
分散メモリ型並列処理システムにおける並列化
最近あまり聞かれなくなってしまいましたが、ベオウルフシステム(Beowulf System)という言葉をご存じでしょうか。
複数の計算機で構成された分散メモリ型並列処理システムの中でも、構成要素がコモディティ製品で構成されたシステムのことを指し、一時期、HPCの分野で流行した言葉です。
最初のベオウルフシステムが登場したのは1993年。16個のIntel 486 DX4プロセッサを持つ計算機を10Mbit/sのイーサネットで結び、各計算機のOSとしてLinuxを用いたものでした。
| 関連リンク: | |
| Beowulf.org: The Beowulf Cluster Site http://www.beowulf.org/ |
|
ベオウルフシステムが流行した背景には、従来のスーパーコンピューターと呼ばれる特殊なシステムに対して、コンシューマ向けPCの能力が劇的に向上したことがあります。市販のPCをイーサネットでつなぎ、無償であるLinuxやBSD系OSで動かせば、非常にコストパフォーマンスに優れたシステムが完成します。
現在では、コモディティ製品で構成された小〜中期模並列処理システムも、ブレードサーバに代表されるような高性能・高信頼性サーバで構成された大規模な並列処理システムも、どちらもまとめてクラスタサーバと呼ばれることが多いようです。これらクラスタサーバが、分散メモリ型並列処理システムのもっとも典型的な例ということになります。
クラスタサーバは、破壊的イノベーションの典型といってもよいもので、従来までのスーパーコンピュータの典型であったMPP(Massively Parallel Processor:超並列計算機)システムが、一気にクラスタサーバシステムにとって代わられてしまった感があります。
実際、2008年11月現在の世界のスーパーコンピュータトップ500リストによれば、トップ500にランクインしたシステムのうち、MPPが17.6%なのに対し、クラスタサーバは82%にもなります。
Message Passing Interface
前置きが長くなりました。ソフトウェアの話に戻りましょう。クラスタサーバに代表される分散メモリ型並列処理システムで、1つの問題を複数の計算機(計算ノードと呼ばれます)に割り振るための並列処理ライブラリはいくつかあります。その中でもっともよく使われていて、標準的なものは、MPI(Message Passing Interface)でしょう。
| 関連リンク: | |
| MPI Forum http://www.mpi-forum.org/ |
|
MPIでよく使われるプログラミングモデルは、SPMD(Single Program Multiple Data)です。これは、複数の演算ノードで同一のプログラム(Single Program)を動作させ、各演算ノードに固有のメモリ空間に配置された異なる複数のデータ(Multiple Data)を処理させるというものです。
ここで注意すべき点が2つあります。1つは“同一のプログラム”といっても、すべての演算ノードでまったく同じ処理が行われるわけではないということです。プログラムに演算ノード固有の番号(正確には、各並列プロセスに固有の番号で、MPIではこれをrankと呼びます)を条件式とするIF文を使えば、同一のプログラムであっても各演算ノードに異なる動作をさせることができます。
注意点の2つ目は、“各演算ノードに固有のメモリ空間に配置された”といっても、必要なデータを各ノードに割り振るのは自動でやってくれるわけではなく、能動的に割り振る必要があるということです。演算のためのinputデータ、あるいは演算結果であるoutputデータは、メッセージパッシングという言葉のとおり、各計算ノード間で通信を行うことで、やり取りすることになります。
さて、実際にMPIのソースコードを見てみましょう。リスト2は、リスト1をMPIで並列処理したものです。
001: /*
002: * Array のインクリメント(MPI版)
003: */
004:
005: #include<stdio.h>
006: #include<stdlib.h>
007: #include "mpi.h"
008: #define N 16
009:
010: int main (int argc, char *argv[])
011: {
012: int i;
013: int *rootBuf;
014: int *localBuf;
015:
016: int nproc;
017: int myrank;
018:
019: char hostName[MPI_MAX_PROCESSOR_NAME];
020: int nameLength;
021:
022: int length;
023:
024: /* MPI セットアップ */
025: MPI_Init(&argc, &argv);
026: MPI_Comm_size(MPI_COMM_WORLD, &nproc);
027: MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
028:
029: MPI_Get_processor_name(hostName, &nameLength);
030: fprintf(stdout,": myrank=0, nproc=0\n", hostName, myrank, nproc);
031: fflush(stdout);
032:
033: /* 親ノード(root) のみ配列Initialize */
034: if(myrank == 0){
035: rootBuf = (int *)malloc(N * sizeof(int));
036: for(i=0;i<N;i++){
037: rootBuf[i] = i;
038: }
039: }
040:
041: /* 各ノード の作業用配列確保 */
042: length = N / nproc;
043: localBuf = (int *)malloc(length * sizeof(int));
044:
045: /* 各ノードへ演算データ分配 */
046: MPI_Scatter(rootBuf, length, MPI_INT, localBuf, length, MPI_INT, 0, MPI_COMM_WORLD);
047:
048: /* Incriment */
049: for (i = 0; i < length; i++) {
050: localBuf[i] = localBuf[i] + 1;
051: }
052:
053: /* 各ノードから演算結果収集 */
054: MPI_Gather(localBuf, length, MPI_INT, rootBuf, length, MPI_INT, 0, MPI_COMM_WORLD);
055:
056: /* 演算結果の出力 */
057: if(myrank == 0){
058: printf("\n");
059: for(i=0;i<N;i++)
060: printf("rootBuf[%d] = %d\n",i,rootBuf[i]);
061: }
062:
063: /* 終了処理 */
064: free(localBuf);
065:
066: if(myrank == 0){
067: free(rootBuf);
068: }
069:
070: MPI_Finalize();
071: return(0);
072: }
急に見慣れない関数がたくさん出てきて申し訳ありません。本記事は、並列処理の概要説明でMPIの解説記事ではないので、疑似コードでもよかったのですが、せっかくなのでコンパイルすればちゃんと動くものを掲載しました。とりあえず、あまり詳細にこだわらずに、こんなものかと思っていただければと思います。ポイントだけ簡単に説明します。
- 007行目:
- mpiの関数を使用するために指定するincludeファイルです
- 008行目:
- 配列の数を定義しています。本サンプルでは動作確認のために配列の中身を60行目ですべてprintfしていますので、16という小さい値を入れています
- 025〜027行目:
- MPIのセットアップです。おまじないだと思ってください
- 029〜031行目:
- ホストサーバ名、並列実行されるプロセッサの数、各ノードのrankを表示します
- 034〜039行目:
- 親ノード(rank=0で区別)のみ配列を確保し、初期化します
- 042〜043行目:
- 各並列ノードの作業用配列を確保します。作業領域は配列rootBufの大きさをノード数で割った値になります
- 046行目:
- 各ノードにデータを分割して配信します
- 049〜051行目:
- 行列の各要素を各ノードのローカルメモリ(localBuf)でインクリメントします
- 054行目:
- 各ノードのlocalBufから、親ノードのrootBufへ演算結果を集めます
- 070行目:
- mpiの終了処理です
処理の概念図を下に示します。詳しくは 『MPI並列プログラミング』(P. パチェコ著)などを参考にしていただくか、今後の連載でMPIを詳細に取り上げますので、そちらをお待ちいただければと思います。
●リスト2(MPI)の処理の概念図
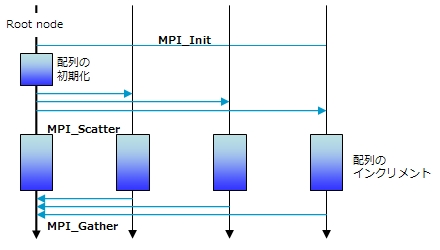
上記サンプルを実際にコンパイルして実行するためには、まずMPIライブラリをインストールする必要があります。フリーで使用できるMPIライブラリとしては、アメリカのArgonne National Laboratory(ANL)が開発したMPICHが有名です。
| 関連リンク: | |
| MPICH http://www.mcs.anl.gov/research/projects/mpi/mpich1/index.htm |
|
Webサイトからmpich.tar.gzをダウンロードして、展開後、READMEに従ってインストールして下さい。ただし、マシン1台でMPIを動かし、通信に共有メモリを用いる場合は、configureの際に、--with-comm=sharedを付けてください。念のため、Linux環境でのインストール例を示します。
$ make
コンパイルには、mpiccコマンドを使います。例えば、リスト2のソースファイルをlist2.cとすると、以下のようになります。
プログラムの実行はmpirunコマンドを使用します。例えば、4つの並列プロセスを走らせて演算を行う場合は以下のようになります。
ここで、-npオプションの引数「4」は並列プロセスの数になります。Nの数を変えてみたり、プロセスの数を変えてみたりしながら、並列実行の様子を確認してみてください。
残念ながらNの大きさを極端に大きくしたとしても、リスト2のようなサンプルで並列実行での速度向上を体感するのは難しいでしょう。分散メモリ型の問題点は、計算ノード間通信のオーバーヘッドが非常に大きいということにあります。
計算ノード間の通信経路として、通常のシステムではギガビットイーサネット、スーパーコンピュータではInfiniBandなどの、より高速な通信網が使用されますが、それでもノード間通信は演算処理やローカルメモリのI/Oに比べると極端に遅く、多くの場合システム全体のボトルネックとなってしまいます。
リスト2のような単純な計算をMPIで実装した場合、データを各計算ノードに送付するのに時間がかかる割には、ノード内部での計算量が少なく、速度が向上しないというわけです。よって、分散メモリ型では、いかに計算ノード間の通信をなくし、オーバーヘッドを少なくするかが大変重要になってきます。
2/3 |
| Index | |
| 並列処理を体感してみよう | |
| Page1 いまだからこそ“Think Parallel” 並列処理手法とは何か |
|
| Page2 分散メモリ型並列処理システムにおける並列化 Message Passing Interface |
|
| Page3 共有メモリ型並列処理システムにおける並列化 OpenMP |
|
| Think Parallelで行こう! |
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
注目のテーマ





