[pandas超入門]Pythonでデータ分析を始めよう! データの読み書き方法:Pythonデータ処理入門(1/2 ページ)
Pythonでデータ処理を始めようという人に向けて、pandasとは何か、インストール、データセットの読み込みと書き込み、簡単なメソッド呼び出しまでを説明します。
本シリーズと本連載について
本シリーズ「Pythonデータ処理入門」は、Pythonの基礎をマスターした人を対象に以下のような、Pythonを使ってデータを処理しようというときに便利に使えるツールやライブラリ、フレームワークの使い方の基礎を説明するものです。
- NumPy(「NumPy超入門」の目次はこちら)
- pandas(本連載)
- Matplotlib
Pythonだけを覚えれば何でもできるわけではない、というのはハードルが高く感じられるかもしれません。それでもプログラミング言語に関する基礎が身に付いたら、後は各種のツールを使いながら、言語とツールに対する理解を少しずつ、しっかりと深めていくことで自分がやれることも増えていきます。そのお手伝いをできたらいいな、というのが本シリーズの目的とするところです。
なお、本連載では以下のバージョンを使用しています。
- Python 3.12
- pandas 2.2.1
pandasとは
pandasはデータ分析やデータ操作を高速かつ柔軟に行える便利なツールで、多くの人たちに使われています。機械学習やディープラーニングにいざ取りかかろうというときには、その前に対象とする大量のデータ(データセット)についての知見が必要になります。つまり、読み込んだデータを整形して扱いやすいものにしたり、データの操作を通してそれまでは目に見えなかった特徴を探ったりする必要があります。この段階でpandasはとても役に立つツールといえるでしょう。

NumPyもまた大量のデータを高速に処理できるツールですが、pandasとの違いがどこにあるかといえば、NumPyはどちらかといえば数値計算、科学計算のための基盤であり、pandasはその基盤の上でデータを分析するためのツールといえるかもしれません。
また、NumPyの多次元配列には基本的に同じ型のデータしか格納できませんが、pandasではDataFrameに異種データを格納できます。速度面ではNumPyの方が優位にあるかもしれませんが、データ分析における柔軟性という面ではさまざまな種類のデータをひとまとめにして扱えるpandasの方が優位にあるといえるでしょう。pandasでは基本的に2次元の表形式データを扱うことが主ですが、NumPyでは3次元以上のデータも扱える点も異なっています。つまり、どちらが上でどちらが下という話ではなく、両者は得意とする分野が異なっているとも表現できます。
とはいえ、NumPyとpandasは密接に関係していて、pandasのデータ(DataFrameオブジェクト)をNumPyの多次元配列(ndarray)に変換することも、その逆も可能です。より高速な計算が必要であればNumPyの機能を、柔軟なデータ操作が必要であればpandasの機能を使うといった切り分けが重要になるかもしれません。いずれにしても、これらはPythonでデータ処理をする上では欠かせないツールですから、自分がよく使う部分から徐々に身に付けていくことをお勧めします。
pandasのインストール
pandasはPythonに標準で付属していないので、使う前にはインストールが必要です。といっても、Pythonに慣れているのであれば、いつもと同じpipコマンドを使うだけです。例えば、次のようなコマンドラインを実行すればよいでしょう。OSや環境によっては「pip」ではなく「pip3」コマンドになっているかもしれません。
$ pip install pandas
Windows環境でPythonを使っていて、pythonコマンドやpipコマンドがあるディレクトリを環境変数PATHに含めていなければ、次のようなコマンドになるかもしれません(python.orgで配布されているPython処理系を使用している場合)。
> py -m pip install pandas
インストールしたpandasをPythonのコードから使うにはインポートする必要があります。
import pandas as pd
pandasをインポートする際には「import pandas as pd」のようにするのが慣例となっています(英語版のWikipediaによれば、pandasの名前が「panel data」という用語に由来するそうです。なので、この2語から「pd」を略称として使用するようになったのかもしれませんね)。
pandasで扱えるデータ
pandasは主に「表形式データ」(tabular data)と呼ばれる種類のデータの取り扱いを得意としています。表形式データとは行と列で構成されるデータのことです。例えば、表形式データの列が身長、体重、年齢、喫煙者か否かなどを表し、行がそれらをひとまとめにした1件のデータを表すといった形式のデータのことです。
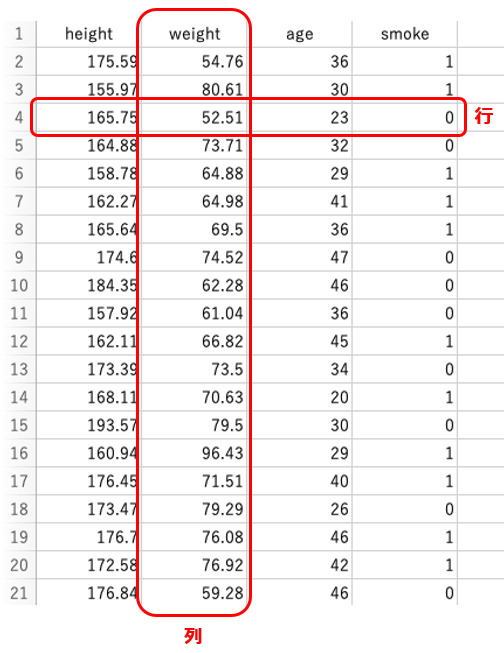
pandasでは、このようなデータをSeriesとDataFrameという2種類のデータ構造を使用して表現します。Seriesは軸ラベルを持った1次元の配列のことで、DataFrameは2次元の配列でサイズは可変であり、さまざまな型のデータを格納できます。DataFrameはSeriesの集合体である(1次元の配列が集まって、2次元の表形式データを構成している)と考えることもできるでしょう。
SeriesとDataFrame
以下は、https://archive.ics.uci.edu/dataset/53/irisで配布されている3種類のあやめの特徴をデータセットにまとめた「irisデータセット」をpandasが提供するpandas.read_csv関数を使って読み込み、そこに含まれているデータを幾つか表示するコードです(以下、コードも示しますが、別にその意味を知る必要はありません。「ふーん」と読み進めてくだされば大丈夫です)。
import pandas as pd
names=['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width', 'class']
df = pd.read_csv('iris.data', names=names, index_col=False)
df.head()
Visual Studio Codeでこれを実行した結果は次の通りです。

先頭に表示されているのはCSVファイルには含まれていない各列のデータが何かを示す列ラベルです。また、左端の列にはそれが何行目のデータを示す行ラベル(インデックス)が付加されています。
あやめはその種類ごとに花びら(petal)とがく片(sepal)の長さと幅が異なります。そこで、花びらとがく片の長さと幅を分析することで、それがどの種類のあやめかを判断できるのです(詳しくは「Iris Dataset:あやめ(花びらとがく片の長さと幅の4項目)の表形式データセット」を参照してください)。
といっても、ここでは読み込んだだけで、分析はしません。あくまでも先ほどお話ししたSeriesとDataFrameがどんなものかを確認するためにしていることです。
読み込んだデータセットは変数dfに代入されていますが、これが何のオブジェクトかを調べてみましょう。
print('type of df:', type(df))
実行結果を示します。
実行結果を見ると、読み込んだデータセットはDataFrameオブジェクトに格納されていることが分かりました(「pandas.core.frame.DataFrame」というのは「pandasパッケージのcoreモジュールにあるframeサブモジュールにあるDataFrameクラス」を意味しますが、ここでは単純にDataFrameとしましょう)。ここで本当に、DataFrameがSeriesの集合体かどうかを調べてみましょう。
df['Sepal Length']
このコードは今見たDataFrameオブジェクトから'Sepal Length'列のデータを取り出して表示しているものです。
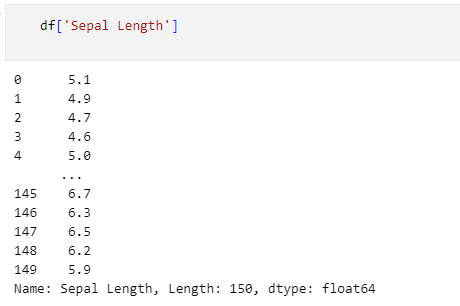
上から順に5.1、4.9、4.7、4.6、……と先ほどDataFrameオブジェクト全体を表示したときの'Sepal Length'列の値と同じものが表示されています。そこで次のコードを実行してみましょう。
s = df['Sepal Length']
print("type of df['Sepal Length']:", type(s))
実行結果は次のようになりました。

実行結果から、確かにこれがSeriesオブジェクトになっていることが分かりました。
このように、pandasではDataFrameとSeriesという2つのクラスのオブジェクトを使ってデータセットを取り扱っていきます。これらのクラスにはさまざまなメソッドが用意されていて、読み込んだデータセットをシンプルに分析、操作できます。また、pandasパッケージにもデータセットを操作するための関数が数多く備わっています。それらについては連載の中で触れていくこととして、まずはデータセットを手に入れて、操作するために必要なもの、つまりデータセットの読み書きに使う関数を紹介しましょう。
Copyright© Digital Advantage Corp. All Rights Reserved.