
J2EE開発のパフォーマンス管理術(後編)
システムの不具合を予防する方法
アイティ・フロンティア
西元信雄
2003/8/28
| LANゲーム実験店舗のシステムコンセプト |
「ローコスト」「24×7」「リアルタイムCRM」。これがLANゲーム実験店舗レッドゾーン(LEDZONE)のシステムコンセプトだ。ローコストとは、オープン技術を活用し、案件全体のコストを圧縮することを指す。とはいえ、システムの堅牢性は確保しなければならない。1日24時間、1週間7日の連続稼働は当然のことだ。さらに、運用状況をリアルタイムに監視し、システムの連続稼働を具体的な方面からサポートしなければならない(J2EE開発のパフォーマンス管理術 前編:システムの内部動作を視覚化する)。
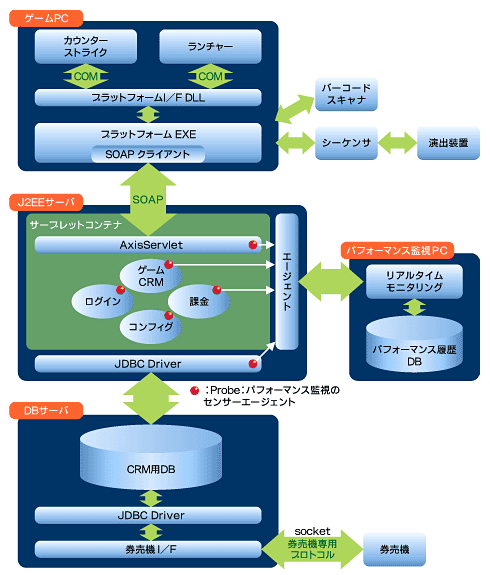 |
| 図1 LANゲーム実験店舗レッドゾーンのシステム構成 |
まず、システムアーキテクチャとアプリケーションの特徴を把握し、パフォーマンス管理の仮説モデルを設定する。パフォーマンス管理の側面において、ボトルネックの改善というポイント以外は、システムとアプリケーションのトレードオフと考えることができる。つまり、20分300円のLANゲームの店舗運営で利益を上げるには、初期投資を限りなく小さくすることが必須条件だ。一方で、24時間営業に耐えうる堅牢なシステムを構築しなければならない。さらに、最小限の投資で最大限のスループットを実現しなければならない。とすると必然的に、システムのパフォーマンスを厳重に管理し、調整していかなくてはならないという結果になる。
レッドゾーンの実際の構成を紹介しよう。J2EEサーバ(1CPU/2.4GHz)とDBサーバ(2CPU/2.4GHz)としてIAサーバを採用、搭載するOSはLinuxである。DBサーバを2CPUとしたのは、リアルタイムにCRM情報をDBサーバに書き込むためである。CPU数を多くすれば、リアルタイム性は高まるのだが、ハードウェアのコストと搭載するソフトウェアのコストがCPU数に比例して価格が高くなる。そのため、2CPUに絞らざるを得なかった。IAサーバはUNIXサーバより“動作のキレがよい”と感じるが、2.4GHzの限界負荷に到達すると頑張りがきかない傾向がある。そこで、CPUの限界を超えないようにパフォーマンスチューニングを施すことが、IAサーバを採用する重要な前提となってくる。
システムの重要なポイントとして、PCとサーバ間の通信にSOAPを採用している点が挙げられる。レッドゾーンはLANゲームのあらゆる可能性を試すプロジェクトである。ゲームシステムのCRMデータと店舗運営の情報は刻々と変化する。システム変更に強いシステムを実現するためにSOAP(XML)を実験的に組み込んだ。しかし、SOAPのパフォーマンスはシステム全体に重要な影響を与えることを考慮しなければならない。この点もパフォーマンス管理の重要なポイントになるだろう。
| システム全体の視覚化 |
システムの全体を直感的に知覚するには、レッドゾーンのオーバービューをビジュアルにデザインしなければならない。これはシステムのトップレイヤーからアプローチしていくことを指す。これはどういうことか。J2EEシステムを構成している、上位の基本コンポーネントのリアルタイム・パフォーマンスを監視すること。つまりこれがトップダウンのアプローチである。
視覚化する項目は次のとおり。直感でJ2EEシステムを包括的に把握するため1画面、10項目に絞り込む。このとき重要なことは、
- テスト対象のアプリケーションの単体テストを完了させておく
- バックエンドシステムも含むJ2EE環境の準備をしておく
- ハードウェアも準備しておく
- 本番に近いサイズのDBの準備をする
の4点である。システムの視覚化を行うタイミングは統合テストフェイズである。個々に開発、構築してきたシステムを1個のシステムとして“統合”するときに行うテスト段階ということだ。統合テストのパフォーマンス監視のため、下記の3画面を準備した。
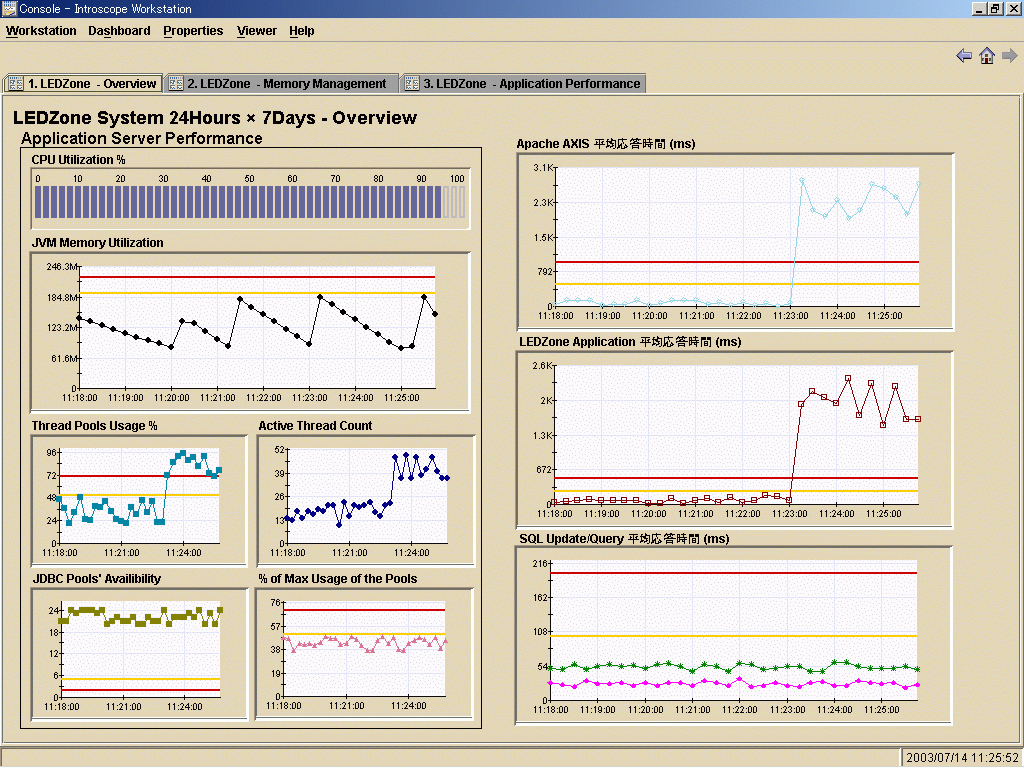 |
| 図2 システム全体のオーバービュー:バックエンドも含むシステム全体の構成要素の視覚化(クリックすると拡大) |
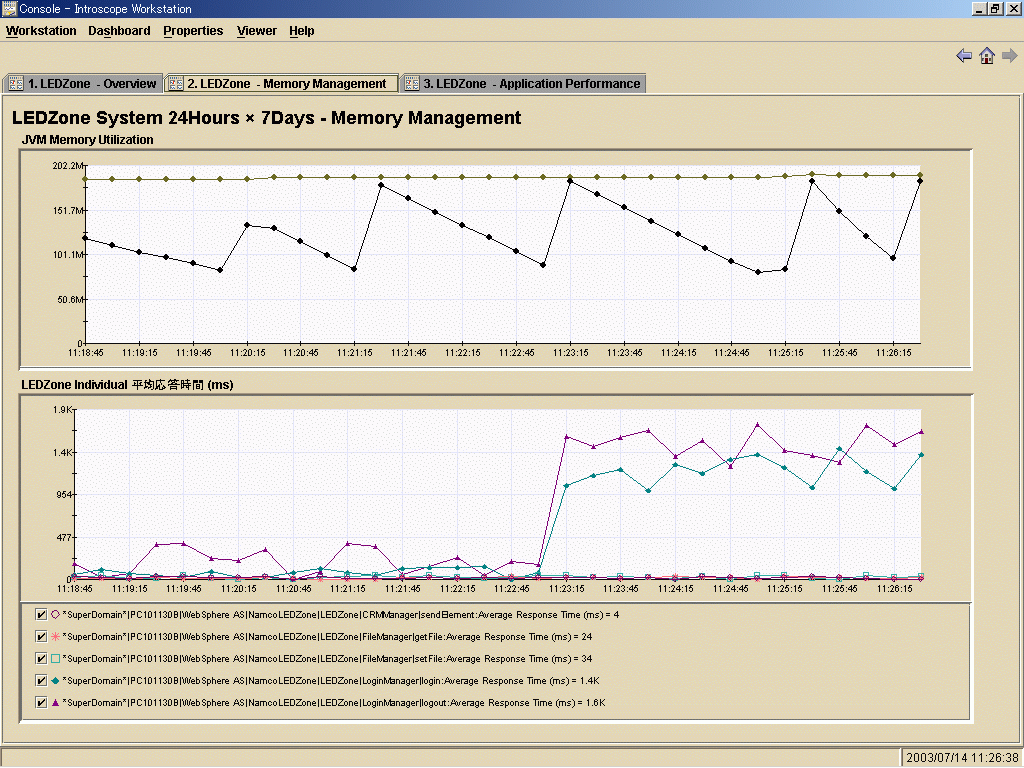 |
| 図3 JVMのメモリ管理と重要アプリケーション:JVMのヒープとGCの動きと重要アプリケーションの関連の視覚化(クリックすると拡大) |
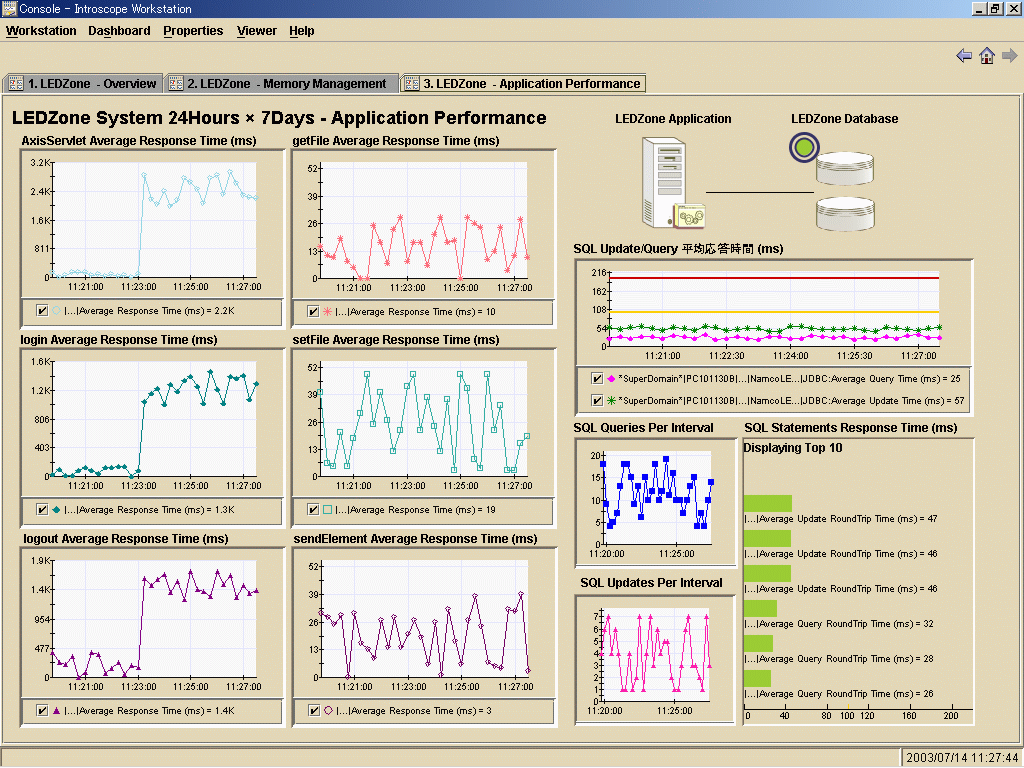 |
| 図4 重要アプリケーションとDBのパフォーマンス:関連する重要アプリケーションとDBパフォーマンスの視覚化(クリックすると拡大) |
(注)画面作成はパフォーマンス管理ツール「WILY4」を使用
| 負荷ツールでストレスをかける |
同時に5ユーザーで軽くストレスをかけて統合テスト環境の慣らし運転をする。今回の実験店舗は32台のPCを導入している。実質的に、最大稼働台数は32台だが、システムアーキテクチャを設計したときは最大50台の稼働を目標とした。
負荷テストでは、最小限のCPUでパフォーマンスを実証しなければならない。プロジェクトの責任者として、私はシステムの弱点がコストダウンのために採用したIAサーバとCPU数になるのではないかと予測した。同時5ユーザーから10ユーザー、30ユーザーへと段階的に負荷テストを実施するし、その都度、簡単なチューニングをしながら、目標の50ユーザーへチャレンジしていく。このような場合、限界ストレステストを重要視しがちだが、100%以上の限界負荷ではなく、50%くらいの通常負荷をかけることがポイントだ。限界テストの目的は、システムの限界値の把握とエラーハンドリングの正しさの確認にすぎない。
負荷テストを段階的に実施しながら、システム全体と重要なコンポーネントのパフォーマンスをリアルタイムに体感する。システムのボトルネックを発見することが統合テストの重要な目標である。マニュアル・ガイドなどといった机上のチューニング知識ではなく、自分の目で体感することが非常に大切である。チューニングの知識はすぐに陳腐化していく、ハードウェアとソフトウェアが進化し続ける現在では、古い知識は誤った判断を導くもとになる。
| パフォーマンスを見る |
では実際に、パフォーマンスの監視を行ってみよう。オーバービューでパフォーマンス監視する項目は以下の通り。
- IAサーバのCPU使用率
- J2EE関連
・サーブレット平均レスポンス
・スレッドプール使用率
・DBコネクションプール使用可能数
- SQLの平均時間(更新と検索)
- SOAP/AXISの平均レスポンス
- JVMのヒープ使用率とガベージコレクション(GC)状況
- 重要アプリケーションのログイン、課金、ログアウト
プロジェクト責任者やアーキテクトは、開発したシステムのリアルなイメージを徐々に自分の頭の中に確立していく。この感覚がボトルネックの発見の勘を磨いていく。最後はこの感覚が本番システムの「しきい値」を決定するベースの数字となる。
◇1. IAサーバのCPU使用率
システム稼働のどの時点でCPU使用率を振り切るか、常にチェックしていることが必要である。特にレスポンスが悪化したときのCPU使用率はいつもチェックしておく。また、CPUの使用率が常に100%で、それがレスポンス悪化の原因となっているときは、CPUの追加を検討することが必要である。だが、これはコストとスケジュールに影響する重要事項であり、クライアントの了承を得ることが必須となる。
◇2. J2EE関連
-
サーブレット平均レスポンス
スレッドプール使用率
DBコネクションプール使用可能数
J2EEの初期設定の数値が正しいかを負荷をかけながら、同時5ユーザー、15ユーザー、30ユーザーの環境でテストを行い、どの部分でスループットが問題になるかを監視する。そして、同時に30ユーザーを処理できるようシステム値を再設定する。このことは、サーブレットの平均レスポンスでアプリケーションの平均処理時間を把握しながら行う。また、スレッドプールで同時処理能力が決まるので、最大30ユーザーの処理ができるように調整する。さらに、DBコネクション数を徐々に上げていく。J2EEの足回りを設定し、順調になれば大きな変更をする必要はない。
◇3. SQLの平均時間(更新と検索)
SQLの平均レスポンスを監視することで、DBのチューニングが必要かを判断する。これは、すべてのアプリケーション(サーブレット)における処理時間を分析する基礎時間となる。SQLの処理時間がアプリケーションの処理時間の10%以内ならば、チューニングの対象としてはプライオリティが低くなる。
◇4. SOAP/AXIS平均レスポンス
SOAPの通信プロトコルの平均処理時間をAXISサーブレットで把握する。ここでは、ゲームのコンフィグレーション情報(個人別のゲームの設定情報)とCRM情報が行き交っている。LAN(100Mbit/sイーサネット)のキャパシティとXMLのパース時間が今回のシステム設計の重要なポイントである。
スループットが低い場合は、SOAP通信をTCP/IPソケットへ変更することも初期段階で検討したが、将来の拡張を考慮すると、SOAPを採用した方が賢明だと判断した。もう1つの対策は、送信内容を削減する方法だが、この場合は仕様変更となり、クライアントとの再交渉が発生する。
◇5. JVMのヒープ使用率とガベージコレクション(GC)状況
JVMはJavaの根幹だが、その仕様は複雑である。本を読み、基本を理解することは大切だが各メーカーやバージョンによって違いがあり、なおかつ仕様は刻々と変化している。それ故、ストレスをかけながらJVMのヒープ使用率とGCの変化を数十分集中して見ている方が、JVMのリアルな動きがよく理解できるだろう。ここでは、重要なアプリケーションのレスポンスとGCが連動しているかを確認する。そして、JVMのサイズをサーバのメモリサイズと合わせて検討をする。64Mbytes、128Mbytes、256Mbytes、512Mbytesとテストをしていく。最大1Gbytesまで最適値の確認をする。メモリの追加はコストとアプリケーションへの影響を考えると一番リスクが低い対策なのだが、安易に採用すると問題の本質の追究が甘くなるので注意が必要だ。
◇6. 重要アプリケーションのログイン、課金、ログアウト
ユーザープロファイルの確認やCRM情報更新のため、ログインとログアウトを行うアプリケーションは、使用頻度は少ないながらも重い処理となる傾向がある。反対に、課金を行うアプリケーションは、1分間ごとに自動的に料金を更新していく。1回の処理は軽いが、呼び出し回数は非常に多い。パフォーマンス監視をするとき、課金など頻度の高いトランザクションをモニタリングするとシステムのオーバーヘッドに影響してしまう。統合テストのときはよいが、本番システムのパフォーマンス監視のときは慎重な判断が必要だ。
アプリケーションのレスポンスとJVMのGCを時系列にしばらく見る。GCの発生とアプリケーションのレスポンスの悪化が連動しているときは、JVMのサイズ(64Mbytes〜1Gbytes)まで変更してJVMサイズの最適値を確認する。いくら大きくしても問題があるときは、プログラムのコードレビューを行い、メモリ処理のロジックをリファクタリングすることが必要である。これも統合テストのフェイズが最後のチャンスである。プログラムの書き直しは非常に勇気がいる。クライアントと仕様の再調整をする可能性があるからだ。安易にJVMのサイズを大きくせず、一度、問題の本質が何かを調査することが大切である。
最後に、重要アプリケーションは、システムの基本であるシーケンスダイアグラムから順番に呼び出されていくコンポーネントを選ぶと分かりやすい。オーバーヘッドの大きい高頻度のトランザクションタイプは、その手前のコンポーネントを見ることも代替案である。
| ボトルネックを発見する |
統合テストの最終段階でゲームの品質を確認する人間系テストを20人以上のユーザー負荷で実施した。これは1日中、ゲームの耐久力を確認するテストである。全員でログイン/ログアウトを実施したが、通常なら数秒以内にレスポンスが戻るところをユーザー別レスポンスが非常にばらつき、数秒から数分までかかったことがあった。これは、負荷ツールを使用したときには気が付かなかった現象である。負荷ツールは現実に近い状況を再現するため、同時ユーザーのログイン時間をずらしてある。現実には同時にログインすることはイベント以外にはあり得ないからだ。
負荷ツールを調整し、同時ログインが可能なように設定して、再テストを行い、システムのオーバービューを見る。途中からCPU使用率が100%になり、処理が遅延していく。スレッドプール不足と考え、100近くまで増加させたが解決しない。同じログアウト処理でも、数秒で正常に終了するときと数分かかるときがある。トランザクションの中で何が起こっているかを分析する必要がある。今回は「トランザクション・トレーサー」というツールを使用し、トランザクション内部の動きを視覚化した。その結果、ログアウトの最終工程処理に問題があると判断した。ボトルネックを特定したので、開発リーダーやプログラマなどとディスカションを開始する。30ユーザーの同時ログアウトで起こる照明の演出が瞬間的なスレッド増加を発生させていた。新規スレッドが発生するとき、JVMのCPU負荷が非常に高くなり、表面的にはCPUのボトルネックのように見える。子スレッドが発生しないよう、プログラムを改善し、再テストを実施するとCPU使用率とレスポンスの悪化は解消した。このボトルネックの解消でプロジェクトの目標である同時30ユーザー稼働は保証された。この現象はリソースのスラッシングが発生したと考えている。
| プロジェクトの責任者の心得 |
プロジェクトの責任者は、スケジュールとコストを考え、リスク(ボトルネック)をコントロールしなければならない。パフォーマンス管理を行うことで内在するリスクを視覚化し、事前に把握することが重要なのである。それも早い段階であれば仕様の変更やプログラムのリファクタリングを実施する時間が確保できる。また、クライアントへの説明責任を果たすことも可能となる。
アーキテクチャの仮説モデルが正しいかを視覚で確認するという経験の積み重ねがシステム構築を行ううえでのノウハウとなり、結果的にJ2EEの深い理解へとつながる。
今回私は、構築途中での仕様変更を想定せず、最初に設計したアーキテクチャ(のパフォーマンス)がシステム全体の振る舞いにどのような影響を与えるかを深く考えていなかった。設計時にアーキテクチャの仕様変更を考慮せずに出発し、やむを得ず途中で設計変更が必要になるケースは多々あるのである。
ほかにも反省点はいろいろある。DBサーバを2CPU構成にしたが結果的にはアプリケーションサーバと逆の構成の方がよかったかもしれない(アプリケーションサーバを2CPUにする)。DBサーバを重点に据えてシステム全体をデザインするという私自身のクセが強く影響したのではと考えている。そもそもこの点は、設計初期の段階から一番悩んだ項目の1つだった。システム全体の動作を確認する「総合テスト」(統合テストのさらに後に行う)の最後のフェイズでは、サーバを入れ替え、テストをやり直すといった時間やコストはない。ソフトウェアのライセンス料金も変動することを考慮すれば、結局、今回はこれでサービスインすることを1人で決断しなければならなかった。プロジェクト責任者はこういう解答のない世界で1人で決断し、行動しなければならない。自分の目でJ2EEの世界を視覚化し、J2EEシステムのパフォーマンスを感性で感じる力を磨いてほしい。
| IT Architect 連載記事一覧 |
![]()
転職/派遣情報を探す



「ITmedia マーケティング」新着記事
「サイト内検索」&「ライブチャット」売れ筋TOP5(2025年5月)
今週は、サイト内検索ツールとライブチャットの国内売れ筋TOP5をそれぞれ紹介します。
「ECプラットフォーム」売れ筋TOP10(2025年5月)
今週は、ECプラットフォーム製品(ECサイト構築ツール)の国内売れ筋TOP10を紹介します。
「パーソナライゼーション」&「A/Bテスト」ツール売れ筋TOP5(2025年5月)
今週は、パーソナライゼーション製品と「A/Bテスト」ツールの国内売れ筋各TOP5を紹介し...