Hadoopに関する議論、今のテーマは「次は何か」だ:Gartner Insights Pickup(274)
Gartnerには、「ビッグデータ」に関する問い合わせが継続して寄せられているが、「Apache Hadoop」についての問い合わせは多くない。本稿では、Hadoopの現状と今後の動向について考察する。
ガートナーの米国本社発のオフィシャルサイト「Smarter with Gartner」と、ガートナー アナリストらのブログサイト「Gartner Blog Network」から、@IT編集部が独自の視点で“読むべき記事”をピックアップして翻訳。グローバルのITトレンドを先取りし「今、何が起きているのか、起きようとしているのか」を展望する。
Gartnerには、「ビッグデータ」についての問い合わせが継続して頻繁に寄せられている(もっとも、私はこの言葉がずっと嫌いだ)。だが、「Apache Hadoop」についての問い合わせは多くない。
過去24カ月にGartnerのデータ管理アナリストは、顧客からビッグデータについて数百件の問い合わせを受け、アドバイスをしてきた。1カ月当たりでは20〜30件程度で、これはかなりの量だ。
ちなみに、同じ期間に「データレイク」についての問い合わせは、その2倍以上あった(一部は重複している)。「レイクハウス」についての問い合わせは、その10分の1に満たず、主にここ数カ月間に寄せられている。ただし、件数は急増中だ。
Gartnerにとって、こうした動向を追跡することは市場の声を聞く良い方法だ。Gartnerはこのような動向を踏まえて調査範囲を設定し、調査の方向付けをし、注意を払っている。Hadoopについての問い合わせ動向も示唆に富んでいる。同じ期間のビッグデータについての問い合わせと比べて半分の頻度にとどまり、下のグラフが示すように、その傾向は明白だ。
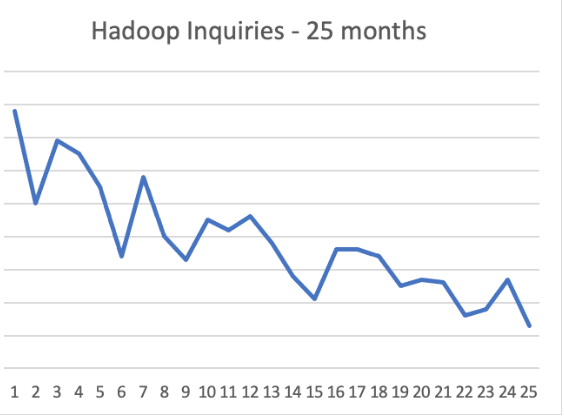
これには誰も驚かないはずだ。Clouderaは8年前の2014年に、「Enterprise Data Hub」を発表した。この製品に関する同社のメッセージ発信は、急速に変化してきた。同社は“Hadoop”という言葉を使ったマーケティングから離れ、数年のうちに「Apache Spark」「Apache Kafka」「Apache Flink」「Apache NiFi」など、オープンソースで開発されている主要なソフトウェアへの対応をうたうようになった。競合他社も同様だった。
実際、Cloudera、Databricks、Dremio、Ververicaといったソフトウェアベンダーは、オープンソースコンポーネントの開発の進展に注目し続け、自社の商用製品の強化にそれらを利用し、その見返りとしてそれらのプロジェクトにコードを寄贈している。
統計データからは分からないが、Hadoopについての問い合わせの内容も変化している。Gartnerは2020年に「Hype Cycle for Data Management, 2020」の中で、HadoopへのSQLアクセスと、オブジェクトストアへのSQLアクセスへの関心が高まっていることを取り上げた。これは主に、Gartnerが受けていた問い合わせに基づいている。
この傾向が顕著だったことから、Gartnerは同じく2020年に「Analytics Query Accelerators」(アナリティクスクエリアクセラレータ)という新しいカテゴリーをカバーし始めた。このカテゴリーの製品は、最適化されていないデータレイクデータに対するクエリパフォーマンスの向上を約束するものだ。多くの場合、そのアクセラレーション技術はオープンソース製品をベースにしている。Gartnerのデータチームに対するHadoopについての問い合わせの多くは、このカテゴリーに入るようになった。
私は、その数カ月後に公開した最後の「Project Tracker」(プロジェクト追跡記録)で、商用Hadoop製品にさまざまなオープンソースプロジェクトのどのバージョンが含まれるかをまとめた表を更新した。それ以降に寄せられたHadoopについての問い合わせは、オリジナルのHadoopツールセットで使用するために最初に集めたデータをどこに置くべきか、そしてどの新しいツールを使用すべきかを尋ねるものが多くなっている。
Apache Hadoopは消え去るどころか、開発も活発
例えば、Sparkが、Hadoopで処理されていたようなコンピュートワークロードの多くを処理しているのは明らかだ。同じ期間にGartnerに寄せられたSparkについての問い合わせは、1120件に急増しているが、その4分の3以上はデータ管理チーム以外のアナリストが対応している。コンピュートとストレージの分離が進んでいることが、以前はHadoopについてだった質問を「誰がするか」、それに「誰が答えるか」から感じられる。
今ではコンピュートとストレージは別々の問題であり、多くの場合、担当チームも別々だ。コンピュート系の担当者は、データチームによって用意されるデータストアに、オープンAPIでアクセスできることを期待している。市場で提供されているストレージ層の製品は、そうした期待に応えていくだろう。もう1つのリファクタリングが進みそうだ。
だが、Apache Hadoopは決して消え去ってはいない。まだ、かなり活発に開発が行われている。2020年7月にVersion 3.3.0がリリースされ、その後も3.3系で幾つかのマイナーアップデート版が公開されている。Apacheサイト(外部リンク/英語)では、Hadoopの構成要素である「MapReduce」「HDFS(Hadoop Distributed File System)」「Yarn」のそれぞれについて定義されており、これらは継続的な価値を提供し、重要なインストールベースを持っている。
しかし、Hadoopは先が見えている。MapReduceは、もはや望ましいツールではない。HDFSは、ストレージ層で多くのライバルに直面している。Yarnは、Hadoop環境以外ではあまり見かけないが、他のオープンソースのリソース管理ツールは、減少しているオンプレミス環境でしのぎを削っている。もはやHadoopうんぬんではなく、「次は何か」が重要なテーマだ。
出典:The Hadoop Conversation Is Now About What’s Next(Gartner Blog Network)
筆者 Merv Adrian
VP Analyst
Copyright © ITmedia, Inc. All Rights Reserved.