第3回 ディープラーニング最速入門 ― 仕組み理解×初実装(後編):TensorFlow 2+Keras(tf.keras)入門(3/3 ページ)
いよいよ、ディープラーニングの学習部分を解説。ニューラルネットワーク(NN)はどうやって学習するのか、Pythonとライブラリではどのように実装すればよいのか、をできるだけ簡潔に説明する。
(7)評価: 損失のグラフ
それでは、学習結果を評価してみよう。
Playgroundによる図解
既に何度か説明で触れているが、あらためて説明する。Playgroundを開いて、右側にある(7)評価の[Train loss](=訓練データにおける損失)/[Validation loss](=精度検証データにおける損失)と、その右にあるグラフを参照してほしい(図7-1)。グラフの下には最終的な精度(正解率:acc=accuracy)も表示されている。
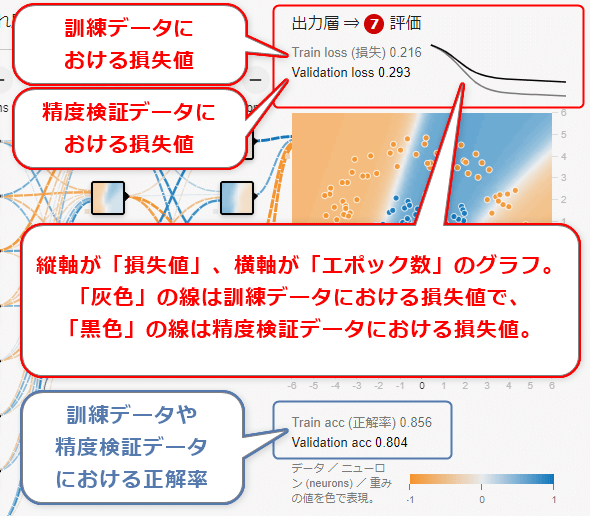
説明しなくても理解できると思うが、念のため、説明する。訓練データにより学習を行った結果の損失値が、灰色の文字で(この例では0.216と)表示され、その右に灰色の線がグラフ描画されている。エポック数が増えるに従って、損失値が低くなり、0に向かって収束していっているのが分かる。
一方、精度検証データを学習済みモデルに入力して計測(※学習はしておらず精度検証用の計測のみ)した損失値が、黒色の文字で(この例では0.293と)表示され、その右に黒色の線がグラフ描画されている。こちらも、訓練データほどではないが、0に向かって収束していっているのが分かる。
どちらも0.001などと損失ができるだけ小さくなるまで学習を続けた方がいいが、途中で損失値のグラフが横ばいになり、それ以上、損失値が減らなくなってくる。こうなれば学習を終えてよい。
Playgroundでは目視でグラフを確認して止められるが、コードの場合は指定したエポック数まで学習が継続されてしまう。「損失値がほとんど変わらない状態になったら、早めに学習を打ち切りたい」というニーズはあるだろう。このようなニーズに応える、早期終了(Early Stopping、早期停止)と呼ばれる機能が、Kerasには搭載されている。早期終了は、Playgroundには実装していないので、Playgroundでは使えない。よって後述のコード実装で、早期終了の使い方を説明する。
Pythonコードでの実装例
それでは、損失値の表示や、その推移グラフの描画を、コード実装により実現してみよう。
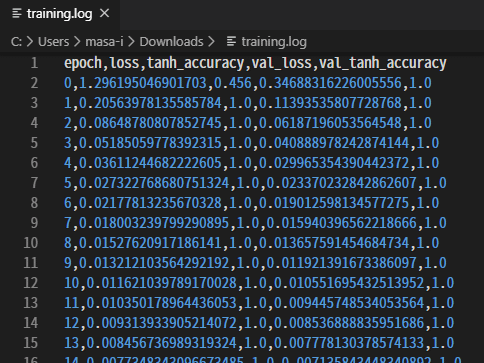
損失の値については、実は先ほどのリスト6-2やリスト6-3のコードを実行すると、fitメソッドの第6引数verbose=1の指定により、自動的に表示される。図7-2がその表示例である。

エポックが1回完了するごとに1行ずつログが標準出力される。エポック数100の最後である100番目の行を見ると、[loss]は0.00066360(=6.6360e-04、「e-04」は指数表記で1/10の4乗を意味する)となっており、訓練データにおける損失値はかなり小さい。
ついでに正解率も見てみよう。先ほどtanh_accuracyという精度(正解率)を測る評価指標を指定したので、[tanh_accuracy]には正解率が表示されている。この例では、1.0000と100%正解している。
この例では、訓練データにおける学習は成功している。念のため、精度検証データにおける損失と正解率も見ておこう。[val_loss]が精度検証データにおける損失値で、[val_tanh_accuracy]が正解率である。こちらも問題ない値となっていることが確認できる。
数字ではなく、グラフで視覚的に学習結果を把握したい場合は、fitメソッドの戻り値で返されたHistoryオブジェクト(本稿の例ではhist)のログデータを使って、グラフ描画ライブラリ「Matplotlib」でグラフを描画するとよい。コードの書き方の説明は割愛するが、リスト7-1のようなコードを書けばよい。
import matplotlib.pyplot as plt
# 学習結果(損失)のグラフを描画
train_loss = hist.history['loss']
valid_loss = hist.history['val_loss']
epochs = len(train_loss)
plt.plot(range(epochs), train_loss, marker='.', label='loss (Training data)')
plt.plot(range(epochs), valid_loss, marker='.', label='loss (validation data)')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
このコードを実行すると、図7-3のように描画される。

正解率のグラフも同様に描画できるが、説明を割愛する。
早期終了とCSVログ出力
上記のグラフでは、最後まで損失の減少が続いているので必要ないが、損失の減少が停滞してきたらそれ以上、学習する必要はない。このようなムダな学習を省くために、前述の通り、早期終了機能が活用できる。
Kerasでは、早期終了は「コールバック」という機能で実現できる。コールバック(Callback)とは、学習中(=トレーニング中)のモデル内部から、何らかの機能を呼び出してもらう機構である。早期終了の場合は、(tf.keras.callbacksモジュール階層の)EarlyStoppingクラスのインスタンスを、fitメソッドの引数callbacksに、リスト値として指定すればよい。
また、コールバックには、他にも機能があり、例えば実行ログをCSVファイルとして保存したりすることもできる。そのCSVロガーは、(tf.keras.callbacksモジュール階層の)CSVLoggerクラスのインスタンスを、同様に引数callbacksに指定すればよい。
この2つのコールバックを指定して学習するコードはリスト7-2のようになる。
# 早期終了
es = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=2)
# CSVロガー
csv_logger = tf.keras.callbacks.CSVLogger('training.log')
# 学習する
hist = model.fit(x=X_train, # 訓練用データ
y=y_train, # 訓練用ラベル
validation_data=(X_valid, y_valid), # 精度検証用
batch_size=BATCH_SIZE, # バッチサイズ
epochs=EPOCHS, # エポック数
verbose=1, # 実行状況表示
callbacks=[es, csv_logger]) # コールバック
EarlyStoppingクラスのコンストラクターでは、引数monitorに監視対象の損失(この例ではval_loss=精度検証データの損失)を指定し、引数patienceには何エポック連続で数値に減少が見られないと学習を打ち切るかの数値(この例では2回)を指定する。ちなみに、今回のサンプルで実行してみたが、学習は早期停止しなかった。
CSVLoggerクラスのコンストラクターでは、ファイル名(この例では「training.log」)を引数に指定する。実行後に生成されたファイル内容を確認してみたところ、図7-4のCSVテキストデータが出力されていた。
(8)テスト: 未知データで推論と評価
さて、ここまでで無事にモデルが学習できて、かなり小さい損失値で、分類の場合は十分な正解率が出せるようになったとしよう。「それなら、実運用に進んでよいか?」というと、「もう一段、テストをした方がよい」とされている。学習時に使った訓練データや、精度検証に用いた精度検証データには、何らかのバイアスがかかっている可能性が否定できないからだ。
Playgroundによる図解
Playgroundでは、右側にある出力層のグラフ上の任意の場所をクリックすることで、その地点のテストが行えるようになっている(図8-1)。
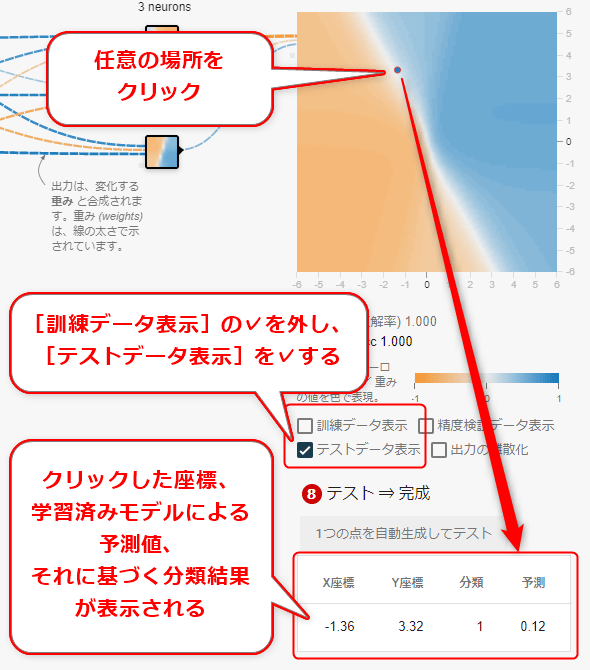
この例では座標(-1.36、3.32)をクリックしている。背景色が白い所をクリックしたので、予測値も0.12と0.0に近い数値となっている。分類問題では、0.0未満がオレンジ色(=-1)で、0.0以上が青色(=1)にと、強引に振り分ける(=離散化:discretizeする)仕様なので、[分類]は1(=青色)となっている。
ちなみに、Playgroundには[出力の離散化]というチェックボックスがあるが、ここにチェックを入れると、強引に-1か1に振り分けられるため、背景描画から白色の部分はなくなる。
Pythonコードでの実装例
ここまで、とても長く感じたかもしれないが、ついに最後のコードである。そのコードで、テストデータを新たに生成して入力として使い、学習済みモデルに結果出力(=予測:predict)させたり、テストデータでの精度(=「汎化性能:Generalization performance」と呼ぶ)に問題がないか評価(evaluate)したりしてみよう。
コードは、リスト8-1のようになる。なお、データの生成方法は、リスト6-1に掲載したものと同じなので、説明を割愛する。
import plygdata as pg
import numpy as np
# 未知のテストデータを生成
PROBLEM_DATA_TYPE = pg.DatasetType.ClassifyTwoGaussData
TEST_DATA_RATIO = 1.0 # データの何%を訓練【Training】用に? (残りは精度検証【Validation】用) : 100%
DATA_NOISE = 0.0 # ノイズ: 0%
data_list = pg.generate_data(PROBLEM_DATA_TYPE, DATA_NOISE)
X_test, y_test, _, _ = pg.split_data(data_list, training_size=TEST_DATA_RATIO)
# 学習済みモデルを使って推論
result_proba = model.predict(X_test)
result_class = np.frompyfunc(lambda x: 1 if x >= 0.0 else -1, 1, 1)(result_proba) # 離散化
# それぞれ5件ずつ出力
print('proba:'); print(result_proba[:5]) # 予測
print('class:'); print(result_class[:5]) # 分類
# 未知のテストデータで学習済みモデルの汎化性能を評価
score = model.evaluate(X_test, y_test)
print('test loss:', score[0]) # 損失
print('test acc:', score[1]) # 正解率
学習済みモデルによる推論/予測は、modelオブジェクトのpredictメソッドで行える。このメソッドの引数には、多次元配列値のテストデータ(この例では)を渡せばよい。戻り値として、出力結果(つまり予測値)が多次元配列値で返される。
また、最終的な損失は、modelオブジェクトのevaluateメソッドで取得できる。このメソッドの引数には、多次元配列のテストデータと教師ラベルを渡せばよい。戻り値として、損失値が返される。本稿のように評価指標も指定した場合は、その評価(今回は正解率)も合わせて、リスト値で返される。
実際にリスト8-1を実行した結果、図8-2のようになった。
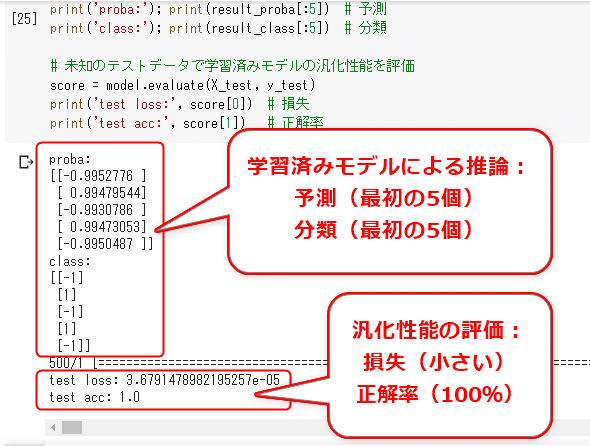
図中の説明を読めば分かるように、推論/予測が正常に実行できており、汎化性能も十分あるという結果が出た。
まとめ
以上でニューラルネットワークの基本を一通り学んだことになる。今回の知識を武器に、ディープラーニングへの理解を深めていって、ゆくゆくは機械学習全般に強くなっていってほしい。
最後におまけとして、Colaboratory上のサンプル(tf2-keras-neuralnetwork.ipynb)には、ニューラルネットワーク内の重みやバイアスを調べるためのサンプルコードを追記しておいた。気になる人はぜひ、リンク先を開いてコード内容を確かめてみてほしい。
Copyright© Digital Advantage Corp. All Rights Reserved.