[pandas超入門]Pythonでデータ分析を始めよう! データの読み書き方法:Pythonデータ処理入門(2/2 ページ)
Pythonでデータ処理を始めようという人に向けて、pandasとは何か、インストール、データセットの読み込みと書き込み、簡単なメソッド呼び出しまでを説明します。
データセットの読み込みと書き込み
先ほど、Irisデータセットを変数dfに格納しましたが、そこではpandas.read_csv関数を使いました。これはCSVファイル(カンマで個々のデータを区切って並べたテキストファイル)からデータセットを読み込むための関数です。ですが、世の中にはCSVファイル以外にもさまざまな種類のデータセットが存在しています。そこで、pandasでは多くの種類のデータファイルからデータセットを読み込めるようにいろいろな関数が用意されています。以下はその一例です。
| ファイル形式 | 読み込みに使う関数 | 書き込みに使うメソッド |
|---|---|---|
| CSVファイル | pandas.read_csv関数 | pandas.DataFrame.to_csvメソッド |
| Excelファイル | pandas.read_excel関数 | pandas.DataFrame.to_excelメソッド |
| pandasがサポートしているファイル形式と読み書きに使う関数およびメソッド(一部) | ||
注意点としては読み込みに使うのは関数、書き込みに使うのはDataFrameが持つメソッドになっていることかもしれません(が、すぐに慣れるでしょう)。また、本連載では「import pandas as pd」とpandasをインポートしているので、実際に関数を呼び出すときには「pd.read_csv(……)」となる点にも留意してください。
この他にもJSONファイルやXMLファイル、HTMLファイルなどを対象にデータセットを読み書きすることも可能です。が、ここでは上で紹介した2種類のファイル形式の読み書きについて見ていくことにします。
CSVファイルの読み込み
既にコードは出てきましたが、まずはCSVファイルからデータセットを読み込むpandas.read_csv関数を紹介します。なお、以下で紹介するのは関数やメソッドの代表的なパラメーターのみとします。全てのパラメーターについては上記リンクを参照してください。
pandas.read_csv関数
pandas.read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col,
usecols, dtype, skiprows, nrows, encoding)
CSVファイルからデータセットをDataFrameオブジェクトに読み込んで、それを戻り値とする。代表的なパラメーターは以下の通り。ただし、パラメーターに設定できる値は以下の説明よりも幅広いので、詳しくは「pandas.read_csv」を参照のこと。
- filepath_or_buffer:CSVファイルの位置を表す文字列など。省略不可
- sep:読み込み対象のファイル(CSVファイル)でデータの区切りに使われる記号。省略時のデフォルト値はカンマ「,」
- delimiter:sepパラメーターの別名
- header:列ラベルを格納する行の行番号。単一の整数値、整数値のシーケンス(リストなど)、'infer'(列名を推測する)、Noneを指定可能。省略時のデフォルト値は'infer'。CSVファイルにヘッダ行がないときにはheader=Noneとしないと、第0行が列ラベルとして扱われることがあるので注意。逆にヘッダ行があるときに、namesパラメーターに列ラベルを指定するとともに、header=0を指定することでヘッダ行の内容をnamesパラメーターの内容で上書きできる
- names:列ラベルの指定。CSVファイルにヘッダ行があるときに、headerパラメーターに0を渡し(header=0)、このパラメーターに列ラベルを指定することでヘッダ行の内容を上書きできる
- index_col:行ラベルとする列の指定。CSVファイルに行ラベルがないと、そのままでは第0列が行ラベルとして扱われるが、これを抑制したいときにはindex_col=Falseを指定する
- usecols:CSVファイルからどの列のデータをDataFrameオブジェクトに読み込むかの指定。省略時は全ての列を読み込む。例:usecols=[0, 1, 2]とすると、第0列、第1列、第2列の内容が読み込まれる
- dtype:CSVファイルから読み込むデータの型の指定。例:全ての要素が浮動小数点数であれば「dtype=float」などのように指定する。また、列ごとにデータ型を指定するのであれば、辞書に列ラベルとその列のデータ型を指定する(例:dtype = {'col0': float, 'col1': int})
- skiprows:CSVファイルの先頭行から何行のデータを読み飛ばすかの指定
- nrows:CSVファイルから何行のデータを読み込むかの指定
- encoding:CSVファイルのエンコーディングの指定
先ほども見ましたが、pandas.read_csv関数を使ってCSVファイルからデータセットを読み込むコードの例を以下に示します。
names=['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width', 'class']
df = pd.read_csv('iris.data', names=names, index_col=False)
この例ではnamesパラメーターにIrisデータセットのドキュメントを基にした列ラベルを渡し、index_col=FalseとすることでCSVファイルに行ラベルがないことを指示しています(実行結果は省略します)。
CSVファイルからの読み込みについては「CSVファイルから読み込みを行うには(pandas編)」も参照してください。
CSVファイルへの書き込み
CSVファイルへのDataFrameオブジェクトの書き込みにはpandas.DataFrame.to_csvメソッドを使用します。
pandas.DataFrame.to_csvメソッド
pandas.DataFrame.to_csv(path_or_buf, sep, na_rep, columns, header, index,
index_label, encoding, quoting, quotechar)
DataFrameオブジェクトの内容をCSVファイルに書き込む。主要なパラメーターは以下の通り。ただし、パラメーターには以下の説明よりも幅広い値を設定できるので、詳しくは「pandas.DataFrame.to_csv」を参照のこと。
- path_or_buf:書き込み対象のファイルを表す文字列など。省略時は書き込む内容が文字列として返される
- sep:CSVファイルで使われる区切り文字。長さ1の文字列とすること。省略時のデフォルト値はカンマ「,」
- na_rep:欠損値の表現を示す文字列。省略時は空文字列
- columns:書き込み対象の列の指定
- header:列ラベルをCSVファイルのヘッダ行に書き込むかどうかの指定(Trueなら書き込み、Falseなら書き込まない)。文字列を要素とするリストを指定すると、リストの内容がヘッダ行に書き込まれる。省略時のデフォルト値はTrue(書き込む)
- index:行インデックスを書き込むかどうかの指定(Trueなら書き込み、Falseなら書き込まない)。省略時のデフォルトはTrue(書き込む)
- index_label:列ラベルとして書き込む行ラベルの指定。このパラメーターをNoneとして、かつheaderパラメーターとindexパラメーターにTrueを指定するとインデックス名が使用される。index_label=Falseとすると行ラベルが書き込まれない
- encoding:CSVファイルのエンコーディングの指定
- quoting:CSVファイルに書き込む各要素を何らかの引用符で囲むかどうかの指定。指定可能な値はPythonに標準添付のcsvモジュールで定義されている定数
- quotechar:各要素を囲む引用符の指定。長さ1の文字列とすること。省略時のデフォルト値はダブルクオート「"」
CSVファイルへの書き込み例を以下に示します。
df.to_csv('csv_sample.csv', header=['a', 'b', 'c', 'd', 'e'], index=False)
この例では、「header=['a', 'b', 'c', 'd', 'e']」として列ラベルの上書きを指定するとともに、「index=False」として行インデックスを書き込まないことを指定しています。実際に作成されたCSVファイルがどんなものかを確認してみましょう。
from pathlib import Path
print(Path('csv_sample.csv').read_text())
実行結果を以下に示します。

pandas.read_csv関数とpandas.DataFrame.to_csvメソッドはパラメーターが多数あるので、いろいろと試しながら、普段の自分の使い方にあった設定を探し出すようにしましょう。
Excelファイルの読み込み
Excelファイルを対象としたDataFrameオブジェクトの読み書きにはpandas.read_excel関数を使用します。
pandas.read_excel関数
pandas.read_excel(io, sheet_name, header, names, index_col, usecols,
dtype, skiprows, nrows)
Excelファイルの内容をDataFrameオブジェクトに読み込む。主要なパラメーターは以下の通り。また、パラメーターに指定可能な値は以下の説明よりも幅広いので、詳しくは「pandas.read_excel」を参照のこと。
- io:読み込み対象のExcelファイル
- sheet_name:シート名を表す文字列、シート位置を表す整数値などを指定可能。省略時のデフォルト値は0(最初のシート)
- header:列ラベル(ヘッダ行)として使用する行を表す整数値。ヘッダ行がないときにはNoneを指定すること。省略時のデフォルト値はNone
- names:列ラベルを要素とするリスト
- index_col:作成されるDataFrameオブジェクトで行ラベルとして使用する列の指定。Excelファイル内にそうした列がなければNoneを指定する。省略時のデフォルト値はNone
- usecols:全ての列をパースするならNoneを指定する。または、Excelファイル内で使用する列に対応する列名("A:E"など)を指定することも可能。省略時のデフォルト値はNone
- dtype:DataFrameオブジェクトの各列のデータ型を、型名または列ラベルとその型を対とする辞書の形で指定する。省略時のデフォルト値はNone。
- skiprows:Excelファイルの先頭から読み飛ばす行の行数を指定
- nrows:読み込む行数の指定。省略時のデフォルト値はNone
Excelファイルからデータセットを読み込むコードの例を以下に示します(サンプルのExcelファイルは次に説明するpandas.DataFrame.to_excelメソッドで作成しています)。
df = pd.read_excel('excel_sample.xlsx', usecols='A:E', header=0)
df
実行結果を以下に示します(このとき、openpyxlモジュールが見つからなくて例外が発生したら、「pip install openpyxl」「py -m pip install openpyxl」などのコマンドを実行してopenpyxlモジュールをインストールしてください)。

Visual Studio Codeのウィンドウ下部にはExcelファイルの内容も表示してあります。これを見ると、A列からE列にデータが存在しているので、usecolsパラメーターに'A:E'を指定することで、全ての列のデータが読み込まれているということです。また、headerパラメーターには0を指定しているので第0行の内容が列ラベルとして使われていることも確認できました(列ラベルが'a'〜'e'になっているのは、以下で説明するpandas.DataFrame.to_excelメソッドの呼び出しサンプルでそのように指定しているからです)。
余談ですが、Visual Studio Code内でのExcelファイルの表示にはExcel Viewer拡張機能を使用しています(入れておくと便利に使えるはずです)。
Excelファイルへの書き込み
Excelファイルへの書き込みにはpandas.DataFrame.to_excelメソッドを使います。
pandas.DataFrame.to_excelメソッド
pandas.DataFrame.to_excel(excel_writer, sheet_name, na_rep, columns, header,
index, index_label, startrow, startcol)
DataFrameオブジェクトの内容をExcelファイル(.xlsxファイル)に書き込む。主要なパラメーターは以下の通り(ここでは単一のDataFrameオブジェクトをExcelファイルに書き込むものとする)。また、パラメーターに指定可能な値は以下の説明よりも幅広いので、詳しくは「pandas.DataFrame.to_excel」を参照のこと。
- excel_writer:書き込み対象のExcelファイル
- sheet_name:DataFrameオブジェクトを書き込むシートの名前
- na_rep:欠損値の表記方法の指定。省略時のデフォルト値は空文字列
- columns:書き込む列の列ラベルを要素とするリスト
- header:ヘッダ行(列ラベル)を書き込むかどうかの指定(Trueなら書き込み、Falseなら書き込まない)。省略時のデフォルト値はTrue
- index:行ラベルを書き込むかどうかの指定(Trueなら書き込み、Falseなら書き込まない)。省略時のデフォルト値はTrue
- index_label:列ラベルとして書き込む行ラベルの指定。このパラメーターを指定せず、かつheaderパラメーターとindexパラメーターにTrueを指定するとインデックス名が使用される。index_label=Falseとすると行ラベルが書き込まれない
- startrow:DataFrameオブジェクトを書き込む左上のセルの列
- startcol:DataFrameオブジェクトを書き込む左上のセルの行
pandas.DataFrame.to_excelメソッドを使用して、Excelファイルに書き込みを行う例を以下に示します。
df.to_excel('excel_sample.xlsx', header=['a', 'b', 'c', 'd', 'e'], index=False)
ここではheaderパラメーターに「Petal Length」のような元々の列ラベルとは異なるものを指定しています。また、indexパラメーターにはFalseを指定しているので、行ラベルは出力されないはずです。
Excelファイルの内容は既に上の画像にもありますが、もう一度掲載しておきましょう。

と、ここまでCSVファイルとExcelファイルを対象に読み書きを行う方法を紹介してきました。なぜ読み書きが最初の話題かというと、pandasを使って何かする以前にデータセットは別の方法や別の形で存在していることがよくあるからです(どこかのWebサイトからダウンロードしたり、別の手法でデータを収集して、それを基に一定の形式の表形式データセットを作成したりするなど)。
そうしたデータセットを今から使おうというときには、今紹介した関数のお世話になることでしょう。さらに、自分の作業に適した形に、それをpandasで加工して、保存しておきたくなったときには書き込み用のメソッドが必要になります。そういうわけで、ここではデータセットの読み書きについて話しました。
読み込んだデータを調べてみよう
読み書きの方法が分かっただけでは物足りないかもしれません。最後に読み込んだデータセットを調べる方法を幾つか簡単に見ておきましょう。ここでは以下のメソッドを紹介します。
- pandas.DataFrame.headメソッド:DataFrameオブジェクトの先頭n行を表示(デフォルトは5行)
- pandas.DataFrame.infoメソッド:DataFrameオブジェクトの概要を表示
- pandas.DataFrame.tailメソッド:DataFrameオブジェクトの末尾n行を表示(デフォルトは5行)
といっても、DataFrameオブジェクトを対象に引数を指定せずに呼び出すだけです(そのため、実行結果のみの掲載とします。また、変数dfには本稿冒頭で示したのと同じコードを実行して元々のデータセットから作成したDataFrameオブジェクトを代入しています)。
pandas.DataFrame.headメソッドはDataFrameオブジェクトの先頭n件(デフォルトでは5件)のデータを表示するものです。以下に呼び出し例を示します。
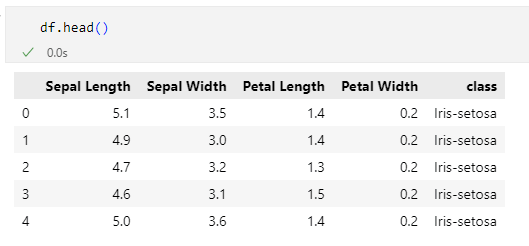
先頭のデータを見るだけだなんて、意味はないよ、と思う方もいらっしゃるでしょうが、これはDataFrameオブジェクトへのデータセットの読み込み後に、ちゃんと読み込めているかどうかの確認だったり、読み込み時のデータ型の指定に間違いはないかどうかの確認だったりという意味でこのメソッドを実行することもよくあります。
pandas.DataFrame.infoメソッドは、読み込んだデータセットの概要をコンパクトにまとめて表示してくれます。以下が実行例です。
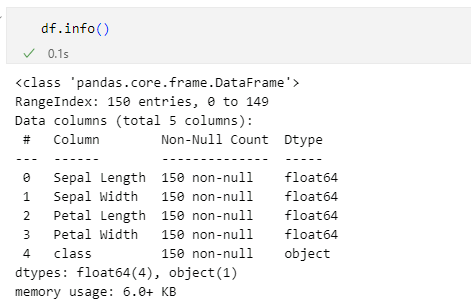
「RangeIndex」からはデータ数が分かります。その次に、各列の列ラベルと欠損していないデータが何件あるか、その列に格納されているデータの型が表示されています。float64というのは、実数(浮動小数点数)のことで、objectというのは数値ではないデータであることを示しています(あやめの種類を示す「Iris-setosa」のような文字列は数値ではないのでobject型のデータとなっています)。
そして、DataFrame全体でfloat64型の列が4つ、object型の列が1つあることも分かりました。最後にメモリの使用量も表示されました。
このメソッドもデータセットを読み込んだ直後に、それがどんなものなのかを軽く確認する目的で実行することがよくあります。
最後のpandas.DataFrame.tailメソッドの実行例も見てみましょう。
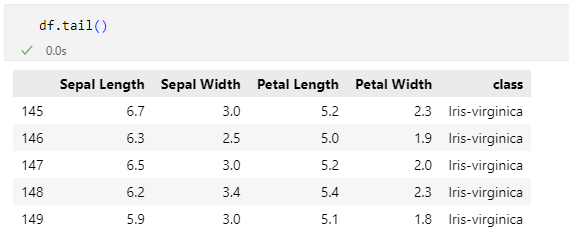
このメソッドは、pandas.DataFrame.headメソッドとは逆に、DataFrameオブジェクトの最後のn件(デフォルトでは5件)を表示するものです。これは例えば、行を並べ替えるなどしたときに、自分の意図通りに並べ替えができたかどうかを確認するといった目的で使うことがあります。
ここまでpandasとは何か、DataFrameとSeries、データセットの読み書きの方法、DataFrameオブジェクトが持つ幾つかのメソッドなどを見てきました。次回はDataFrameとSeriesについてもう少し詳しく見ていく予定です。
Copyright© Digital Advantage Corp. All Rights Reserved.