| NetDictionaryで始める Webサービス・プログラミング 2.ICDデータベースの構造
|
|

本連載の第1回目で解説しているように、ICD Webサービスは、Insider’s Computer Dictionary(ICD)として公開しているサービスに、Webサービスのインターフェイスを付けて公開しているものだ。ただしそこでも述べているように、ICDのWebページは、データベースからダイナミックにWebページを生成しているわけではなく、あらかじめ各単語ごとにスタティックなWebページとして保存し、それを表示している。しかし社内ではすべてのデータをデータベース化し、Visual Basic 6.0で開発したフロントエンド・プログラムにより、その編集と管理を行っている。ICD Webサービスは、このデータベース(データベース・サーバはSQL Server 2000)に直接アクセスしながら動作する(実際にはミラーリングしているデータベースにアクセスしている)。
ここでは、ICDのデータベースがどのようなテーブルから構成されており、また各テーブルの中にどのような項目があるのかを説明する。しかし、まずその前に、ICDデータベースに蓄えられているデータの主要な項目を、ICDでの検索結果を元に解説しておこう。
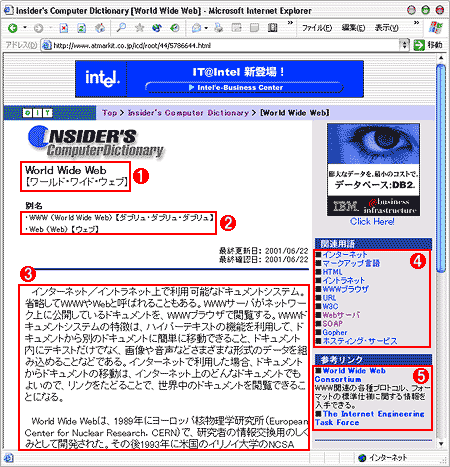
次の画面は「World Wide Web」をブラウザから検索した結果だ。
 |
|||||||||||||||
| ICDでの検索結果画面 | |||||||||||||||
|
ICDの用語解説画面では、まず少し大きなフォントで、検索した単語名が表示される(![]() )。これをICDでは「見出し語」と呼んでいる。見出し語のすぐ下には、もしあれば「別名」が表示されるが(
)。これをICDでは「見出し語」と呼んでいる。見出し語のすぐ下には、もしあれば「別名」が表示されるが(![]() )、これらもまた見出し語となっている(別名が存在しない場合は表示されない)。見出し語の意味を記す「説明」は(
)、これらもまた見出し語となっている(別名が存在しない場合は表示されない)。見出し語の意味を記す「説明」は(![]() )、この画面の場合では、3つの見出し語(「World Wide Web」「WWW」「Web」)と結び付けられている。また、画面右のグレー部分にある関連用語(
)、この画面の場合では、3つの見出し語(「World Wide Web」「WWW」「Web」)と結び付けられている。また、画面右のグレー部分にある関連用語(![]() )は、説明に関連付けられた見出し語の集まりである。同様にその下の参考リンク(
)は、説明に関連付けられた見出し語の集まりである。同様にその下の参考リンク(![]() )は、説明に関連付けられた別のページへのURLと、そのWebページのタイトル(ICDデータベース内部では、これも「見出し」と呼んでいる)の集まりとなっている。
)は、説明に関連付けられた別のページへのURLと、そのWebページのタイトル(ICDデータベース内部では、これも「見出し」と呼んでいる)の集まりとなっている。
こういった出力データの構造を踏まえた上で、ICDデータベースのテーブル構成を示している次のテーブル・ダイアグラムを見ていただきたい。
 |
| テーブル・ダイアグラム |
| ICDのデータベースのうち、6つの主要なテーブルを図示している。 |
この図は、ICDデータベースの主要な6つのテーブルとその関連を示している。例えば図中左上の「見出し語名」テーブルでは、5つのカラム(列)が定義されていることが分かる。ICDデータベースでは、このテーブルに5000を越えるレコード(行)が格納されている。
なお、ここで示したテーブルとカラムは、ICD Webサービスで使用しているものだけを示している。実際のICDデータベースは13個のテーブルからなっており、各テーブルには更新日時やメモなどのカラムも存在している。
次の図は、SQL Server 2000に付属するツールで、「見出し語名」テーブル・データの一部をのぞいている画面だ。
 |
| 「見出し語名」テーブル内のデータ |
| このテーブルは、ID、見出し語名、ソート、欧文読み、日本語読みのカラムを持っていることが分かる。画面から分かるとおり、すべてのカラムにデータが入っているわけではない。 |
ここで、各テーブルの役割について簡単に説明しておこう。「見出し語名」テーブル、「説明」テーブルそして「URL」テーブルは、そのカラムを見れば分かるように、それぞれ、「見出し語」「説明」「参考リンクとなるURL」を格納しているテーブルである。[見出し語名.ソート](説明上、例えば「見出し語名」テーブルの「ソート」カラムはこのように[見出し語名.ソート]と表記することにする)は、複数の見出し語名をソートして表示する際の、見出し語の「読み」がひらがなで(見出し語が英数字のものはそのまま英数字で)格納されている。また、[説明.有効]は、0または1のフラグとなっており、このカラムが0となっているレコードの説明は無効であることを示す。これは、編集が完了していないデータなどを示す(データベース中にはデータが保存されるが、Webページとしては公開しない)のに使用される。
残りの“R”で始まるテーブル名を持つ3つのテーブルは、上記3つのテーブル間の関連を管理しているテーブルである。それぞれにある「順番」カラムは、1つの説明に対して、例えば見出し語が複数存在する場合(つまり別名を持つ場合)に、その表示順を制御できるように1から始まる数値が入っている。
テーブル・ダイアグラムを見て分かるように、これらのテーブルの関係が必要以上に複雑になっている理由は、おそらく幾度かのバージョンアップによるものと思われる。おそらくというのは、筆者がこのデータベースを設計したわけではないからだ(設計した人間はもう近くにはいない)。このように既存の構造を維持しつつ、新しい項目を付け加えることによって、全体の構造がちぐはぐになっていくことは、実システムにおいてはよくあることだ。
テーブルの構造を解説したついでに、プログラムで必要となる検索処理についてもここで解説しておこう。ICD Webサービスのプログラムには、検索用のSQL文がいくつか含まれているが、それぞれを詳しく説明するのは本連載の目的からはずれるため、ここではとりあえず、入力された検索文字列を元に、その見出し語に関する情報を取得するSQL文だけを示す。この処理では、検索文字列に合致する[見出し語名.見出し語名]のレコードを「見出し語名」テーブルから検索するだけではすまない。なぜならその見出し語に対する説明が無効である場合には、その見出し語も無効となるからである。
|
|
| 検索文字列を元に見出し語に関する情報を取得するSQL文 | |
| 見出し語に対する説明が有効か無効かをチェックする必要があるため、少し複雑なSQL文なっている。 |
SQL文に馴染みのない方もいらっしゃると思うが、SQL文について詳しく解説するのは本稿の範囲を超えるので、ここでは例示したSQL文についてのみ簡単に説明しておこう。
- 「見出し語名」テーブルにおいて、検索文字列に合致する[見出し語名.見出し語名]を持つレコードを集める(11行目)。
- 「説明」テーブルにおいて、[説明.有効]が“1”すなわち有効なレコードを集める(14行目)。
- 上記1.と2.で集めたレコードのうち、「R見出し語名_説明」テーブルのいずれかのレコードによって連結できるようなレコードを、1.で集めたレコードから抜き出し(13行目)、そのレコードから「見出し語名」「ID」「欧文読み」「日本語読み」を取得する(2〜5行目)。
| INDEX | ||
| [特集]NetDictionaryで始めるWebサービス・プログラミング | ||
| 第4回 辞書データベースへのアクセス | ||
| 1.ヘルプ・ページのテンプレート | ||
| 2.ICDデータベースの構造 | ||
| 3.ADO .NETによるデータベース・アクセス | ||
| 4.ICD Webサービスのデータベース処理 | ||
| 特集 : NetDictionaryプロジェクト |
- 第2回 簡潔なコーディングのために (2017/7/26)
ラムダ式で記述できるメンバの増加、throw式、out変数、タプルなど、C# 7には以前よりもコードを簡潔に記述できるような機能が導入されている - 第1回 Visual Studio Codeデバッグの基礎知識 (2017/7/21)
Node.jsプログラムをデバッグしながら、Visual Studio Codeに統合されているデバッグ機能の基本の「キ」をマスターしよう - 第1回 明瞭なコーディングのために (2017/7/19)
C# 7で追加された新機能の中から、「数値リテラル構文の改善」と「ローカル関数」を紹介する。これらは分かりやすいコードを記述するのに使える - Presentation Translator (2017/7/18)
Presentation TranslatorはPowerPoint用のアドイン。プレゼンテーション時の字幕の付加や、多言語での質疑応答、スライドの翻訳を行える
|
|





