
最終回
Relaxerプロセスによる設計
永山葉子、浅海智晴
2003/9/30
| 1 はじめに |
前回(第3回 Relaxerプロセスのシステム分析)は図書館システムの開発を例に、Relaxerプロセスによるシステム分析工程について解説しました。今回はシステム分析工程までに作成した成果物を材料に、実際にRelaxerを活用して設計を行う場面を解説します。まずRelaxerプロセスにおける設計工程について概観し、その後、図書館システムを例に設計プロセスの詳細を解説します。
| 2 設計 |
設計モデルとは、図1に示すように解決領域におけるモデルです。同じ解決領域のモデルであるシステム分析モデルが、実装技術を意識しない抽象的なモデルであるのに対して、設計モデルは実装を意識した具体的なモデルです。
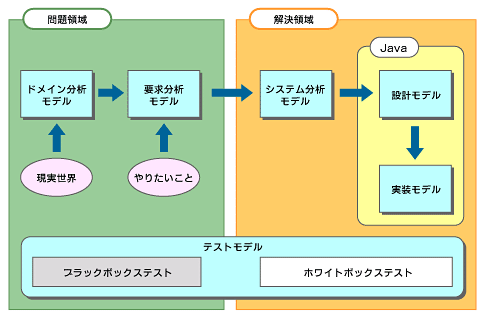 |
| 図1 設計モデルとは解決領域におけるモデルのこと |
◇2.1 設計の作業
Relaxerプロセスにおける設計とは、前回行ったシステム分析の成果物である「コンポーネント・モデル」「エンティティ・モデル」「バリュー・モデル」「システム・モデル」を入力し、「Relaxerモデル」「Javaモデル」「システム・モデル」を出力する作業のことです。ただし、この作業は、いきなりすべてを行うわけではなく、「Relaxer設計」と「コンポーネント設計」という2つの詳細作業を段階的に踏みながら行います。
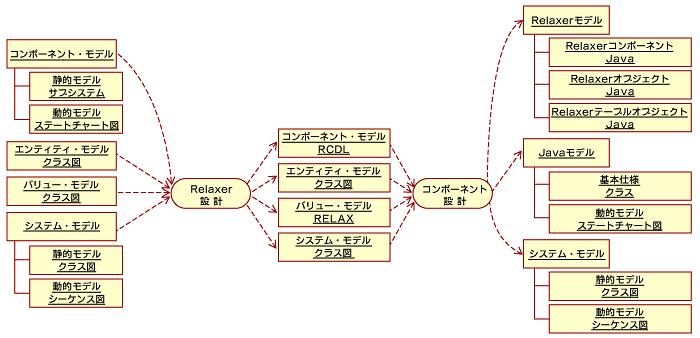 |
| 図2 Relaxer設計とコンポーネント設計の流れ(クリックすると拡大) |
設計作業の詳細に踏み込む前に、設計作業で最終的に出力されるモデルの説明を行っておきましょう。「Relaxerモデル」とは、Relaxerが生成したJavaクラスをはじめとする成果物のことです。また、「Javaモデル」は、Relaxerでは自動生成できないJavaプログラム部分のモデルを示します。そして、「システム・モデル」は、コンポーネントによって構成されるシステム全体の構成を記述するモデルです。
それでは以下、Relaxer設計とコンポーネント設計の概略を解説します。概略説明の後に、これらの詳細設計が図書館システムの開発でどのように適用されるかを見ていくことにしましょう。
◎2.1.1 Relaxer設計
Relaxer設計は、分析コンポーネントから「Relaxerモデル」を作成する作業です。これはRelaxerプロセスの特徴的な作業です。もちろん、「Relaxerモデル」を作成する理由は、Javaプログラムの自動生成にほかなりません。Relaxer設計では、システム分析の成果物である「コンポーネント・モデル」「エンティティ・モデル」「バリュー・モデル」「システム・モデル」を入力し、「コンポーネント・モデル」「エンティティ・モデル」「バリュー・モデル」「システム・モデル」を出力します。
Relaxer設計で出力される「コンポーネント・モデル」は、設計コンポーネントのモデルとなります。このモデルは、RCDL(Relaxer Component Definition Language)で記述されます。「エンティティ・モデル」は、システムの操作対象となるオブジェクトをモデル化します。そして、「バリュー・モデル」は、コンポーネント間を流通するバリューオブジェクトのモデルです。これは、RELAXスキーマを使って記述されます。もちろん、これはRelaxerを用いてJavaクラスを自動生成することが目的となります。
| Relaxerのダウンロードとインストール | |
この工程では、XMLスキーマコンパイラ/コンポーネントコンパイラRelaxerを使用します。最新版の1.0
Release Candidate 2のインストーラsetup.zipをwww.relaxer.orgからダウンロードします。
そして、コマンドプロンプトでインストーラを起動します。C:\tmpにダウンロードした場合は次のとおりです。
インストールディレクトリとコマンドスクリプトのインストールディレクトリを入力すると、入力値を確認してくるので、yesと答えればインストールが開始されます(デフォルトではそれぞれ、C:\usr\local\lib\relaxerとC:\usr\local\binにインストールされます)。コマンドスクリプトのインストールディレクトリを環境変数PATHに追加すれば、インストールは完了です。 |
◎2.1.2 コンポーネント設計
コンポーネント設計は、前述したRelaxer設計の段階で、Relaxerによって生成されたRelaxerコンポーネントのサービスを実現する設計を行うための作業で、「コンポーネント・モデル」「エンティティ・モデル」「バリュー・モデル」「システム・モデル」を入力し、「Relaxerモデル」「Javaモデル」「システム・モデル」を出力します。これらのモデルはそのまま設計の出力となり、実装作業で利用することになります(図2を参照)。
| 3 図書館システム開発におけるRelaxer設計 |
さて、第3回のシステム分析で作成した分析コンポーネント「図書返却処理」および、「蔵書情報管理」について、「Relaxerモデル」を作成します。実装段階ではJavaを使用することを想定し、コンポーネント「図書返却処理」「蔵書情報管理」にはそれぞれパッケージ名com.example.bookReturning、com.example.bookCollectionを割り当てます。
◇3.1 「図書返却処理」のRelaxer設計
では、コンポーネントを個別に見ていきましょう。「図書返却処理」コンポーネントは以下のように表現します。
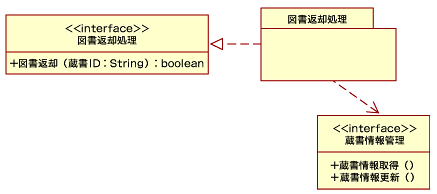 |
| 図3 「図書返却処理」コンポーネント |
このコンポーネントをRelaxerCDLとして定義すると、リスト1のようになります。インターフェイスのオペレーションの引数で使用しているデータタイプ(string、boolean)は、XMLデータタイプです。これらのデータタイプはRelaxerによってJavaのデータタイプ(String、boolean)にマッピングされます。
<interface xmlns="http://www.relaxer.org/xmlns/cdl" <!-- 図書返却
--> |
| リスト1 bookReturning.ridl |
interface要素のname属性として、「図書返却処理」のパッケージ名を反映した値を使用しました。また、operation要素のname属性としてreturnBookを定義し、in要素にはその引数を、out要素には復帰値を定義します。図書返却オペレーションは図3でモデリングしたように、文字列の蔵書IDを引数に取ります。よって、name属性をcollectionIdとしました。
type属性にはXMLの文字列データタイプであるstringを定義しています。RelaxerはこのXMLデータタイプstringをJavaデータタイプStringにマッピングします。また、図書返却オペレーションの復帰値に結果の成否を取るため、out要素のname属性をresult、type属性をbooleanとしました。RelaxerCDL定義からJavaのコンポーネント・スケルトンを生成するには、Relaxerコマンドにcdlオプションを付けて実行します。
> relaxer
-verbose -package:com.example.bookReturning |
| Relaxerの実行コード(1) |
オプションで、Relaxerコマンド実行の詳細を表示し(verbose)、生成するJavaソースファイルにパッケージ宣言を付加(package)、出力先を指定し(dir)、クラス名にプレフィクスを付ける(classPrefix)ように指定しました。また、生成するサービスプロバイダについては別のパッケージ名を使用することをcdl.sp.packageで指定しています。オプションの詳細については、ダウンロードしたRelaxerに含まれるリファレンスマニュアルを参照してください。Relaxerを実行した結果、dirオプションで指定したディレクトリに11個のJavaソースファイル(460ステップ)が生成されます。
◇3.2 「蔵書情報管理」のRelaxer設計
「蔵書情報管理」コンポーネントは、図4のようになります。これは蔵書情報データベースにアクセスするためのコンポーネントです。前述の「図書返却処理」コンポーネントは「蔵書情報管理」のインターフェイスを介して、データベース上の蔵書情報を取得し、更新という操作を行うことで、ユースケースの目的(「図書の返却処理を行う」)を達成します。
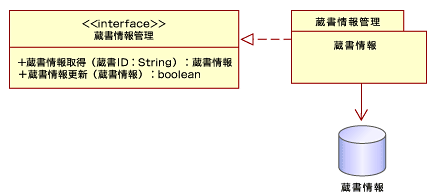 |
| 図4 「蔵書情報」コンポーネント |
まず、Relaxerオブジェクトを生成するために、バリューオブジェクトとエンティティオブジェクトからRELAXスキーマを定義します。このコンポーネントには、オペレーション「蔵書情報取得」の復帰値として、流通するバリューオブジェクト「蔵書情報」とデータベースに格納されるエンティティオブジェクト「蔵書情報」があります。このバリューオブジェクト「蔵書情報」は、データベースに保存されるとエンティティオブジェクト「蔵書情報」となるので、ここではエンティティオブジェクトのみをRELAXスキーマで定義します。「蔵書情報」は前回のシステム分析で作成したクラスを基に、図5クラスのように描くことができます。
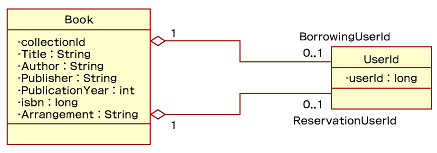 |
| 図5 「蔵書情報」クラス |
そして、このモデルをRELAXスキーマで記述すると、リスト2となります。
<?xml version="1.0"
?> <start> |
| リスト2 collectionManager.rng |
bookの要素の1つにcollectionIdがあり、12文字の文字列データタイプが定義されています。また、蔵書IDはデータベースのプライマリキーとして使用するため、collectionIdの要素にsql:primary属性を与えます。なお、プライマリキーを指定するには、element要素にsql:primary属性を付加します。プライマリキーを設定しないと、Relaxerが生成するテーブルオブジェクトのクラス(ここでは、BookTable.java)にアップデートメソッドが生成されないことに注意してください。
続いて、分析コンポーネント「蔵書情報管理」の「コンポーネント・モデル」をRelaxerCDLで定義したものがリスト3です。
<interface xmlns="http://www.relaxer.org/xmlns/cdl" <!--
蔵書情報取得 --> |
| リスト3 collectionManager.ridl |
コンポーネント定義の中で、先ほど定義した「蔵書情報」のRELAXスキーマのファイルを参照しています。このように、inまたはout要素にスキーマを指定するには、XMLデータタイプを指定するtype属性ではなく、label属性を使用します。ここで、コンポーネント定義に対してRelaxerを実行します。コマンドラインにオプションを並べてもいいのですが、リスト4のようにオプションをプロパティファイルにまとめて指定することもできます。
# 詳細情報表示###################### |
| リスト4 cm.properties |
このプロパティファイルをpropertiesオプションに指定してRelaxerを実行します。
>relaxer
-properties:cm.properties collectionManager.ridl |
| Relaxerの実行コード(2) |
その結果、dirオプションで指定したディレクトリに、リスト3で定義したコンポーネントのスケルトンクラスと、リスト3が参照し、リスト2で定義した蔵書情報のRelaxerオブジェクトが生成されます。生成されたファイル数は22個、合計約1万1600ステップです。
| RELAX NGの学習法 |
| 「Relaxerモデル」を作成するためには、RELAXスキーマ言語を習得することが必要になりますが、RELAX NGは覚えるのがとても簡単です。また、シンプルな構造のXMLであれば、リスト3 に示した程度の記述ができれば十分です。RELAX NGやその仕様についてはRELAX NG日本語ポータル(http://relaxng.sourceforge.net/japan/)やチュートリアル(http://www.kohsuke.org/relaxng/tutorial.ja.html)を参照してみてください。 |
| 4 コンポーネント設計 |
Relaxer設計の段階で、「コンポーネント・モデル」と「エンティティ・モデル」「バリュー・モデル」のJavaソースが得られました。コンポーネントの構成はこれらのJavaクラスと「コンポーネント・モデル」を用いて図6のように記述できます。
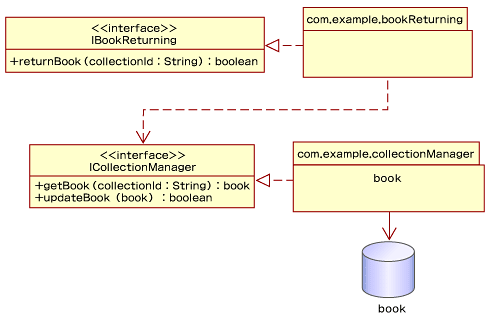 |
| 図6 システム・モデル |
また、「図書返却処理」と「蔵書情報管理」コンポーネントにかかわるシーケンス図を図7「シーケンス図」に示します。
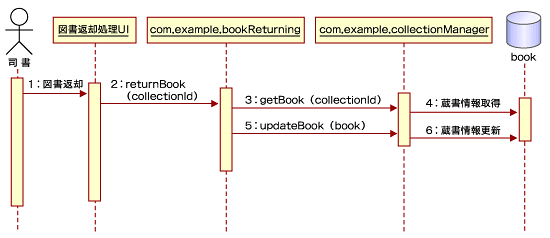 |
| 図7 シーケンス図(クリックすると拡大) |
| 5 最後に |
さて、前回から2回にわたり、Relaxerプロセスの核となるシステム分析と設計の流れを解説しました。今回は、RELAXモデルの作成からRelaxerによるクラスの生成という最も威力のある場面を紹介しました。今回の例では、RELAX NGスキーマおよびRelaxerCDLの定義85ステップによって、データベースアクセスコードを含む1万2000ステップのJavaソースコードがRelaxerによって生成されます。これを見ると、いかにRelaxerによるコード生成が強力であるかお分かりいただけるでしょう。このRelaxerによるコード生成をより効率的に行うためには、オブジェクト指向開発プロセスの上流工程において工夫が必要となります。その工夫が、システム分析工程におけるロバストネス分析の改良であり、ロバストネス図から分析コンポーネント、Relaxerプロセスに至る開発手順であるわけです。そして、これらのノウハウを定型化した開発プロセスがRelaxerプロセスなのです。
| IT Architect 連載記事一覧 |
![]()
転職/派遣情報を探す



「ITmedia マーケティング」新着記事
「サイト内検索」&「ライブチャット」売れ筋TOP5(2025年5月)
今週は、サイト内検索ツールとライブチャットの国内売れ筋TOP5をそれぞれ紹介します。
「ECプラットフォーム」売れ筋TOP10(2025年5月)
今週は、ECプラットフォーム製品(ECサイト構築ツール)の国内売れ筋TOP10を紹介します。
「パーソナライゼーション」&「A/Bテスト」ツール売れ筋TOP5(2025年5月)
今週は、パーソナライゼーション製品と「A/Bテスト」ツールの国内売れ筋各TOP5を紹介し...