[Python入門]文字列の操作:Python入門(2/4 ページ)
Pythonの文字列はさまざまに操作できる。文字数の取得、要素の取り出し、文字列に特定の文字列が含まれているかの判定、文字列の置換などを紹介する。
文字列の結合
文字列と文字列は「結合」して、1つの文字列にできる。最も簡単な方法は文字列リテラルを並べて書くことだ。以下に例を示す。
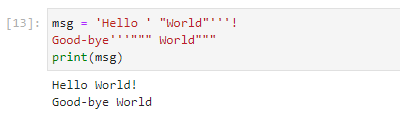
msg = 'Hello ' "World"'''!
Good-bye'''""" World"""
print(msg)
文字列リテラルの間には空白文字を入れてもよい。また、見れば分かる通り、文字列リテラルの記述方法が異なっていても構わない(上の例ではシングルクオート、ダブルクオート、トリプルクオートの表記法を使って記述した文字列リテラルが結合されている)。この方法では、Pythonがプログラムを実行するのに先立って、並べられた文字列リテラルを1つの文字列に結合してくれる。実行結果を以下に示す。
この方法は、文字列リテラル同士をまとめることはできるが、変数に代入された文字列を結合することはできない。例えば、以下のコードについて見てみよう。
world = 'World'
msg = 'Hello ' world
print(msg)
これを実行すると次のようにエラーとなる。

このような場合には、「+」演算子を使って、文字列を結合する。
- 文字列 + 文字列
演算結果:2つの文字列を結合したもの
以下に例を示す。
world = 'World'
msg = 'Hello ' + world
print(msg)
実行結果を以下に示す。
前回でも述べたが、文字列と数値を結合(加算)することはできない。
result = '1' + 1
print(result)
これを実行すると、次のようなエラーとなる(PythonのバージョンによってはTypeErrorのメッセージが「must be str, not int」となる)。

このようなときには、「文字列を数値に変換して、数値同士を加算する」のか、「数値を文字列に変換して、文字列を結合する」のかをプログラマーが明示的に指定する必要がある。例えば、前者であれば、次のようなコードになる(実行結果は省略)。
some_value = '1'
result = int(some_value) + 1
print(result)
Pythonの哲学には「Explicit is better than implicit」(暗黙的に何かをするよりも明示的にする方がよい)というものがある。この場合は、「明示的に数値を文字列に変換する」か「明示的に文字列を数値に変換する」ことが推奨されているということだ。そうすることで、「プログラマーが何をしようとしているのか」がコードに明確に表れ、自分が(または別の人が)後からコードを見たときに、コードの意図を理解しやすくなる。
文字列の乗算
今見たように、Pythonでは文字列同士に対する「+」演算はそれらを結合する。似た振る舞いをするものとしては、「*」演算子がある。
- 「文字列 * 整数値」または「整数値 * 文字列」
演算結果:「文字列」を「整数値」回だけ繰り返したもの
ただし、こちらは「文字列と数値」を演算の対象(被演算子)とする。つまり、「文字列 * 整数値」または「整数値 * 文字列」という書き方になる(「文字列 * 文字列」という書き方はできない)。
この演算子は文字列を、整数値で示される回数だけ繰り返したものを演算結果とする。「'a' * 5」なら「'aaaaa'」が得られるということだ。以下に例を示す。
文字列に特定の文字列が含まれているかを調べる:in演算子、find/rfind/index/rindexメソッド
文字列中に、特定の文字列が含まれているかを調べるには「in」演算子や文字列が持つfind/rfind/index/rindexメソッドが使える。まずはin演算子から見てみよう。
in演算子
in演算子は「比較演算子」と呼ばれる演算子の1つだ(「何かを比較したり何かを調べたり」するための演算子)。
- 検索したい文字列 in 検索対象となる文字列
演算結果:「検索対象となる文字列」の中に「検索したい文字列」が含まれていればTrue、そうでなければFalse
その演算結果はTrueかFalseのいずれかとなる。「True」は「その演算子で調べている条件が成立した」ことを意味する値、「False」は「その演算子で調べている条件が成立しなかった」ことを意味する値だ(これらについては、第9回で詳しく取り上げる)。in演算子なら「文字列に特定の文字列が含まれていた」ならその結果はTrueに、そうでなければFalseになるということだ。
実際には、「あるかどうかを調べたいもの in 対象の文字列」という書き方をする。例えば、住所に「Setagaya」が含まれているかどうかを調べるといったときに使える。「'Setagaya' in 'Sakura-Jousui, Setagaya-Ku, Tokyo, Japan'」のような感じだ。これを実際にセルに入力して、実行してみよう。
「Sakura-Jousui, Setagaya-Ku, Tokyo, Japan」(東京都世田谷区桜上水)には「Setagaya」が含まれているので、「in演算子で調べようとした条件が成立」している。そのため、上では「True」が結果として表示されている。次に「Yoyogi, Shibuya-Ku, Tokyo, Japan」(東京都渋谷区代々木)に対して「Setagaya」が含まれているかを調べてみよう(自明ではあるが)。
この場合はもちろん、含まれていないので「False」が演算の結果となる。
in演算子は「含まれているか」を調べるものだが、「含まれていないか」を調べることもできる。これには「not in」演算子を使用する。これは「ないことを確認したいもの not in 対象文字列」のように書く。上の例をnot in演算子で調べてみよう。

結果が逆になっていることが分かるはずだ。
なお、実際には、この演算子をこのように単独で使うのではなく、if文などと組み合わせて「特定の条件が成立したときと成立しなかったときで、実行する処理を別のものにする」ような使い方をする。if文については第9回で詳しく見るが、以下に簡単に例を示しておく(分かりやすく、日本語の住所にした)。
address = '東京都世田谷区桜上水'
ward = '世田谷区'
if ward in address:
print(address + 'は' + ward + 'にあります')
else:
print(address + 'は' + ward + 'にはありません')
if文は指定した条件を基に処理を分岐させるものだ。上の例では、変数wardの値が変数addressの値に含まれているかを調べ、そうであればすぐ下の行を、そうでなければ「else:」の下の行が実行される。ここでは「'世田谷区'が'東京都世田谷区桜上水'にあるか」を調べている。結果は次のようになる。

文字列のfind/rfindメソッド
文字列中で、指定した文字列がどこにあるかまでを調べるにはfind/rfindメソッドおよびindex/rindexメソッドが使える。「メソッド」とは「オブジェクトが自分自身を対象として何らかの処理を行うための操作」のこと。「自分自身を操作対象とした関数のようなもの」ともいえる。オブジェクトとメソッドの関係については第28回「クラスの基礎知識」や第29回「クラス変数/クラスメソッド/スタティックメソッド」などを参照されたい。
簡単には、メソッドとは「オブジェクト.メソッド名(引数)」のようにして実行する(呼び出す)ことで、「オブジェクト.メソッド(引数)」に書いた「オブジェクト」を対象に何かの処理を行うものだと考えておこう。findメソッドなら「元の文字列.find(元の文字列から探したい文字列)」などとなる。こうすることで、メソッドの呼び出しに使った「元の文字列」にfindメソッドの引数に渡した「元の文字列から探したい文字列」が含まれているかどうかを調べられる。
- 元の文字列.find(sub)
引数:sub 元の文字列内に含まれているかを検索したい文字列
戻り値:引数subに指定した文字列を、元の文字列から探して、あればその最小のインデックスを、なければ-1を返す - 元の文字列.rfind(sub)
引数:sub 元の文字列内に含まれているかを検索したい文字列
戻り値:引数subに指定した文字列を、元の文字列から探して、あればその最大のインデックスを、なければ-1を返す - 元の文字列.index(sub)
引数:sub 元の文字列内に含まれているかを検索したい文字列
戻り値:引数subに指定した文字列を、元の文字列から探して、あればその最小のインデックスを、なければ例外(エラー)を発生させる - 元の文字列.rindex(sub)
引数:sub 元の文字列内に含まれているかを検索したい文字列
戻り値:引数subに指定した文字列を、元の文字列から探して、あればその最大のインデックスを、なければ例外(エラー)を発生させる
find/rfindメソッドとindex/rindexメソッドの違いは、前者は文字列が見つからなければ-1を返し、後者は例外(エラー)を発生させる点にある。また、find/indexメソッドとrfind/rindexメソッドの違いは、指定した文字列が複数あるときに前者は最初に見つかったもののインデックスを、後者は最後に見つかったもののインデックスを返す点にある。
-1を返すバージョンと例外となるバージョンの使い分けは、場合による。
「文字列内に特定の文字列が含まれている」ことが期待される状態で、その文字列がないときには、プログラムの実行に多大な影響があることも考えられる。そうした場合には、例外を発生させるものを使う方がよい。
「文字列中に特定の文字列が含まれていれば、それに応じた処理を追加したい」程度であれば-1を返すバージョンを使う方がよい。
そういった使い分けが考えられる。
先ほど紹介したin演算子は文字列中に特定の文字列が含まれているかだけが分かればよいときに使う。一方、今述べた4つのメソッドはその位置まで調べ(て、その位置に応じた処理をす)るときに使う。
なお、上の箇条書きでは引数の名前が「sub」になっているが、これは「部分文字列」を意味する「substring」を省略して表記したものだ。ここで紹介している4つのメソッドは「元の文字列の中に特定の文字列が含まれているかを調べるもの」であり、見つかった場合、引数に指定した文字列は「元の文字列の一部分を構成する文字列」ということになる。こうした文字列のことを「部分文字列」(substring)という。
以下に例を示す。ここでは文字列'find, rfind, index, rindex'からfind/rfindメソッドでは文字列'index'を、index/rindexメソッドでは文字列'find'を探してみよう。それから元の文字列には含まれない文字列'foo'も探してみる。
sample_str = 'find, rfind, index, rindex'
print(sample_str.find('index'))
print(sample_str.rfind('index'))
print(sample_str.find('foo'))
print(sample_str.index('find'))
print(sample_str.rindex('find'))
print(sample_str.index('foo'))
実行結果を以下に示す。

最初の2つのprint関数呼び出しでは、find/rfindメソッドを使って「index」という文字列を検索している。元の文字列は「find, rfind, index, rindex」なので、前者は最初の「index」の「i」がある場所のインデックス(13)を、後者は2つ目の「index」(rindex)の「i」がある場所のインデックス(21)を返している。index/rindexメソッドも同様だ。
また、3番目と最後のメソッド呼び出しでは、存在しない文字列'foo'を検索しているが、3番目のfindメソッド呼び出しは-1を返し、最後のindexメソッド呼び出しでは例外(エラー)が発生しているところにも注意しよう。
これらのメソッドでは、元の文字列のどこからどこまでの範囲を探すかも指定可能だ。その場合は「'文字列'.find('検索文字列', 検索開始位置のインデックス, 検索終了位置のインデックス+1)」のように指定する(例:「'abcdefg'.find('ef', 3, 6)」。このとき、検索範囲は'abcdefg'の3〜5番目の要素となることに注意。これはスライスの指定と同様だ)。
Copyright© Digital Advantage Corp. All Rights Reserved.