機械学習やディープラーニングってどんなもの?:作って試そう! ディープラーニング工作室(1/2 ページ)
実際にコードを書きながら「人工知能/機械学習/ディープラーニング」を学んでいこう。まずはその概要とそのために便利に使えるGoogle Colabを紹介。
人工知能? 機械学習? ディープラーニング?
このところ、ニュースなどで「人工知能(AI)」「機械学習」「ディープラーニング」という言葉を聞かない日はありません。これらの用語には「人が作った知能」「人の脳神経を模したヤツね」「ニューラルネットワークみたいな?」などといったイメージがあると思いますが、具体的にはこうした技術を使ってどんなことができるのでしょうか。パッと思い付くのは次のようなことです。
- 画像認識/画像合成
- 音声認識/音声合成
- 自然言語処理(翻訳、会話など)
- ゲーム(囲碁、将棋、TVゲームなど)
- 推測(株価、レコメンドなど)
- 制御(自動運転、ロボットなど)
これらは「何かを基に何らかの判断を行う」こととまとめられます。例えば、「桜の花を見て、それを桜と認識する」「誰かから話しかけられて、その意味を理解する」「左カーブに合わせて、ステアリングを操作する」といったことです。
人が行うのであれば、これらは「知的な活動」とでも呼べるでしょう。そうした知的な活動を人工的な存在であるソフトウェア(と、そこに何らかの形で接続されたハードウェア、そこから取得できるデータなど)を使って模倣するものが人工知能だといえます。
人工知能は1950年代にその概念が登場し、その後、紆余(うよ)曲折を経る中で、春の時代や冬の時代を何度かくぐり抜けて現在に至っています。そして、現在ではコンピューターの性能向上やソフトウェア/理論の発展に後押しされ、ある程度は現実的なものとして社会に受け入れられるようになりました(現在、広く使われている人工知能は、特定の問題を解決可能な「弱いAI」と呼ばれるものです)。
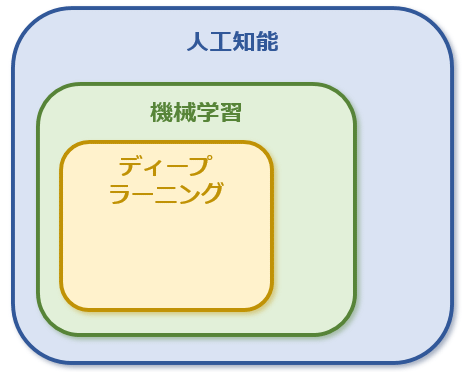
「機械学習」(Machine Learning、ML)とは、今述べた人工知能を実現するための手段の一つです。その名前から分かる通り、「機械」(コンピューター)に「学習」をさせることで、知性の獲得を目指します。このときには、関連性を持つ大量のデータを機械に入力し、それらから今解決しようとしている問題を解くために必要な何らかのパターンやルールのようなものを見つけ出します(知性の獲得)。人が何かを身に付けようとしたら、何度も同じことを繰り返して、身体の動かし方を体得したり、「ネコの特徴は○○に現れているのだな」と理解したり、「この部品はそろそろ壊れるかもしれないな」と推測したりと、自分が身に付けたい何かに関することを(知らず知らずのうちに、あるいは意識的に)学んでいくことに似ています。
機械に学習をさせるとして、その方法にもさまざまなものがあります。その一つが、人間の脳を模倣した「ニューラルネットワーク」です。「ディープラーニング」とは、このニューラルネットワークを進化させたものです。これについては後で少し詳しく見てみます。
ここまでの話を簡単にまとめましょう。より詳しい説明は本フォーラムの連載記事「機械学習&ディープラーニング入門(概要編)」などを参考にしてください。
- 人工知能:人間が日々行っている知的な活動を人工的に実現すること
- 機械学習:人工知能の種類の一つで、大量のデータを基にコンピューターに「学習」をさせることで、人の知的活動を実現すること
- ディープラーニング:機械学習を行う方法の一つで「ニューラルネットワーク」と呼ばれる手法を強力にしたもの
機械学習で使われる他の手法については、機会があれば、連載の中で取り上げる予定です。
ニューラルネットワーク/ディープラーニングとは
本連載で主に取り上げるのは「ニューラルネットワーク」や「ディープラーニング」と呼ばれる手法です。一般に、ニューラルネットワークは入力層、隠れ層、出力層の3つの層で構成されますが、ディープラーニングで使われるディープニューラルネットワークでは、隠れ層を複数にする(隠れ層を深く=ディープにする)ことで入力に対する出力の精度をより向上させたものと考えられます(なお、以下ではこれらのネットワークのことを「ニューラルネットワーク」あるいは単に「ネットワーク」と表記します)。

上に示した図にある一つ一つの○(これを「ノード」と呼びます)とそこから他の○へと伸びている線(これを「エッジ」と呼びます)が、脳の神経細胞(ニューロン)を模したものです。それらが見ての通り、ネットワークを形成していることから、「ニューロンのネットワーク」=「ニューラルネットワーク」と呼ばれます(余談ですが、脳神経の世界では、ニューロンからニューロンへは軸索――上の図におけるエッジ――を介して電気信号として情報が伝えられます。このとき、ニューロンの軸索を流れる信号は、伝達先のニューロンの「樹状突起」と呼ばれる部分(ノードにある、エッジと接する箇所)へと伝わります。そして、軸索と樹状突起が接触している部分のことを「シナプス」と呼びます。図の矢印が該当するといえます)。
上の図では一番左側が入力層、一番右側が出力層となり、その間に隠れ層が1つあります。そして、一番左の入力層に何かしらのデータを入れてやることで、このネットワークは計算を始め、一番右の出力層から何らかの回答を弾き出します。この過程のことを「推測」「推論」などと、その回答のことを「推測結果」「推論結果」などと呼ぶこともあります。
重要なのはそれぞれのニューラルネットワークが処理できるデータは、「どういう学習を行ったか」によって決定される点です。音声認識用に学習を行ったニューラルネットワークに対して、画像データを送り込んでも、恐らくそれは適切な答えを計算できません。
現状ではニューラルネットワークで解決したい課題があったとしたら、そのために必要なデータを用意して、それをコンピューターが学習しやすい形に整形し、それを使ってニューラルネットワークに学習をさせて、問題解決に役立つようにしなければなりません。
その一方で、多くの企業(MicrosoftやGoogleなど)が学習済みの高精度なニューラルネットワークを使った人工知能サービスも提供しています。それらを活用すれば、例えば画像認識のような一般的な処理であれば、自力でそのためのニューラルネットワークを作る必要がないこともあるでしょう(もちろん、そうはいかないこともあります)。
本連載では、そうした人工知能サービスの足下にも及ばないものでありますが、簡素なニューラルネットワークを自分で作りながら、人工知能/機械学習/ディープラーニングに関連する概念、基礎知識、用語などを理解することを目的としています。
ニューラルネットワークにおける学習とは
ところで、先ほどは「ニューラルネットワークは入力層、1つ以上の隠れ層、出力層で構成される」という話をしました。しかし、入力層に何かのデータを入れたら、そこから何らかの結果が適切に得られる理由は何でしょう。
例えば、あやめの花弁の長さと幅、がく片の長さと幅という4つのデータを基に、あやめの種類を分類したデータがあったとします(そうしたサンプルデータは実際にあり、次回で紹介します)。

そして、それらの値を基にあやめの種類を「推測」するようなニューラルネットワークが欲しくなったとしましょう。入力層に「がく片の長さ, がく片の幅, 花弁の長さ, 花弁の幅」という4つのデータを与えると、あやめの種類(setosa、versicolor、virginica)のどれであるかを計算してくれるということです。ここであやめの種類には0(setosa)、1(versicolor)、2(virginica)という番号を振っておきます。
すると、ここで求めたいニューラルネットワークは次のようなものになります(先ほどの図と同じ構造なのは、もともと、そうなることを想定して書いたからです)。

そして、このニューラルネットワークに十分に「学習」をさせれば、「がく片の長さ、がく片の幅、花弁の長さ、花弁の幅」として「5.7, 2.8, 4.1, 1.3」というデータを入力すると「1」(versicolor)であると、「4.7, 3.2, 1.3, 0.2」を入力すれば「0」(setosa)であると答えてくれるわけです。では、なぜこうした計算(推測)が行えるのでしょう。
脳神経の世界では、ニューロン間の結合(シナプスの結合)にはそれぞれに強度があります。これはあるニューロンから別のニューロンへ信号が伝達される際の影響の大きさを表すものです。加えて、ニューロンからニューロンへと信号を伝達するかどうかも重要です。あるニューロンが受け取った刺激の大きさが特定の値(これをしきい値などと呼びます)を超えると、そのニューロンは「活性化」します。そして、活性化したニューロンは、次のニューロンへと自分が受け取った信号を伝えます。すなわち、あるニューロンが次のニューロンに信号を伝達するかは、ニューロンが活性化されたか否かで決定されます(この辺の機構は、ソフトウェアとしてのニューラルネットワークとは少々異なるものですが、これについては後日取り上げることにします)。
1つのニューロンは多数のニューロンからの信号を受け取り、それをまた1つ以上のニューロンへと伝えたり伝えなかったりします。何らかの信号(入力)を基に判断が行われる際には、それに関連した多数のニューロンで構成されるネットワーク内を信号が伝わったり伝わらなかったりすることで、「これは○○」「これは××」という結果が得られるということです(こうした処理がほんの一瞬で行われています)。
これをコンピューターで再現するために、ディープラーニング用のフレームワークでは「重み」「バイアス」「活性化関数」などと呼ばれるものが使われています(これらは層と層、あるいはノードとノードのつながりごとに定められる値、または関数です)。「重み」(weight、重み付け、ウエィト)の値は受け取った入力に乗算され、その結果に対して「バイアス」(bias)の値が加算されます。
次のノードへの出力を「y」とすると、「y」の値は「入力×重み+バイアス」として計算できます。このことから、重みは次のノードへの影響の大きさ、バイアスは「入力×重み」にはかせるゲタのようなもの=「ニューロンの活性化のしやすさ」と捉えることができるでしょう。そして、重みとバイアスを用いて計算した結果を「活性化関数」(activation function)に渡すことで、次のノードに伝達する値が決定されます(人の脳であれば、受け取った刺激がしきい値より大きいかどうか、つまりニューロンが活性化するか否かで、信号が伝達されるか否かが決定されますが、ソフトウェアの方では活性化関数により算出された何らかの値が常に次のノードに渡されます)。
これを図にしたものを以下に示します。ただし、上の画像のままではノードとエッジの数が多いので、ここでは入力層の一番上のノード(「I0」とします)と、隠れ層の5つのノード(「H0」〜「H4」とします)とのつながりだけを示します。また、活性化関数をここでは「f(x)」としましょう。あるノードから次のノードに渡す値を算出するときに使用する重みは、ノードとノードのつながりごとに異なる値(「w0」〜「w4」)とし、バイアスについては隠れ層のノード(「H0」〜「H4」)ごとに「b0」〜「b4」が使われるものとします。

入力層の4つのノードと隠れ層の5つのノードを全てエッジでつなぐと、20本になることはすぐ分かります。ノードからノードに流れる数値を計算するには、この数に応じた重みやバイアスも必要です(隠れ層から出力層についても同様です)。つまり、ニューラルネットワークを作るには、多数の数値をなるべく簡単に扱えるような仕組みが必要です(これについては後で話をします)。
さて、ノードごとに定められた重みとバイアスを基に計算した結果(この例では「w0 * x + b0」の計算結果など)は、活性化関数(この例では「f()」)に渡されて、その値が次の層へ伝えられます。そして、次の層でもやはり重みとバイアスを基に計算を行い、その結果が次の層に伝えられ、……、といったように何らかの値がニューラルネットワークを流れていき、出力層から最終的な計算結果が得られます。
今考えている例であれば、4つのデータを基にニューラルネットワーク内でさまざまな計算が行われて、最終的に0〜2の数値が得られます(あやめの種類に合わせた0、1、2のように整数値が得られればよいのですが、次回に紹介するサンプルコードでは実際には実数値=浮動小数点数値が得られるので、それを整数値にしてやる必要があります。ただし、出力層でどのような値を得るかはニューラルネットワークのモデルの設計にもよります)。
このニューラルネットワークにがく片と花弁の長さ/幅を入力した際には、各ノードが持つ重みとバイアスの値が適切なものでなければ、ちゃんとした答えは返ってきません。そこで、それらの値を適切に定めるために、たくさんのデータをネットワークに流して、流すたびに重みとバイアスが適切なものかどうかを確認し、「これはまだ違うなぁ」というのであれば、それらの値を「少しずつ」変化させていきながら、最終的に「おおよそ正しい」であろう重みとバイアスの値を見つけ出す行為がディープラーニングにおける「学習」(learning)です。あるいは、この過程を「訓練」とか「トレーニング」などと呼ぶこともあります。
学習を行う目的でニューラルネットワークに入力するデータのことを「訓練データ」などと呼びます。また、学習の結果、できあがったニューラルネットワークがどの程度の精度で正しい結果を推測できるかを確認する必要があります。このときに使用するデータのことを「テストデータ」(もしくは「精度検証データ」)などと呼びます(これ以外にも学習を進める過程で必要な設定項目もあります。例えば、ニューラルネットワークを構成するのか層の数、各層のノード数、使用する活性化関数などがそうです。これらを「ハイパーパラメーター」と呼びます)。
学習の仕方にはいろいろとあります。例えば、次回で紹介するのは典型的な「教師あり学習」と呼ばれる手法です。教師あり学習では、学習時にニューラルネットワークへ入力するデータ(入力データ)と「正解ラベル」や「教師データ」と呼ばれる「この入力に対する正解の出力はこれ」という値を使用します。そして、ニューラルネットワークからの出力と正解ラベルを比較して、それを基に重みやバイアスを更新していきます。
教師あり学習以外にも「教師なし学習」「強化学習」といった手法もありますが、これらについては、今回は触れず、今後、折を見て紹介することにしましょう。
用語が少したくさん出てきたので、ここで簡単にまとめておきます。
- 人工知能:人間が日々行っている知的な活動を人工的に実現すること
- 機械学習:人工知能の種類の一つで、大量のデータを基にコンピューターに「学習」をさせることで、人の知的活動を実現すること
- ディープラーニング:機械学習を行う方法の一つでニューラルネットワークを強力にしたもの
- ニューロン:脳の神経細胞
- ニューラルネットワーク:複数のニューロンで構成されるネットワーク、およびそれをソフトウェアで模したもの。何らかの入力から、何らかの出力を行う
- ノード:ニューロンをソフトウェアで模したものの構成部品。重みやバイアスを持ち、次のノードとはエッジで接続される
- エッジ:ニューロンをソフトウェアで模したものの構成部品。ノードと次のノードの接続を表す
- 重み/バイアス:ノードが持つ属性で、次のノードへ渡す信号の値を計算する際に使われる
- 活性化関数:各ノードで計算された値を基に、次のノードへ伝えられる値を決定する関数
- 学習:ノードが持つ重みやバイアスを微調整して、ニューラルネットワークが適切な出力を得られるようにする過程
- 教師あり学習:あるデータ(入力)に対応する正解となるデータを用いることで、入力から正解を推測できるように重みとバイアスを決定していく過程
次に機械学習とPythonの関係について考えてみましょう。
Copyright© Digital Advantage Corp. All Rights Reserved.