PyTorchでDCGANを作ってみよう:作って試そう! ディープラーニング工作室(1/2 ページ)
PyTorchが提供するConv2dクラスとConvTranspose2dクラスを使ってDCGANを実装しながら、その特徴を見ていきましょう。
今回の目的
前回は全結合型のニューラルネットワークを用いて、GANを構成しました。題材に選んだのはMNISTの手書き数字です。しかし、その結果はあまり芳しいものではありませんでした。
そこで、今回は「CNNなんて怖くない! その基本を見てみよう」や「PyTorchで畳み込みオートエンコーダーを作ってみよう」などで取り上げた畳み込みニューラルネットワークを利用して、GANを構築してみることにします。
実際の構成は、次のようになります。以下ではConv2dクラスとConvTranspose2dクラスのみを含めてありますが、BatchNorm2dクラスおよびtorch.nnモジュールが提供する活性化関数クラス(torch.nn.Sigmoidクラス、torch.nn.Tanhクラス)も使用します。訓練データと偽物のデータの識別と偽物データの生成の中心的な処理はこれら2つのクラスが請け負うということです。
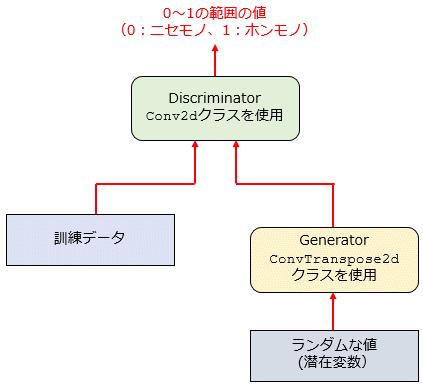
識別器(ディスクリミネーター)では、CNNで使用するConv2dクラスにより訓練データおよび生成器(ジェネレーター)から入力されたデータを最終的に0〜1の値へと変換していきます(畳み込みはここで使用)。生成器の側では「PyTorchで畳み込みオートエンコーダーを作ってみよう」で紹介したデコーダーと同様にConvTranspose2dクラスを用いて、ランダムな値(潜在変数)からMNISTの手書き数字として識別器をだませるようなデータを生成します(転置畳み込み)。
このような畳み込み層を使って作成されるGANのことをDCGAN(Deep Convolutional Generative Adversarial Networks)と呼びます。DCGANは2016年に「Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks」という論文で提唱されたものです。
以下では、識別器と生成器の構成を少しずつ変えながら、よい感じの画像を生成できるかを試してみることにしましょう。
コードの紹介
今回のコード全体はこのノートブックで公開し、いつものコードは例によって本稿末尾にまとめて掲載しますが、上でも述べたように今回は識別器と生成器の構成を何度か変更してみるために、それらを生成するための鋳型として次のクラスを定義しました。
class MakeFrom(nn.Module):
def __init__(self, s):
super().__init__()
self.model = s
def forward(self, x):
return self.model(x)
このクラスは、インスタンス生成時にPyTorchのSequentialクラスのインスタンスを受け取ることを念頭に置いています。Sequentialクラスについては「PyTorchでCIFAR-10を処理するオートエンコーダーを作ってみよう」などでも取り上げましたが、そのインスタンス生成時に引数として与えられたPyTorchの1つ以上のネットワークモジュールを内部に格納するコンテナのようなものです。上のMakeFromクラスのforwardメソッドでは、インスタンス変数self.modelに格納したそれらのネットワークモジュールを順次実行するだけとなっています。
例えば、次のような使い方をします。
discriminator = nn.Sequential(
nn.Conv2d(1, 8, 5, 2, bias=False),
nn.LeakyReLU(0.2),
nn.Conv2d(8, 16, 5, 2, bias=False),
nn.LeakyReLU(0.2),
nn.Conv2d(16, 32, 3, bias=False),
nn.LeakyReLU(0.2),
nn.Conv2d(32, 1, 2, bias=False),
nn.Sigmoid()
)
netD = MakeFrom(discriminator)
この例では、Sequentialクラスのインスタンス生成時に、ニューラルネットワークを構成する各種クラスのインスタンスを(実行したい順番に)カンマ区切りで並べています。そして、できたインスタンスdiscriminatorを指定してMakeFromクラスのインスタンスを作成することで、識別器として動作するオブジェクトを得ているということです。
また、構成を変えながらニューラルネットワークモデルを何度か生成するため、訓練を行う処理も関数にまとめました。以下にその関数を示します。
def train(netD, netG, batch_size, zsize, epochs, trainloader):
losses_netD = []
losses_netG = []
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
netD = netD.to(device)
netG = netG.to(device)
one_labels = torch.ones(batch_size).reshape(batch_size, 1).to(device)
zero_labels = torch.zeros(batch_size).reshape(batch_size, 1).to(device)
criterion = nn.BCELoss().to(device)
optD = optim.Adam(netD.parameters(), lr=0.0002, betas=[0.5, 0.999])
optG = optim.Adam(netG.parameters(), lr=0.0002, betas=[0.5, 0.999])
for epoch in range(1, epochs+1):
running_loss_netD = 0.0
running_loss_netG = 0.0
for count, (real_imgs, _) in enumerate(trainloader, 1):
netD.zero_grad()
# 識別器の学習
real_imgs = real_imgs.to(device)
# データローダーから読み込んだデータを識別器に入力し、損失を計算
output_from_real = netD(real_imgs).reshape(batch_size, -1)
loss_from_real = criterion(output_from_real, one_labels)
loss_from_real.backward()
# 生成器から得たデータを、識別器に入力し、損失を計算
z = torch.randn(batch_size, zsize, 1, 1).to(device)
fake_imgs = netG(z).to(device)
output_from_fake = netD(fake_imgs.detach()).reshape(batch_size, -1)
loss_from_fake = criterion(output_from_fake, zero_labels)
loss_from_fake.backward()
# それらをまとめたものが最終的な損失
loss_netD = loss_from_real + loss_from_fake
optD.step()
running_loss_netD += loss_netD
# 生成器の学習
netG.zero_grad()
z = torch.randn(batch_size, zsize, 1, 1).to(device)
fake_imgs = netG(z).to(device)
output_from_fake = netD(fake_imgs).reshape(batch_size, -1)
loss_netG = criterion(output_from_fake, one_labels)
loss_netG.backward()
optG.step()
running_loss_netG += loss_netG
running_loss_netD /= count
running_loss_netG /= count
print(f'epoch: {epoch}, netD loss: {running_loss_netD}, netG loss: {running_loss_netG}')
losses_netD.append(running_loss_netD)
losses_netG.append(running_loss_netG)
if epoch % 10 == 0:
z = torch.randn(batch_size, zsize, 1, 1).to(device)
generated_imgs = netG(z).cpu()
imshow(generated_imgs[0:8].reshape(8, 1, 28, 28))
return losses_netD, losses_netG
train関数のコード自体は、前回に見たものとそれほど変わりません。全結合型のニューラルネットワークではなく、畳み込みを使用するので、それに合わせたコードの修正を行った程度です(最適化アルゴリズムの選択や、正解ラベルとなるデータの作成、GPUを使えるかどうかの判定とそれに対応した処理なども関数内に含めるようにしました)。
細かいことはともかくとして、要するに上で見たMakeFromクラスを使い、識別器と生成器を作ったら、基本的には上のtrain関数を呼び出すだけで訓練ができるようになっているというわけです。
というわけで、まずはシンプルにConv2dクラスとConvTranspose2dクラスのみで構成されるシンプルな識別器と生成器を作ってみましょう。
シンプルな識別器と生成器
識別器のコードは次の通りです(以下ではPyTorchのドキュメント「DCGAN Tutorial」に合わせて、Conv2dクラスとConvTranspose2dクラスのインスタンス生成ではbias=Falseを指定して、バイアスを持たせないようにしています。興味のある方は、バイアスを持たせてみましょう)。
discriminator = nn.Sequential(
nn.Conv2d(1, 8, 5, 2, bias=False),
nn.LeakyReLU(0.2),
nn.Conv2d(8, 16, 5, 2, bias=False),
nn.LeakyReLU(0.2),
nn.Conv2d(16, 32, 3, bias=False),
nn.LeakyReLU(0.2),
nn.Conv2d(32, 1, 2, bias=False),
nn.Sigmoid()
)
netD = MakeFrom(discriminator)
このコードからは、識別器が4つの層で構成されることが分かります。各層ではConv2dクラス(のみ)を用いて、入力されたデータを段階的に削減して、最終的に0〜1の範囲の値を1つだけ出力します(もちろん、最後の活性化関数としてPyTorchのSigmoidクラスを使っているのは、出力を0〜1の範囲とするためです)。Leaky ReLU関数を使用しているのは、先ほど紹介した論文の中で「Leaky ReLUがいい感じに使える」とあったからです。
段階的にデータが削減されていく様子は、今回のコードを含んだノートブックを参考にしてください(Conv2dクラスのインスタンスを直に作成して、それらにランダムなデータを与えてどのようにして最後の出力が1個のデータになるかを確認するコードがあります)。
これにMNISTの手書き数字を入力すると、以下のような出力が得られます。

ここではMNISTの手書き数字を読み込んで処理をしているので、出力が1(正しい)となるように学習をしていく、というのは前回に見た通りです。また、この画像から分かる通り、識別器からの出力は1個だけの要素を格納する深くネストしたテンソルとなっているので、train関数の内部ではreshapeメソッドで配列のネストを取り除いています。
生成器のコードは次のようになります。
zsize = 100
feature_maps = 16
generator = nn.Sequential(
nn.ConvTranspose2d(zsize, feature_maps * 4, 4, 1, 0, bias=False),
nn.ReLU(),
nn.ConvTranspose2d(feature_maps * 4, feature_maps * 2, 4, 2, 1, bias=False),
nn.ReLU(),
nn.ConvTranspose2d(feature_maps * 2, feature_maps, 4, 2, 1, bias=False),
nn.ReLU(),
nn.ConvTranspose2d(feature_maps, 1, 2, 2, 2, bias=False),
nn.Tanh()
)
netG = MakeFrom(generator)
生成器では、ConvTranspose2dクラスを用いて、入力データ(zsize個=100個のランダムな値)を段階的に拡大して、28×28=784次元のデータとなるようにしているだけです。生成器の活性化関数としてReLUを使っているのも元論文に合わせたものです。
こうして作成した生成器にランダムなデータを与えてみた結果が以下です。

まだ何も学習をしていないので、グレーの画像となりました。学習によって、このグレー画像がMNISTの手書き数字っぽくなるようにするのが今回(前回から)の目的です。
実際に学習を行うには、先ほども述べたようにtrain関数を呼び出すだけです。
EPOCHS = 80
losses_netD, losses_netG = train(netD, netG, batch_size, zsize, EPOCHS, trainloader)
train関数に渡している引数は上で作成した2つのニューラルネットワークモデル、データローダーから一度に読み込むミニバッチのサイズ(batch_size=100)、画像を生成する際に基となる潜在変数の要素数(zsize=100)、学習を行うエポック数(EPOCHS=80)、データ読み込みに使用するデータローダー(trainloader)となっています。
実行結果は次のようになりました。ここでは幾つかの画像だけを抜き出してお見せします(この後は学習が終わった後で生成されたものだけとします)。

次第にそれっぽい画像となっているのが分かります。一方、前回の全結合型のGANで生成したのは次のようなものでした(一部を抜粋)。
どちらがよいかと聞かれたら、それはDCGANの方ではないでしょうか。とはいえ、それほどキレイな画像ともいえません。そこでもう少し工夫をしてみます。
Copyright© Digital Advantage Corp. All Rights Reserved.