5分で分かる機械学習(ML):5分で分かるシリーズ(1/2 ページ)
機械学習をビジネスで活用したい人に向け、最新技術情報に基づき、機械学習の概要、統計学との違い、機械学習の作業フローと学習方法、回帰/分類/クラスタリング/次元削減に使える手法、次の一歩を踏み出すための参考情報を、5分で読めるコンパクトな内容で紹介する。
本稿は、2021年4月5日に公開した記事を、2022年4月14日の最新情報に合わせて改訂したものです。ローコードやノーコードに関する情報の追記などのアップデートを行いました。
1分 ―― 機械学習 (ML:Machine Learning)とは
人間が経験から学ぶように、機械がデータから学習することを機械学習(ML)と呼びます。例えば犬や猫の画像データから「あれが犬」「これが猫」と判断できるように学習することなどです。これは人間の子供に犬や猫を見せて「あれが犬」「これが猫」と覚えさせるのに似ていますね。
「5分で分かる人工知能(AI)」でも説明しましたが、機械学習には例えば、回帰分析や主成分分析、決定木、サポートベクタマシン、ディープラーニング(=ニューラルネットワークという仕組みを発展させたもの)など多くの手法(後述)があります(図1)。

統計学と機械学習の違い
回帰分析や主成分分析と聞いて、統計学の多変量解析を思い浮かべたかもしれません。実際に、一部の統計学の手法は機械学習でも使用します。しかし、統計学はデータを分析してインサイト(=内在する本質)を得ることを重視しているのに対し、(人工知能における)機械学習は何らかの手法/アルゴリズムを用いてデータから予測することを重視している点が異なります。分析重視か活用重視かという微妙な違いですが、これはそのままデータサイエンスと人工知能の違いでもあります。
データサイエンスと人工知能の違い
データサイエンスでは、統計学/機械学習/数理モデルに基づくデータ分析によって、データからインサイトを得ることが主目的です。例えば「Webサイトのクリックデータを分析して何らかのインサイトを得る」ような分析作業はデータサイエンティストの得意分野です。
それに対し、人工知能を実現するための機械学習では、データから予測することが主目的となります。例えば「Webサイトのクリックデータからお勧めの商品を提示するレコメンデーション機能を実装する」ような活用作業は機械学習エンジニアの得意分野です。他には、手書き文字の認識、顔認識、画像生成、翻訳エンジン、テキスト生成、自動運転、ロボット制御なども、「データ分析でインサイトを得たい」というよりも「データからの予測を行う機能(=機械学習モデル)を活用したい」という目的の方が強いと考えられるので、機械学習エンジニア向きの作業といえます。
ビジネスで機械学習を採用する際には、どちらの目的を重視するかを意識して人選や発注をするとよりよいでしょう。本稿では、人工知能における機械学習の内容について掘り下げて説明していきます。
2分 ―― 機械学習(ML)の作業フローと学習方法
作業フロー
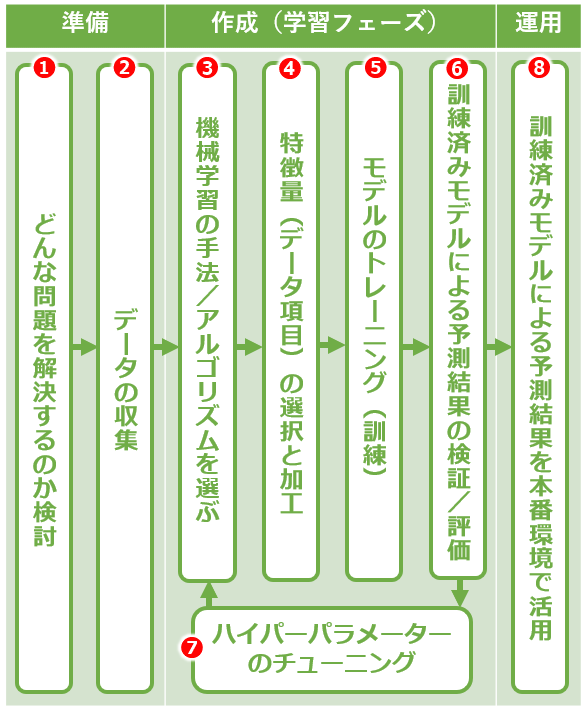
まず準備として、(1)解決したい問題を定義し、(2)使うデータを収集します。
次に機械学習のモデルを作成します。モデルとは、入力されたデータから「予測値」を出力するもの(その中身は計算式/計算方法)のことです。
(3)機械学習の手法/アルゴリズムを選択し、(4)そこで使うデータ項目(=特徴量)を選択/加工します(=特徴量エンジニアリング)。例えば重回帰分析という手法を選択し、間取り/築年数/駅からの距離といった特徴量を選択/加工するなどです。
なお従来の機械学習では、特徴量エンジニアリング次第で結果が変わるので職人技の見せどころでした。ディープラーニングでは、内部のネットワーク構造に特徴量が自動的に抽出/表現されるため、特徴量に関する作業は軽減されたものの、ネットワーク構造の設計が重要になっています。
(5)訓練用データでモデルをトレーニングします(=学習)。(6)訓練が済んだモデルに検証用データを入力して正しい出力が行えるか検証/評価します。
合格点に達しない場合、(7)特にディープラーニングでは内部のネットワーク構造や訓練方法に関する設定値(=ハイパーパラメーター)を調整して、(3)からやり直します。
合格点に達したら、ようやく運用開始です。(8)訓練済みモデルを本番環境で活用します。このフェーズは、(3)〜(7)の学習フェーズに対して推論と呼ばれます。
ちなみに最近では、学習フェーズの処理を自動化するAutoMLという技術が発展し普及してきています。また、ドラッグ&ドロップなどのビジュアル操作だけで、ほとんど/全くコードを書かずに機械学習を実現するローコードやノーコードと呼ばれるサービスが多数登場してきています。
学習方法
機械学習では、学習方法を基本的に下記の3つに分類します。
- 教師あり学習: データに正解値(ラベルと呼ぶ)があるときの学習方法。例えば「家賃」ラベルを含むデータから学習するなど(→家賃を予測するモデルができる)
- 教師なし学習: データにラベルがないときの学習方法。例えば学校のテスト結果データから学習するなど(→理系向き/文系向きなどのグループ分けを行うモデルができる)
- 強化学習: フィードバック(報酬・罰)で学習する方法。イメージとして例えば、犬にお座りができたら餌をあげることでお座りを覚えさせるのに似ている
ディープラーニングでは、学習方法が多様化して、教師あり学習か教師なし学習かに明確に分けづらくなっています。その代表例が、ラベルなしデータからラベルを自動生成して学習を行う自己教師あり学習で、2020年以降、人気が高まってきています。
さて次に、教師あり学習と教師なし学習に分けて代表的な機械学習の手法を紹介します。
3分 ―― 機械学習(ML)の代表的な手法 パート1(教師あり学習)
教師あり学習で行える代表的なタスク(問題種別)は、
- 回帰: ラベルが例えば「価格」のように(連続的な)数値である場合に、その数値を予測するタスク
- 分類: ラベルが例えば「花の種類」のように分類(=離散的な数値)である場合に、その分類を予測するタスク
です(「5分で分かる人工知能(AI)」の図4でも紹介済み)。

各タスクで使える機械学習の代表的な手法を紹介します。付記した概要文だけではよく分からないと思いますので、今回は「そういうのがあるのね」と名前だけ押さえてみてください。
回帰問題に使える手法
- 線形回帰/重回帰分析: 図3の左に示すようにデータに最もフィットする直線/平面/超平面を求める手法
分類問題に使える手法
- ロジスティック回帰: 線形回帰の出力をロジスティック関数(シグモイド関数とも呼ぶ)によって0か1かに振り分ける手法
- k近傍法(k-NN): 入力データに距離が最も近いk(数値を入れるパラメーター)個分の既存データから分類を判定する手法
- 単純ベイズ分類器: ベイズの定理という数学(確率論)を応用した手法。自然言語処理になるが迷惑メールを振り分ける技術として有名
回帰&分類問題に使える手法
- サポートベクタマシン(SVM): 図3の右に示すようにラベル犬とラベル猫の各データ群の境界に引く直線/平面/超平面を求める手法。分類で使うが、回帰にも応用できる
- 決定木: データを条件分岐で枝分かれさせていく手法で、トーナメント表のようなツリー(樹形図)が上から下に形成される。回帰では各条件の選択肢を数値ラベルに、分類では分類ラベルにする
- ランダムフォレスト: 複数の機械学習モデルを合体させるアンサンブル学習を決定木に適用した手法。木が森になって深化するので、大規模なデータセットでもより高い精度が期待できる
- 勾配ブースティング: アンサンブル学習(のブースティング法)を決定木に適用した手法。XGBoostやLightGBMというアルゴリズムが、競技大会「Kaggle」などの実践で好評
上記の手法は主に構造化データ(表形式データ)に用いられます。
非構造化データには、ディープラーニング(ニューラルネットワーク)がよく用いられます。もちろん構造化データにもディープラーニングは使え、最近ではTabNetなどの新手法が登場して注目されています。
目次
1分 ―― 機械学習(ML)とは(現ページ)
2分 ―― MLの作業フローと学習方法(現ページ)
3分 ―― MLの代表的な手法 パート1(教師あり学習)(現ページ)
4分 ―― MLの代表的な手法 パート2(教師なし学習)(次ページ)
5分 ―― まとめと、次の一歩のための参考情報(次ページ)
Copyright© Digital Advantage Corp. All Rights Reserved.