ƒfپ[ƒ^ƒZƒbƒgپA‘½ژںŒ³”z—ٌپA‘½ƒNƒ‰ƒX•ھ—قپFچى‚ء‚ؤژژ‚»‚¤پIپ@ƒfƒBپ[ƒvƒ‰پ[ƒjƒ“ƒOچHچىژ؛پi1/2 ƒyپ[ƒWپj
‘O‰ٌ‚جƒRپ[ƒh‚ًٹî‚ةپAƒfپ[ƒ^ƒZƒbƒg‚ئ‘½ژںŒ³”z—ٌپAƒfپ[ƒ^ƒZƒbƒg‚ً•ھٹ„‚·‚éˆس–،پAڈo—ح‘w‚ة3‚آ‚جƒmپ[ƒh‚ًژ‚½‚¹‚½ڈêچ‡‚ج‚ ‚â‚ك‚ج•ھ—ق‚ب‚ا‚ة‚آ‚¢‚ؤژو‚èڈم‚°‚ـ‚·پB
پ@‘O‰ٌ‚ح‚ ‚â‚ك‚ج•iژي‚ًگ„‘ھ‚·‚éƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒN‚ًچى‚è‚ب‚ھ‚çپA‚»‚جژèڈ‡‚ً‹ى‚¯‘«‚إ’‚ك‚ـ‚µ‚½پBچ،‰ٌ‚©‚ç‚حگ”‰ٌ‚ة‚ي‚½‚ء‚ؤپA‚»‚جƒRپ[ƒh‚ًڈ‚µڈع‚µ‚Œ©‚½‚èپAƒRپ[ƒh‚ةژè‚ً“ü‚ꂽ‚肵‚ب‚ھ‚çپAƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒN‚ب‚ا‚ة‚آ‚¢‚ؤ‚ج—‰ً‚ًگ[‚ك‚ؤ‚¢‚«‚ـ‚µ‚ه‚¤پB‚ـ‚¸ƒfپ[ƒ^ƒZƒbƒg‚ةٹضکA‚·‚éژ–•؟‚ًژو‚èڈم‚°‚ـ‚·پB
–عژں
ƒfپ[ƒ^ƒZƒbƒg‚ئ‘½ژںŒ³”z—ٌ
پ@‘O‰ٌ‚ةŒ©‚½‚ ‚â‚ك‚جƒfپ[ƒ^ƒZƒbƒg‚حپAscikit-learn‚ھ’ٌ‹ں‚·‚é‚à‚ج‚إ‚µ‚½پBˆب‰؛‚إ‚حپA‚±‚جƒfپ[ƒ^ƒZƒbƒg‚ًڈ‚µڈع‚µ‚Œ©‚ب‚ھ‚çپAƒfپ[ƒ^ƒZƒbƒg‚ئ‚»‚جˆµ‚¢‚ة‚آ‚¢‚ؤژو‚èڈم‚°‚ـ‚·پB
پ@‚ ‚â‚ك‚جƒfپ[ƒ^ƒZƒbƒg‚حژں‚جƒRپ[ƒh‚إ“ا‚فچ‚ف‚ـ‚µ‚½پB
from sklearn.datasets import load_iris
iris = load_iris()
پ@‘O‰ٌ‚àڈq‚ׂـ‚µ‚½‚ھپAƒfپ[ƒ^ƒZƒbƒg‚ة‚حˆê’è‚جŒ`ژ®‚إ•،گ”‚جƒfپ[ƒ^‚ھٹi”[‚³‚ê‚ؤ‚¢‚ـ‚·پB‚±‚ج‚¤‚؟‚جپAdata‘®گ«‚حپu4‚آ‚ج•‚“®ڈ¬گ”“_گ”’l‚ً—v‘f‚ئ‚·‚é”z—ٌپv‚ً—v‘f‚ئ‚·‚é”z—ٌپi”z—ٌ‚ج”z—ٌپj‚إ‚µ‚½پB

پ@چإ‚àƒVƒ“ƒvƒ‹‚ب”z—ٌ‚حپA‚»‚ج—v‘f‚ھˆê•ûŒü‚ة•ہ‚ׂç‚ꂽ‚à‚ج‚إ‚·پB
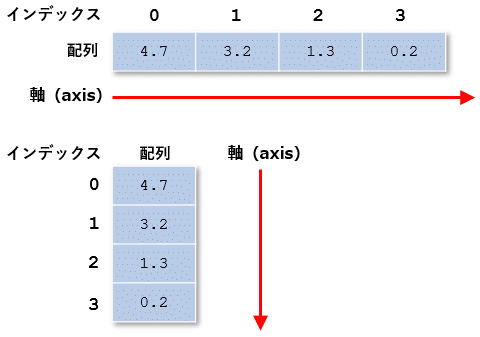
پ@‚»‚ج—v‘f‚ة‚حƒCƒ“ƒfƒbƒNƒXپi”z—ٌ“à‚إ‚ج“ء’è‚ج—v‘f‚ھ‚ا‚±‚ة‚ ‚é‚©‚ًژ¦‚·’lپj‚ً1‚آژw’è‚·‚邱‚ئ‚إƒAƒNƒZƒX‚إ‚«‚ـ‚·پB‚±‚ج‚ئ‚«پA”z—ٌ‚ھ•ہ‚ٌ‚إ‚¢‚é•ûŒü‚ج‚±‚ئ‚ًپuژ²پvپiaxisپj‚ئŒؤ‚ش‚±‚ئ‚ھ‚ ‚è‚ـ‚·پB‚ـ‚½پAژ²‚جگ”‚ًپuژںŒ³گ”پvپuٹKگ”پv‚ب‚ا‚ئŒؤ‚ر‚ـ‚·پBچإ‚àƒVƒ“ƒvƒ‹‚ب”z—ٌ‚حپAژ²‚ھ1‚آ‚إپAژںŒ³گ”‚à1‚إ‚·پB
پ@‚±‚ê‚ة‘خ‚µ‚ؤپA”z—ٌ‚ج”z—ٌ‚حپA1ژںŒ³‚ج”z—ٌ‚ھ‚à‚¤1‚آ‚جژ²‚ة‰ˆ‚ء‚ؤ•ہ‚ׂç‚ê‚ؤ‚¢‚é‚à‚ج‚ئچl‚¦‚ç‚ê‚ـ‚·پB‚·‚ب‚ي‚؟پA”z—ٌ‚ج”z—ٌ‚حژ²‚ھ2‚آ‚ ‚éپiژںŒ³گ”‚ھ2‚جپjƒfپ[ƒ^چ\‘¢‚إ‚·پB‚±‚ج‚±‚ئ‚©‚çپAچ،ڈq‚ׂ½‚و‚¤‚بپu4‚آ‚ج•‚“®ڈ¬گ”“_گ”’l‚ً—v‘f‚ئ‚·‚é”z—ٌپv‚ً—v‘f‚ئ‚·‚é”z—ٌ‚حپA‚و‚پu2ژںŒ³”z—ٌپv‚ئŒؤ‚خ‚ê‚ـ‚·پBگ”ٹw—pŒê‚ًژg‚ء‚ؤپuچs—ٌپv‚ئ‚àŒؤ‚خ‚ê‚ـ‚·پB

پ@ڈم‚جگ}‚ةژ¦‚µ‚½‚و‚¤‚ةپA2ژںŒ³”z—ٌ‚إ‚حڈcژ²پiژ²0پj‚ة‰ˆ‚ء‚ؤچs‚ج—v‘f‚ھ•ہ‚ׂç‚êپA‰،ژ²پiژ²1پj‚ة‰ˆ‚ء‚ؤ—ٌ‚ج—v‘f‚ھ•ہ‚ׂç‚ê‚ـ‚·پB2ژںŒ³‚ج”z—ٌ‚إ“ء’è‚ج—v‘f‚ةƒAƒNƒZƒX‚·‚é‚ة‚حپAƒCƒ“ƒfƒbƒNƒX‚ً1‚آپA‚ـ‚½‚ح2‚آژw’肵‚ـ‚·پB
پ@1‚آژw’肵‚½‚ئ‚«‚ة‚حپA”z—ٌ‚ً—v‘f‚ئ‚µ‚ؤ‚¢‚éپiژ²0‚ة‰ˆ‚ء‚ؤ•ہ‚ٌ‚إ‚¢‚éٹO‘¤پj”z—ٌپiچsپj‚جƒCƒ“ƒfƒbƒNƒX‚ھژw’肳‚ꂽ‚à‚ج‚ئ‚µ‚ؤˆµ‚ي‚ê‚ـ‚·پB‚آ‚ـ‚èپA‚±‚ê‚ة‚و‚èٹO‘¤‚ج—v‘f‚ج”z—ٌ‚ئ‚ب‚ء‚ؤ‚¢‚é”z—ٌپiچ،‰ٌ‚ج—ل‚ب‚çپAŒآپX‚ج‚ ‚â‚ك‚جƒfپ[ƒ^‚ةƒAƒNƒZƒX‚·‚邱‚ئ‚ة‚ب‚è‚ـ‚·پjپB
پ@ƒCƒ“ƒfƒbƒNƒX‚ً2‚آژw’è‚·‚é‚ئپA‚»‚ê‚ح”z—ٌ‚ج—v‘f‚ئ‚ب‚ء‚ؤ‚¢‚é”z—ٌ‚ج“ء’è‚ج—v‘f‚ةƒAƒNƒZƒX‚·‚邱‚ئ‚ة‚ب‚è‚ـ‚·پiچ،‰ٌ‚ج—ل‚إ‚ ‚ê‚خپAŒآپX‚ج‚ ‚â‚ك‚جƒfپ[ƒ^‚ًچ\گ¬‚·‚é‚ھ‚•ذ‚ج’·‚³پ^•پA‰ش•ظ‚ج’·‚³پ^•‚ج‚¢‚¸‚ê‚©‚ج—v‘f‚ةƒAƒNƒZƒX‚·‚邱‚ئ‚ة‚ب‚è‚ـ‚·پjپB
پ@‚ ‚â‚ك‚جƒfپ[ƒ^ƒZƒbƒg‚إ‚حپA‚»‚ج‚ھ‚•ذ‚ج’·‚³‚ئ•پA‰ش•ظ‚ج’·‚³‚ئ•‚ج4‚آ‚جگ”’l‚ً‚ذ‚ئ‚ـ‚ئ‚ك‚ة‚µ‚½”z—ٌ‚ً—v‘f‚ئ‚·‚é”z—ٌ‚ًˆµ‚¤‚¾‚¯‚ب‚ج‚إپA2ژںŒ³‚ج”z—ٌ‚إڈ\•ھ‚إ‚µ‚½‚ھپA‰و‘œ‚ج‚و‚¤‚ة‚à‚ئ‚à‚ئ‚ھ2ژںŒ³‚جچ\‘¢‚ًژ‚آƒfپ[ƒ^‚ً‘ه—ت‚ةٹـ‚قƒfپ[ƒ^ƒZƒbƒg‚إ‚ح3ژںŒ³‚ج”z—ٌ‚ھڈo‚ؤ‚‚邱‚ئ‚à‚ ‚é‚إ‚µ‚ه‚¤پi‚½‚¾‚µپA‚±‚¤‚µ‚½ƒfپ[ƒ^‚ح‰و‘œ‚ئ‚¢‚¤2ژںŒ³‚جƒfپ[ƒ^‚ً1ژںŒ³‚جƒfپ[ƒ^‚ة•دٹ·‚µ‚ؤژg—p‚·‚邱‚ئ‚à‚و‚‚ ‚è‚ـ‚·پjپB
پ@‹@ٹBٹwڈK‚âƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒN‚جگ¢ٹE‚إ‚حپAڈd‚ف‚âƒoƒCƒAƒXپA“ü—ح‚³‚ê‚éƒfپ[ƒ^پAŒvژZŒ‹‰ت‚جڈo—ح‚ب‚اپA‚³‚ـ‚´‚ـ‚بڈê–ت‚إ•دگ”‚ً‘ه—ت‚ةژg—p‚µ‚ـ‚·پB‚ـ‚½پAژہچغ‚جŒvژZڈˆ—‚إ‚حپAچs—ٌ‚ج‘€چى‚≉ژZ‚à•p”ة‚ة“oڈꂵ‚ـ‚·پB‚»‚ج‚½‚كپA‘½گ”‚ج•دگ”‚ًˆêٹ‡‚µ‚ؤپAچ‚‘¬‚ةڈˆ—‚إ‚«‚é‰بٹwŒvژZƒ‰ƒCƒuƒ‰ƒٹ‚إ‚ ‚éNumPy‚âپA‚»‚ê‚ًٹî‚ة”“W‚µ‚½‚³‚ـ‚´‚ـ‚بƒtƒŒپ[ƒ€ƒڈپ[ƒN‚ھژg‚ي‚ê‚é‚ج‚ح‘O‰ٌ‚ة‚à‚¨کb‚µ‚µ‚½’ت‚è‚إ‚·پB
پ@‚ـ‚½پAPyTorch‚ب‚ا‚جƒtƒŒپ[ƒ€ƒڈپ[ƒN‚إ‚حپA”z—ٌ‚ب‚ا‚جƒfپ[ƒ^چ\‘¢‚ج‚±‚ئ‚ًپuƒeƒ“ƒ\ƒ‹پv‚ئ‘چڈج‚·‚邱‚ئ‚à‘O‰ٌ‚ةڈذ‰î‚µ‚½’ت‚è‚إ‚·پB‚ـ‚½پA‚±‚¤‚µ‚½ƒfپ[ƒ^چ\‘¢‚ج’†‚إ‚à1ژںŒ³”z—ٌ‚حپuƒxƒNƒgƒ‹پv‚ئ‚©پuƒxƒNƒ^پ[پv‚ئپA2ژںŒ³”z—ٌ‚ج‚±‚ئ‚حپuچs—ٌپv‚ب‚ا‚ئŒؤ‚ش‚±‚ئ‚à‚و‚‚ ‚è‚ـ‚·پB3ژںŒ³”z—ٌ‚ب‚اپAژںŒ³پiٹKگ”پj‚ھ3‚ً’´‚¦‚é‚à‚ج‚ة‚آ‚¢‚ؤ‚ح“ء•ت‚ب–¼ڈج‚ح‚ب‚پAپuƒeƒ“ƒ\ƒ‹پv‚ئŒؤ‚ش‚ج‚ھˆê”ت“I‚إ‚·پB‚±‚ê‚ç‚ج—pŒê‚ة‚àڈ™پX‚ةٹµ‚ê‚ؤ‚¢‚•K—v‚ھ‚ ‚é‚إ‚µ‚ه‚¤پB
پ@—pŒê‚ةٹµ‚ê‚é‚ج‚ئ“¯ژ‚ةپAƒeƒ“ƒ\ƒ‹‚جˆµ‚¢‚ة‚àٹµ‚ê‚ؤ‚¢‚•K—v‚à‚ ‚è‚ـ‚·پB‚»‚±‚إپAPyTorch‚جƒeƒ“ƒ\ƒ‹‚جˆµ‚¢‚ًڈ‚µ‚¾‚¯Œ©‚ؤ‚¨‚«‚ـ‚µ‚ه‚¤پBڈع‚µ‚‚حپuPyTorch‚جƒeƒ“ƒ\ƒ‹پ•ƒfپ[ƒ^Œ^‚جƒ`پ[ƒgƒVپ[ƒgپv‚ًژQڈئ‚µ‚ؤ‚‚¾‚³‚¢پB
import torch
X = torch.tensor(iris.data) # “ü—حƒfپ[ƒ^‚ًPyTorch‚جƒeƒ“ƒ\ƒ‹‚ة•دٹ·
# X‚جƒTƒCƒY‚ً’²‚ׂé
print(X.size())
print(X.shape) # NumPy‚ئ“¯—l‚بڈ‘‚«•û
print(len(X)) # ٹO‘¤‚ج”z—ٌ‚ج—v‘fگ”پiچsگ”پj
print(X.dim()) # ƒeƒ“ƒ\ƒ‹‚جژںŒ³گ”
print(X.ndim) # NumPy‚ئ“¯—l‚بڈ‘‚«•û
# ƒeƒ“ƒ\ƒ‹‚ج—v‘f‚جƒfپ[ƒ^Œ^‚ً’²‚ׂé
print(X.dtype)
# ƒeƒ“ƒ\ƒ‹‚ج—v‘f‚ض‚جƒAƒNƒZƒX
print(X[0]) # گو“ھچs
print(X[0][0]) # گو“ھچs‚جگو“ھ—v‘f
print(X[1:3]) # ‘و1چs‚ئ‘و2چs
print(X[1:3, 1:3]) # ‘و1چs‚ئ‘و2چs‚ج1—ٌ–ع‚ئ2—ٌ–ع‚ج—v‘f
print(X[1:3][1:3]) # ‚±‚جڈ‘‚«•û‚حˆس–،‚ھˆظ‚ب‚é“_‚ة’چˆس
پ@ڈم‚جƒRپ[ƒh‚ًژہچs‚µ‚½Œ‹‰ت‚حژں‚ج’ت‚è‚إ‚·پB

پ@‹C‚ً•t‚¯‚ؤ‚ظ‚µ‚¢‚ج‚حپAچإŒم‚ج2چs‚جڈo—ح‚إ‚·پB‚ا‚؟‚ç‚àچs—ٌ‚جƒXƒ‰ƒCƒX‚ًژو“¾‚·‚éƒRپ[ƒh‚إ‚·‚ھپAژو‚èڈo‚³‚ê•û‚ھˆظ‚ب‚è‚ـ‚·پBپuX_train[1:3, 1:3]پv‚حچs—ٌ‚ج‘و1چs‚ئ‘و2چs‚©‚ç‘و1—ٌ‚ئ‘و2—ٌ‚ج—v‘f‚ًژو‚èڈo‚·‚à‚ج‚إ‚·پBˆê•ûپAپuX_train[1:3][1:3]پv‚حچs—ٌ‚ج‘و1چs‚ئ‘و2چs‚©‚ç‚ب‚é”z—ٌ‚ًژو‚èڈo‚µ‚½ڈم‚إپA‚»‚ج‘و1چs‚ئ‘و2چs‚ًژو“¾‚·‚é‚à‚ج‚إ‚·پiƒCƒ“ƒfƒbƒNƒX‚حƒ[ƒچژn‚ـ‚è‚ب‚ج‚إپAژہچغ‚ة‚ح‘و1چs‚¾‚¯‚ھ“¾‚ç‚ê‚ـ‚·پjپB‚»‚جڈم‚ة‚ ‚éڈo—ح‚ئ”نٹr‚·‚é‚ئپA‚ا‚ج‚و‚¤‚ةƒfپ[ƒ^‚ھژو‚èڈo‚³‚ê‚ؤ‚¢‚é‚©‚ھ•ھ‚©‚é‚إ‚µ‚ه‚¤پB
پ@چ،‰ٌ‚حپA‚±‚¤‚µ‚½‘€چى‚ھڈo‚ؤ‚‚邱‚ئ‚ح‚ ‚ـ‚è‚ ‚è‚ـ‚¹‚ٌ‚ھپAŒم‘±‚ج‰ٌ‚إپA•K—v‚ة‰‚¶‚ؤڈذ‰î‚µ‚ؤ‚¢‚‚±‚ئ‚ة‚µ‚ـ‚·پB
ƒfپ[ƒ^ƒZƒbƒg‚ج•ھٹ„‚ة‚آ‚¢‚ؤ
پ@‘O‰ٌ‚حپA“ا‚فچ‚ٌ‚¾ƒfپ[ƒ^ƒZƒbƒg‚ًٹwڈK‚ئ•]‰؟پiƒeƒXƒgپj‚ةژg—p‚·‚é–ع“I‚إ2‚آ‚ة•ھٹ„‚µ‚ـ‚µ‚½پB
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target)
پ@ڈم‚جƒRپ[ƒh‚إ‚حƒfپ[ƒ^ƒZƒbƒg‚ً2‚آ‚ة•ھٹ„‚µ‚ؤ‚¢‚ـ‚·پB‚±‚ê‚ح‘O‰ٌ‚àŒ©‚½‚و‚¤‚ةپAƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒN‚إƒ‚ƒfƒ‹‚جٹwڈK‚ًچs‚¢پA‚»‚ج•]‰؟پiŒںڈطپ^ƒeƒXƒgپj‚ًچs‚¤‚½‚ك‚إ‚·پB‚µ‚©‚µپAژہچغ‚ةژ©•ھ‚إƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒN‚ًچىگ¬‚µ‚ؤ‚¢‚é‚ئ•ھ‚©‚è‚ـ‚·‚ھپAٹwڈK‚ًچs‚¤چغ‚ة‚حژژچsچِŒë‚ھ‚آ‚«‚à‚ج‚إ‚·پB—ل‚¦‚خپAƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒN‚جƒmپ[ƒh‚جگ”‚ً•دچX‚µ‚½‚èپA‘w‚ً‘‚₵‚½‚茸‚炵‚½‚èپAٹˆگ«‰»ٹضگ”‚ً•دچX‚µ‚½‚è‚ئ‚¢‚¤‚±‚ئ‚ھ”گ¶‚µ‚ـ‚·پi‚±‚¤‚µ‚½—v‘f‚ًپuƒnƒCƒpپ[ƒpƒ‰ƒپپ[ƒ^پ[پv‚ئŒؤ‚ر‚ـ‚·پjپB
پ@‚±‚ج‚و‚¤‚ب’²گ®‚ًچs‚¤‘O‚ة‚حپA‚ ‚éژ“_‚إچىگ¬‚µ‚½پiٹ®گ¬‘O‚جپjƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒNƒ‚ƒfƒ‹‚ھ‚ا‚ج’ِ“x‚جگ¸“x‚ًژ‚ء‚ؤ‚¢‚é‚©‚ً’²‚ׂé•K—v‚ھ‚ ‚è‚ـ‚·پBگ¸“x‚ً’²‚ׂؤپAƒnƒCƒpپ[ƒpƒ‰ƒپپ[ƒ^پ[‚ً’²گ®‚µ‚ؤپA‚ـ‚½ٹwڈK‚ً‚â‚è’¼‚µ‚ؤپA‚»‚جگ¸“x‚ً•]‰؟‚µ‚ؤپcپc‚ئ‚¢‚¤‰ك’ِ‚ًŒo‚ب‚ھ‚çپAچإ“K‚بƒnƒCƒpپ[ƒpƒ‰ƒپپ[ƒ^پ[‚ًŒˆ’è‚·‚éڈêچ‡‚à‚ ‚è‚ـ‚·‚µپA‚ ‚é‚¢‚حˆظ‚ب‚éƒnƒCƒpپ[ƒpƒ‰ƒپپ[ƒ^پ[‚ًژg‚ء‚ؤٹwڈK‚³‚¹‚½ƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒNƒ‚ƒfƒ‹‚ًٹô‚آ‚©—pˆس‚µ‚ؤ‘I‚ش‚ئ‚¢‚ء‚½ڈêچ‡‚à‚ ‚é‚إ‚µ‚ه‚¤پB‚±‚ج‚و‚¤‚ةپAژژچsچِŒë‚ج’iٹK‚إ‚حپAŒP—ûƒfپ[ƒ^‚ئپAژb’è“I‚ةچىگ¬‚µ‚½ƒ‚ƒfƒ‹‚جگ¸“x‚ًŒںڈط‚·‚éƒfپ[ƒ^‚ج2‚آ‚جƒfپ[ƒ^‚ھ•K—v‚ة‚ب‚è‚ـ‚·پi‘O‰ٌ‚ح’Pڈƒ‚ةscikit-learn‚ھ’ٌ‹ں‚·‚étrain_test_splitٹضگ”‚ً—p‚¢‚ؤ•ھٹ„‚µ‚ؤ‚¢‚ـ‚µ‚½‚ھپAژہچغ‚ة‚حŒP—ûƒfپ[ƒ^‚ئ•]‰؟ƒfپ[ƒ^‚ً•ھٹ„‚·‚é‚ة‚ح‚³‚ـ‚´‚ـ‚بژè–@‚ھ‚ ‚è‚ـ‚·پjپB
پ@ٹwڈK‚ئ•]‰؟‚ًŒJ‚è•ش‚µ‚ؤٹ®گ¬‚µ‚½ƒ‚ƒfƒ‹‚حٹwڈKƒfپ[ƒ^‚ئ•]‰؟ƒfپ[ƒ^‚ة‘خ‚µ‚ؤ‚ح‚و‚¢گ¸“x‚إŒ‹‰ت‚ًژZڈo‚إ‚«‚é‚و‚¤‚ة‚ب‚ء‚ؤ‚¢‚ـ‚·پBˆê•ûپA‚»‚ê‚ھ–{“–‚ة”ؤ—p“I‚ةژg‚¦‚é‚©‚ا‚¤‚©پi‚·‚ب‚ي‚؟پA–¢’m‚جƒfپ[ƒ^‚ة‚آ‚¢‚ؤ‚à‚و‚¢گ¸“x‚إŒ‹‰ت‚ًژZڈo‚إ‚«‚é‚©‚ا‚¤‚©پj‚ًƒeƒXƒg‚·‚邽‚ك‚ة‚حپAچ،ڈq‚ׂ½2‚آ‚جƒfپ[ƒ^‚ئ‚ح“ئ—§‚µ‚½ƒfپ[ƒ^پiƒeƒXƒgƒfپ[ƒ^پj‚ھ•K—v‚إ‚·پB
پ@‚±‚¤‚µ‚½‚±‚ئ‚©‚çپAƒfپ[ƒ^ƒZƒbƒg‚ًژں‚ج3‚آ‚ة•ھٹ„‚·‚é‚ئ‚¢‚¤‚ج‚ھچإ‹ك‚إ‚حˆê”ت“I‚ة‚ب‚ء‚ؤ‚¢‚ـ‚·پB
- ŒP—ûƒfپ[ƒ^پFƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒN‚إ‚جٹwڈKپiƒ‚ƒfƒ‹“à‚جڈd‚ف‚âƒoƒCƒAƒX‚جچXگVپj‚ةژg‚ي‚ê‚é
- •]‰؟ƒfپ[ƒ^پFٹwڈKŒم‚جƒ‚ƒfƒ‹‚جگ«”\‚ًŒںڈط‚·‚邽‚ك‚ةژg‚ي‚ê‚é
- ƒeƒXƒgƒfپ[ƒ^پFچإڈI“I‚ةٹ®گ¬‚µ‚½ƒ‚ƒfƒ‹‚ھ”ؤ—p“I‚ةژg‚¦‚é‚©‚ا‚¤‚©‚ًƒeƒXƒg‚·‚é‚ج‚ةژg‚ي‚ê‚é
پ@‘O‰ٌ‚حٹwڈKژ‚ج‚³‚ـ‚´‚ـ‚بƒpƒ‰ƒپپ[ƒ^پ[‚حŒˆ‚ك‘إ‚؟‚ئ‚µ‚ؤپAژژچsچِŒë‚·‚邱‚ئ‚ب‚پAƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒN‚جƒ‚ƒfƒ‹‚ةٹwڈK‚ً‚³‚¹پAˆê“x‚جٹwڈK‚إƒ‚ƒfƒ‹‚ًٹ®گ¬‚³‚¹‚½‚ج‚إپA2‚آ‚ة•ھٹ„‚·‚ê‚خڈ\•ھ‚إ‚µ‚½پB
پ@2‚آپi‚ ‚é‚¢‚ح3‚آپj‚ة•ھٹ„‚µ‚½ƒfپ[ƒ^ƒZƒbƒg‚حپAٹwڈK‚â‚»‚جŒم‚ج•]‰؟پAƒeƒXƒg‚إژg‚ي‚ê‚ـ‚·پBƒfپ[ƒ^ƒZƒbƒg‚جƒfپ[ƒ^‚ً‚»‚ج‚ـ‚ـ‘f’¼‚ةˆµ‚¦‚ê‚خ–â‘è‚ح‚ب‚¢‚إ‚µ‚ه‚¤‚ھپA‘O‰ٌ‚àŒ©‚½‚و‚¤‚ةƒtƒŒپ[ƒ€ƒڈپ[ƒN‚ةچ‡‚ي‚¹‚½ƒfپ[ƒ^Œ^‚ج•دٹ·‚ھ•K—v‚ة‚ب‚邱‚ئ‚à‚ ‚é‚إ‚µ‚ه‚¤‚µپAچىگ¬‚·‚郂ƒfƒ‹‚ة‚¤‚ـ‚“Kچ‡‚·‚é‚و‚¤‚ةƒfپ[ƒ^‚ً•دٹ·‚µ‚ب‚¯‚ê‚خ‚ب‚ç‚ب‚¢‚±‚ئ‚à‚ ‚è‚ـ‚·پB‚»‚±‚إپAژںƒyپ[ƒW‚إ‚حپA‘O‰ٌ‚ةŒ©‚½ƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒNƒ‚ƒfƒ‹‚ًڈ‚µ•دچX‚µ‚ؤپAƒfپ[ƒ^ƒZƒbƒg‚ةٹـ‚ـ‚ê‚éƒfپ[ƒ^‚⃂ƒfƒ‹‚جŒvژZŒ‹‰ت‚جˆµ‚¢‚â‰ًژك‚ھ‚ا‚¤•د‚ي‚é‚©‚ًŒ©‚ؤ‚ف‚ـ‚·پB
•دگ”–¼‚ة‚آ‚¢‚ؤ
پ@ڈم‚جƒRپ[ƒh—ل‚إ‚حپAƒfپ[ƒ^ƒZƒbƒg‚ً•ھٹ„‚µ‚ؤپAپuX_trainپvپuy_testپv‚ب‚ا‚ج•دگ”‚ة‘م“ü‚µ‚ؤ‚¢‚ـ‚µ‚½پB‚±‚±‚إ‚±‚ê‚ç‚ج•دگ”–¼‚ة‚آ‚¢‚ؤڈ‚µ‚¾‚¯کb‚ً‚µ‚ؤ‚¨‚«‚ـ‚·پB
پ@گ”ٹw‚جگ¢ٹE‚إ‚حپAٹضگ”‚ئ‚»‚ج’l‚ً‚و‚پuy=f(x)پv‚ئ•\‚µ‚ـ‚·پB‚±‚ê‚حپufپv‚ئ‚¢‚¤ٹضگ”پifunctionپj‚ةپuxپv‚ئ‚¢‚¤•دگ”‚ھژ‚آ’l‚ً—^‚¦‚é‚ئپA‚»‚جŒ‹‰ت‚ھپuyپv‚ة‚ب‚邱‚ئ‚ًˆس–،‚µ‚ـ‚·پB‚±‚±‚إپA‚±‚ê‚©‚çچىگ¬‚·‚郂ƒfƒ‹‚ًٹضگ”‚ئ‚µ‚ؤچl‚¦‚é‚ئپAپu“ü—حپ¨ٹضگ”پiƒ‚ƒfƒ‹پjپ¨ڈo—حپv‚ج‚و‚¤‚ة‚àڈ‘‚«•\‚¹‚ـ‚·پB‚±‚ج‚ئ‚«“ü—ح‚·‚éƒfپ[ƒ^پi‚ ‚â‚ك‚ج“ء’¥‚ًژ¦‚·4‚آ‚ج’lپj‚ح‘Oڈq‚جپuxپv‚ةپAڈo—حپiƒ‚ƒfƒ‹‚ة‚و‚èژZڈo‚³‚ꂽ‚ ‚â‚ك‚جژي—قپj‚حپuyپv‚ة‘ٹ“–‚·‚邱‚ئ‚ح‚¨•ھ‚©‚è‚إ‚µ‚ه‚¤پB
پ@‚±‚ج‚±‚ئ‚ةچ‡‚ي‚¹‚ؤپA‚±‚±‚إ‚حٹwڈK‚âƒeƒXƒg‚ج‚ئ‚«‚ةƒ‚ƒfƒ‹‚ة“ü—ح‚·‚é’l‚حپuXپv‚إپA‚»‚جڈo—ح‚ئ”نٹr‚·‚éگ³‰ًƒ‰ƒxƒ‹‚حپuyپv‚إژn‚ـ‚é‚و‚¤‚ب–¼‘O‚ئ‚µ‚ؤ‚¢‚ـ‚·پBپuXپv‚ھڈ¬•¶ژڑ‚إ‚ح‚ب‚‘ه•¶ژڑ‚ة‚ب‚ء‚ؤ‚¢‚é‚ج‚حپA“ü—ح‚·‚é‚à‚ج‚ھƒfپ[ƒ^ƒZƒbƒgپA‚آ‚ـ‚èپwپu1Œآˆبڈم‚ج’l‚إچ\گ¬‚³‚ê‚é”z—ٌپv‚ً—v‘f‚ئ‚·‚é”z—ٌپxپپپuچs—ٌپv‚إ‚ ‚èپAگ”ٹw‚إ‚حپAچs—ٌ‚ح‘ه•¶ژڑ‚إ•\Œ»‚·‚邱‚ئ‚©‚炱‚ج‚و‚¤‚ب–½–¼•û–@‚ة‚ب‚ء‚ؤ‚¢‚ـ‚·پB
پ@‚»‚جŒم‚ة‘±‚پutrainپvپutestپv‚ئ‚¢‚¤‚ج‚حپA“ا‚ٌ‚إژڑ‚ج‚²‚ئ‚پA‚»‚ê‚ھٹwڈKپiŒP—ûپAtrainپj‚إژg‚ي‚ê‚é‚©پA‚إ‚«‚½ƒ‚ƒfƒ‹‚ج•]‰؟پiƒeƒXƒgپAtestپj‚إژg‚ي‚ê‚é‚©‚ًˆس–،‚µ‚ـ‚·پB‚±‚ê‚ç2‚آ‚ج—v‘f‚ًƒAƒ“ƒ_پ[ƒXƒRƒAپu_پv‚إ‚آ‚ب‚°‚½‚à‚ج‚ً‚±‚±‚إ‚ح•دگ”–¼‚ئ‚µ‚ؤژg‚ء‚ؤ‚¢‚ـ‚·پB
پ@‚à‚؟‚ë‚ٌپA‚±‚êˆبٹO‚ج–½–¼–@‚à‚ ‚é‚إ‚µ‚ه‚¤پB—ل‚¦‚خپAپuX_trainپv‚إ‚ح‚ب‚پutrain_dataپv‚ئ‚µ‚½‚èپAپuy_trainپv‚إ‚ح‚ب‚پutrain_labelپv‚ئ‚µ‚½‚è‚·‚邱‚ئ‚ھچl‚¦‚ç‚ê‚ـ‚·پB‚±‚؟‚ç‚ج•û–@‚إ‚àپA•دگ”‚ج’l‚ھŒP—ûƒfپ[ƒ^‚إ‚ ‚邱‚ئپAŒP—û‚ةژg—p‚·‚éگ³‰ًƒ‰ƒxƒ‹‚إ‚ ‚邱‚ئ‚ھ•ھ‚©‚è‚ـ‚·پB‚¢‚¸‚ê‚ة‚¹‚وپA‚»‚ج•دگ”‚ھ‰½‚ج‚½‚ك‚جƒfپ[ƒ^‚ًژQڈئ‚·‚é‚à‚ج‚©‚ھ•ھ‚©‚é–¼‘O‚ة‚·‚邱‚ئ‚ھ‘هژ–‚إ‚·پB
Copyright© Digital Advantage Corp. All Rights Reserved.