこう。
データとは
データ(data)とは、「事実や資料となる情報」のことである。厳密には、複数の事象や数値の集まりのことである*1。
*1 「複数の」と記載したように、英単語の「data」は複数形で、単数形は「datum」(データム)である。
と、辞書的な説明をされても、直感的に理解しづらいという意見はあるだろう。何となくつかみどころがない概念である。
そもそも「データ」は、一般社会でも非常によく聞く単語である。例えばスマートフォンなどでゲームをしたときに、クリアしたステージや得点などの情報(=データ)が保存されるだろう。このように、われわれの日常生活はデータにあふれている。
それはもう、小学生の時からである。例えば「授業の時間割表」や「九九の掛け算表」も、立派なデータと言える。ここで表という単語が出てきたが、実はデータは、表の形式で管理されることがほとんどだ。そのような表形式のデータは、表データ(Table data)などと呼ばれている。
よって、「機械学習やディープラーニングにおけるデータとは何か?」を、誤解を恐れずに平たく言うのであれば、「(基本的に)表形式にまとめられた情報」と説明できる。とりあえず現時点では、この定義を押さえてほしい(※以降で、表という2次元のデータ形式以外にも触れていく)。
具体的な例を考えてみよう。例えば、高校のクラス全員の身長と体重を測って、その値を表形式にまとめてデータを作るとしよう。このクラスには、花さん、太郎くん、次郎くんの3人が所属しており*2、それぞれの身長と体重が次のようだったとする。
- 花(hana): 身長=165.5cm、体重=58.4kg
- 太郎(taro):身長=177.2cm、体重=67.8kg
- 次郎(jiro):身長=183.2cm、体重=83.7kg
*2 データ数が多いと作業や説明がムダに長くなるので、非現実的な話ではあるが、ここではクラスの人数は最小限の3人にしている。
本稿の読者であれば、これを表データにする作業は何ら難しくないだろう。時間割表を作る要領で、図1のように作ればよい。ちなみに図1は、Windows PC上でExcelという表計算ソフトを使って作成した表データ(表計算データとも呼ばれる)である。

以下では、この表データを題材に、Python言語でどのようにデータを表現できるかを見ていくことにしよう。
最小単位となる個々の数値
図1の表データから、最小単位となる個々のデータ要素(数値)を抽出することを考えてみよう。
表データは、説明するまでもないと思うが、横に並ぶのが「列」で、縦に並ぶのが「行」である。
なお、図2-1を見ると、[名前]列に「花」「太郎」「次郎」とある。これらは、数値ではなく、各行に付けられた見出し(header)だと考えられるので、ここでの「Python言語によるデータ表現」からは除外しよう。

すると、図2-1で赤色の円で示したように、
- 165.5
- 58.4
- 177.2
- 67.8
- 183.2
- 83.7
という6個の数値を抽出できる。これらが、表データを構成する最小限の個々のデータ要素、つまり単一のデータ(厳密にはデータム)となる。
では、このような単一のデータをPythonで表現するには、どうすればよいだろうか? ここでは例として、「太郎くんの身長が177.2cmであること」をPythonで表現してみよう。
これは、変数に値を代入するだけだ(※「変数への値の代入」の意味が分からない場合は、下記のコラムを参照されたい)。
【コラム】Pythonで数値を表現するための基礎知識
このコラムでは、Python言語の基礎文法の一つ、「変数への値の代入」について簡単に触れておこう。
Pythonのプログラム内でデータを保持・管理するには、変数(variable)が使われる。変数とは、「変わる数」という名前どおり、中身が変わる入れ物のことだ。ここでは、何でも入れられる箱をイメージしてほしい。
その箱の中に、177.2といった値(ここでは「単一のデータ」)を入れることになる。「入れること」は、プログラミング用語で代入(assign)と呼んでいる。
代入後の変数(箱)は、オブジェクト(object)と呼ばれる。ちなみに、Pythonのプログラムは、このようなオブジェクトを多数生成して構成する世界なので、オブジェクト指向(Object-oriented)と呼ばれる。また、Python言語自身は、オブジェクト指向プログラミング言語(Object-oriented programming language)と呼ばれる。
177.2は数値だが、文章である文字列値など、さまざまな種類の値が、変数に代入できる。本稿で説明する「リスト型」も、そんな「値の種類」の一つである。この「値の種類」は、プログラミング用語で型(type)と呼ばれている。
実は、数値の型(数値型と呼ばれる)は一種類ではなく、主に次の2つがある。
- int型: 500、0、-10のような整数値(=自然数に0と負の数を加えた数)
- float型: 177.2、0.0、-1.5のような実数値(=整数に、小数値を加えた数)
機械学習やディープラーニングの場合、小数点以下の細かい実数値を計算することがほとんどである。そのため、データの値としては、ほぼfloat型しか利用しない。
なお、float型の値は、厳密には「実数値」ではなく、プログラミング用語で浮動小数点数値と呼ぶ。浮動小数点数値とは、符号と指数と仮数を用いて表された実数値のことであるが、その内容を説明すると長くなってしまうので、ここでは説明を割愛する。「浮動小数点数値は、実数値と同等のもの」と考えておけば問題ない。
以上を踏まえて、「太郎くんの身長が177.2cmであること」を、「箱の中に値を入れる」というイメージで表現するのであれば、図2-2のような感じになる。
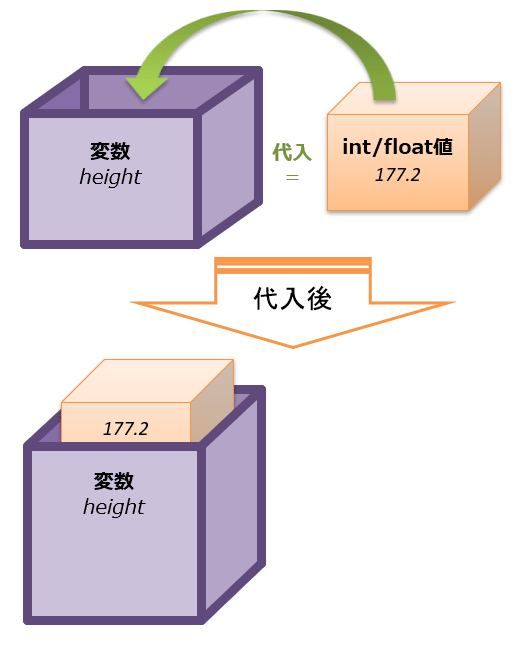
本連載においては、「変数への値の代入」といえば、この図を頭の中でイメージしてほしい。
ちなみに、繰り返しになるが、変数に値が代入されたものは「オブジェクト」である点に注意してほしい。しつこいようだが、変数とはあくまで何でも入れられる箱であり、値とはその箱に入れるデータなどである。
Pythonにおける「単一のデータ」の表現
それでは、Pythonで、変数に値を代入するにはどうすればよいだろうか? 変数の名前はheightで、値は177.2(数値型、厳密にはfloat型の浮動小数点数値)とする。
Python言語では、代入は=で表現でき、その左辺に変数を、右辺に値を記述する。つまり「変数への値の代入」は、
変数 = 値
という文法で記述できる(※=前後の半角スペースはあってもなくてもよいが、本連載では見やすさのためにスペースを入れている)。
この文法を使って、「単一のデータ」(=Python言語内ではオブジェクトとなる)は、リスト1-1のように表現できる。
height = 177.2
print(height) # 177.2と出力される
ここまでは難しくないだろう。もしprint(height)の意味が分からない場合は、下記の「【コラム】print関数による出力」参照してほしい。
また、リスト1-1の最後の1行は、print(height)ではなく、単にheightのように記述しても、同じように出力される。この書き方の違いについては、下記の「【コラム】インタラクティブシェルにおけるオブジェクト評価の自動出力」を参照してほしい。以下、本連載では、インタラクティブシェルを使用する前提で、heightのように単に変数名だけを記述すれば問題ない場合は、print()関数を使わずに変数名だけで短く記述する。インタラクティブシェル以外を使うことは推奨しないが、使う場合は、各自でprint()関数に置き換えてほしい。
【コラム】print関数による出力
print(height)の意味は、heightオブジェクトの中の値を出力する(=printする: 値の内容を見やすいように整形して書き出す)、ということである。出力先は、実行環境や実行方法により異なる。本稿の冒頭で示した実行環境「Google Colab」であれば、コードセルの下に表示されることになる(図2-3)。

print(変数名)という書き方の文(statement)は、「関数(function)の呼び出し」と呼ばれる、Python言語の基本機能である。
print()関数は、Python言語に最初から標準で用意されている組み込み関数(Built-in functions)の一つである。
【コラム】インタラクティブシェルにおけるオブジェクト評価の自動出力
Google Colabのようなインタラクティブシェルを用いた実行環境の場合、print()関数を使わずに、リスト1-2のように、変数名(厳密には式:expression)だけの文を書いてもprint()関数と同じような出力が自動的に表示される。
height # 177.2と出力される
しかし、この自動表示とprint()関数の出力はまったく同じとは限らない。自動表示の場合は、あくまで式の評価結果(=開発やデバッグのために得る情報)が出力されているのに対し、print()関数の場合は、人が見るために綺麗に整形された情報が出力される、という違いがある。
例えばリスト1-3は、次回説明するNumPyによりarray型の値を作成して、変数array2dに代入した後、そのオブジェクトの内容を出力している例だ。print()関数と自動表示の出力を見比べると、自動表示の方には「array()」という、(array2dオブジェクトの中にある値の)型の名前が表示されている。開発時やデバッグ時には、このように「array()」などとより多くの情報が表示された方がありがたいケースも多々ある。
import numpy as np
array2d = np.array([ [ 165.5, 58.4 ],
[ 177.2, 67.8 ],
[ 183.2, 83.7 ] ])
print(array2d) # [[165.5 58.4]
# [177.2 67.8]
# [183.2 83.7]]
array2d # array([[165.5, 58.4],
# [177.2, 67.8],
# [183.2, 83.7]])
いずれにしても、場合によっては出力が完全に同じならないことには注意してほしい。
余談になるが、オブジェクトの評価内容は組み込み関数のrepr()関数により得られるので、それをprint()関数で出力すると(要するにprint(repr(array2d))のように記述すると)、自動表示の出力と同じになる。
自動表示を使う場合、もう一つ注意点がある。
Google ColabなどのJupyter Notebook環境では、セルの最後に変数名を書くと、その変数のオブジェクトが評価されて、その評価結果が出力されるわけだが、あくまで評価&出力されるのは、最後の変数名だけということだ。例えば、2つ以上など複数の変数名を1行ごとに書いても、最後の1つしか出力されない。
複数のオブジェクト内容を出力したい場合には、print()関数を使うか、コードセルを複数に分けて記述する必要がある。もしくは最後の行で、
height, weight
のように、複数の変数名をカンマ(,)で区切って書いてもよい。
自動表示の方が、当然、print()関数よりもタイプ数が少なくなり、見やすさも増すため、Jupyter Notebook環境では、好まれて比較的よく使われている(という印象を筆者は持っている)。本連載でも、基本的には自動表示で、print()関数を使うべきところではprint()関数で記述していく。
Pythonにおける「複数(1次元)のデータ」の表現
以上で単一のデータの表現方法は問題なく理解できただろう。次に「複数(1次元)」の場合は、どうデータを表現すればよいだろうか。
先ほどはクラス全員(3人)の身長と体重の個々の数値をすべて箇条書きで書き出した。ここでは、全員の身長と、全員の体重という、測定項目別にデータ群を抽出することを考えてみよう。
先ほども説明したように、表データでは、横に並ぶのが「列」である。なお、[名前]列にある「花」「太郎」「次郎」は、先ほども述べたように数値ではなく、各行の見出しなので、データ表現からは除外する。

すると、図3-1で赤色の円で示したように、
[身長]列の、
- 花(hana): 身長(height)=165.5cm
- 太郎(taro):身長(height)=177.2cm
- 次郎(jiro):身長(height)=183.2cm
[体重]列の、
- 花(hana): 体重(weight)=58.4kg
- 太郎(taro): 体重(weight)=67.8kg
- 次郎(jiro): 体重(weight)=83.7kg
という2つのデータ群を抽出できる。これらが、単一のデータを一列に並べてまとめた一次元のデータとなる。
では、このような一次元のデータをPythonで表現するには、どうすればよいだろうか? ここでは例として、「3人全員の身長(165.5cm、177.2cm、183.2cm)」をPythonで表現してみよう。
先ほどの例に倣えば、リスト2-1のように、人ごとに3つの変数を使って表現することも不可能ではない。
hana_height = 165.5
taro_height = 177.2
jiro_height = 183.2
hana_height, taro_height, jiro_height # (165.5, 177.2, 183.2)
しかしこれだと、3人程度のうちは問題ないが、データ数が1000人や1万人となった場合に問題となる。とても手書きできる量ではないからだ。
そこで、複数の値を一列にまとめて、1つのデータオブジェクトとして扱うために使われるのが、リスト(list、他のプログラミング言語にある配列:arrayと同じもの)という型である。つまり、「一次元のデータ」は、Pythonでは「リスト」型の値(リスト値)で記述するということだ。リスト2-2が、実際にリストを使ってデータを表現したコード例だ。
heights = [ 165.5, 177.2, 183.2 ]
heights # [165.5, 177.2, 183.2]
リスト2-1に比べると、リスト2-2はすっきりとシンプルなコードになっているのが分かる(※なお、hana/taro/jiroなどの名前は、AIの計算対象の数値ではなく不要なので、データに含めていないことも、コードがすっきりした理由の一つだ)。
このコードの挙動は、図3-2のようにイメージしてほしい。

単に「リスト」と言えば、このように1列に並ぶ1次元リスト(1D list)を意味する。さらに、リストの中にリストを入れていき、その入れ子構造の階層を深めていくことで、2次元リスト(2D list)、3次元リスト(3D list)、4次元リスト(4D list)、……というデータも作れるわけである。具体的に見ていこう。
Pythonにおける「複数(2次元)のデータ」の表現
では、2次元リストはどうやって表現すればよいのか。
例として、これまでと同じクラス全員(3人)の身長と体重のデータを扱う。ここでは、全員の身長と体重をひとまとめのデータ群として抽出することを考えてみよう。
これは、表データそのものとなる(※ただし、先ほどと同様、[名前]列はAIの計算対象の数値ではなく不要なので考慮しないものとする)。

具体的には、図4-1で赤色の円で示したように、
- 花(hana): 身長(height)=165.5cm、体重(weight)=58.4kg
- 太郎(taro):身長(height)=177.2cm、体重(weight)=67.8kg
- 次郎(jiro):身長(height)=183.2cm、体重(weight)=83.7kg
という1つのデータ群を抽出できる。縦に並ぶ人別の「行」と、横に並ぶ測定項目別の「列」によって、表形式のデータが形成されている。これをPythonで表現すると、リスト3のようなコードになる。
people = [ [ 165.5, 58.4 ],
[ 177.2, 67.8 ],
[ 183.2, 83.7 ] ]
people # [[165.5, 58.4], [177.2, 67.8], [183.2, 83.7]]
このコードの挙動は、図4-2のようにイメージするとよい。

リスト3のコードは一見すると、複雑で難しそうに見えるかもしれない。しかし、前掲の図4-1の表データやその下に記載した箇条書きとまったく同じ形状で数字が並んでいることに気付くと、直感的な表現であることが分かる。
コードの構造をひも解いていこう。まず、[ 165.5, 58.4 ]と[ 177.2, 67.8 ]と[ 183.2 83.7 ]を個別に見ると、先ほどの横1列に並んでいた1次元リストそのものである。つまり、
[ <身長の値>, <体重の値> ]
という、列の1次元リストが、3つあると見なせる。
これら3つの1次元リストを、順に<花のデータ>と<太郎のデータ>と<次朗のデータ>という仮の名前で呼ぶとするなら、リスト全体は、
[ <花のデータ>,
<太郎のデータ>,
<次朗のデータ> ]
というコードになり、リストの中身が改行されて縦に並んでいる状態だと分かる。よって、,の後の改行を消すと、
[ <花のデータ>, <太郎のデータ>, <次朗のデータ> ]
という、行の1次元リストになっていることに気付く。
要するに、2次元リストは、まず縦の「行」に対応する1次元リストを作成し、その各値部分に、さらに別の1次元リスト値を入れ込んだ構造になっているというわけである(図4-3)。

入れ子構造が複雑な記載方法であることは間違いないので、初めてプログラミングを学ぶという読者にとっては「分かるようで分からない」ということもあるかもしれない。ちょっと自信がないという場合は、上記の表でも何でもいいので、自分で2次元リストのコードを表データだけを見ながら書いてみることである。ポイントは、縦で行の1次元リストを作って、その各行に対して横で列の1次元リストを記載することである。
【コラム】表形式データとデータベースについて
すでに述べたように、機械学習やディープラーニングで使う「データ」は、表形式で作成することが基本である。そして、この表データは、さまざまな情報・データを保存・管理・検索するためのデータベース(Database)というシステム(=アプリケーションの一種)と非常に親和性が高い。
データベースの基本機能は、表の英訳であるテーブル(table)と、テーブルを構成する列(=カラム、コラム:column)、行(=row:ロー、「記録」を意味するレコード:recordとも呼ばれる)の管理である(図4-4)。

『初めてのニューラルネットワーク&ディープラーニング実装(TensorFlow 2+Keras(tf.keras)入門)』ではデータベースは使わないが、AIを本格的に実践する中で必要となることが多いため、データベースも避けて通れない学習対象の一つではある。詳細な説明は割愛するが、とりあえずは、データベースには、MySQL、PostgreSQL、SQL Serverといった製品があり、これらを自前のパソコン上(=オンプレミス)で動かす場合と、Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Platform(GCP)といったクラウドで動かす場合、さらにBigQueryなどのクラウド専用のものを使う場合がある、と概要だけお伝えしておこう。
Pythonにおける「複数(多次元)のデータ」の表現
2次元リストから、3次元リストや4次元リストと次元数が増えていくということは、この入れ子の階層が深くなっていくということだ。例えばリスト4は、3次元リスト値を変数に代入する例である。2次元リストが、あるクラスの生徒の身長と体重を表形式で管理しているとするなら、3次元のリストはある学年(または学校全体)の生徒の身長と体重を(「2次元リストのリスト」として)まとめたものと考えることができる。
list3d = [
[ [ 165.5, 58.4 ], [ 177.2, 67.8 ], [ 183.2, 83.7 ] ],
[ [ 155.5, 48.4 ], [ 167.2, 57.8 ], [ 173.2, 73.7 ] ],
[ [ 145.5, 38.4 ], [ 157.2, 47.8 ], [ 163.2, 63.7 ] ]
]
list3d # [[[165.5, 58.4], [177.2, 67.8], [183.2, 83.7]],
# [[155.5, 48.4], [167.2, 57.8], [173.2, 73.7]],
# [[145.5, 38.4], [157.2, 47.8], [163.2, 63.7]]]
これをイメージで表現すると、図5-1のようになる。

外側のカッコ[]が1つ増えている。なお、3次元は奥行きが追加されるので2Dの図版に起こすのが表現上難しくなってくるため、構造図は(隠れている部分も多くて)見づらいかもしれないがご了承いただきたい。
1次元、2次元、3次元と、1つずつ次元を追加してきた入れ子構造の応用とはいえ、かなり複雑なコードになってきた。筆者もカッコ[]の多さで頭が混乱してくる感じではある(※4次元以上はさらに複雑で、図解表現も難しいので、説明は3次元までとする)。
ただし、AIのデータで3次元以上の複雑なデータを扱うことはまれなので、安心してほしい。ほとんどの場合、2次元の表データを作成して使用する。例えば『初めてのニューラルネットワーク&ディープラーニング実装(TensorFlow 2+Keras(tf.keras)入門)』では、「座標点(x1:X軸の数値、x2:Y軸の数値)+label:正解ラベル」という列が500行ほどある、表データを使う。リンク先「点座標のサンプルデータ」を開くと、図5-2のように、確かに2次元の表データとなっていることが分かる。

ちなみに他のプログラミング言語(例えばJavaScriptなど)でも、表データの作成方法は、このような入れ子構造で作るので、本稿の内容を理解しておけば、多くの場面で応用が利くだろう。
つづく
Pythonのデータ構造の説明は以上とする。続いて次回は、ライブラリ「NumPy」を活用したAIプログラムの基本的なデータ構造を見ていこう。
Copyright© Digital Advantage Corp. All Rights Reserved.