
最終回 メインフレームLinuxの今後
TCOの削減やサーバ統合、クラウド・コンピューティングといったITが抱える課題に、メインフレームLinuxはどのように効くのでしょう? 最終回では今後の方向性を紹介します(編集局)
日本アイ・ビー・エム株式会社
システムズ&テクノロジー・エバンジェリスト
北沢 強
2009/2/16
いよいよ連載の最終回です。これまでの連載を通して、メインフレームで動くLinuxがどういうものなのか、そしてメインフレームがどういうものなのかを知っていただくために、メインフレームにLinuxが移植された経緯や実装について、特徴的なところを解説してきました。
前回の「広がるメインフレームLinuxの適用領域」では、すでにいろいろなところで稼働しているメインフレームLinuxがどのような目的で、どのようなシステム形態で使われており、どのような効果があるのかを解説しました。今回は、メインフレームLinuxが今後どういう方向に進んでいくのか、メインフレームの将来像と併せて展望してみたいと思います。
 最近のメインフレームLinuxの機能強化
最近のメインフレームLinuxの機能強化
Linuxカーネルは現在、25種類のハードウェア・アーキテクチャに対応し、PDAや携帯電話からスーパーコンピュータに至るまで、広範囲のプラットフォームで稼働しています。メインフレームLinuxもその1つで、あくまで「普通のLinux」です。
ただし、ハードウェア依存部分についてはプラットフォームごとに実装が任されていますので、メインフレーム独自の機能強化は可能です。顧客から求められる高いRAS(Reliability、Availability、Serviceability)要件を満たすべく、ハードウェアで装備しているスケーラビリティやRAS機能を、Linux用のデバイスドライバやツールにより実装を進めています。
今回は、最近追加された機能の中でも、今後さらに重要となるであろうサーバ統合に関係する機能をいくつか紹介します。
■プロセッサ・ノード・アフィニティ
マルチプロセッサ環境では、複数のプロセッサを効率的に使うための工夫がいろいろと必要になります。Linuxカーネルでは以前より、プロセッサ・アフィニティが実装されていました。これは、プロセッサにはパイプライン処理や命令/データキャッシュがあるため、キャッシュヒット率をできるだけ高くすればパフォーマンスが良くなるという考えに基づくアプローチです。なお、下記の関 連記事では、Windowsの話ですがプロセッサ・アフィニティについて解説しています。
| 関連記事: | |
| プログラムの実行に使用するCPUを限定させる(@IT Windows Server Insider) http://www.atmarkit.co.jp/fwin2k/win2ktips/862affinity/affinity.html |
|
特に、プロセッサのクロック周波数が高く、プロセッサ内のキャッシュとメモリとの速度差が大きいほど、アフィニティによる効果が期待できます。また、それぞれのプログラムには「使用する命令やメモリアクセスにおいて偏りが出る」という参照局所性が働くことから、同じプロセスやスレッドはできるだけ同じプロセッサにディスパッチすると、キャッシュヒット率が高くなり処理効率が良くなります。
IBMのメインフレームの場合は、プロセッサ数を増やすため、MCM(Multi-chip Module)という技術によって96×96mmのモジュール上にプロセッサ20個分を搭載しており、そのMCMが最大で4個まで結合されます(図1)。
また、プロセッサはクアッドコアであり、コア内にL1キャッシュ(I-cache 64KB、D-cache 128KB)、チップ内にL1.5キャッシュ(3MB×4)、MCM内にL2キャッシュ(24MB×2)が搭載されています。つまり、Linuxからディスパッチする優先順位としては、同一コア、同一チップ、同一MCMという順序になります。
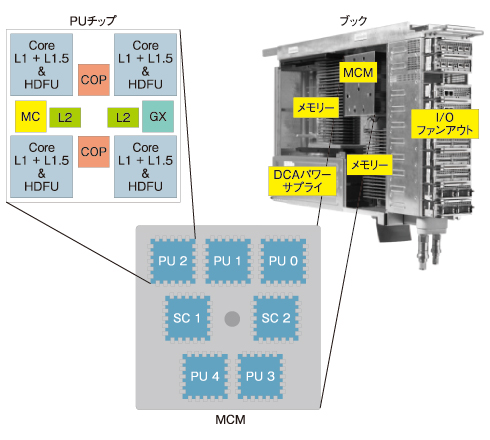 |
| 図1 z10EC マルチチップモジュール |
このように階層的にアフィニティを管理する必要性があるため、カーネル 2.6.25でノードアフィニティを実装しました。Linuxカーネル自体がNUMAアーキテクチャに対応したおかげで、メインフレームも対応することができました。SMP構成においてノード単位でのアフィニティが考慮されることで、より効率的な処理が期待できます。
ちなみにメインフレームではいままで、プロセッサ・アフィニティはあまり強くは意識されてきませんでした。1つのプロセッサ上で多様なワークロードのアプリケーションが混在して動くため、プロセッサ内でのキャッシュヒット率よりも、大量のI/O処理を含むシステム全体のスループットを重視してきたためです。
歴史的にはプロセッサのクロック周波数はそれほど高くはなく、いままではプロセッサの演算速度、キャッシュ、メモリ、I/Oのスピードとバランスが取れていたため、アフィニティを強く意識しなくても、それなりの性能が得られていました。しかしながら、最新のIBM System z10を見ても分かるとおり、4.4GHzというクロック周波数になってくると話は変わってくるわけです。
また、仮想化環境においては、同一のプロセッサを複数のOSで使用します。従って、仮想化による統合環境でのプロセッサ・アフィニティには、さらに複雑な要素を考慮する必要があります。これについては今後の課題になるでしょう。
■ラージページのサポート
メインフレームでは昔からいままでずっと、ページサイズの主流は「4KB」です。この4KBという単位は、メインフレーム・アーキテクチャにおけるマジックナンバーであり、システム全体が4KBにチューニングされているといっても過言ではありません。例えばI/O命令の処理単位は4KBですし、ディスク装置DASDのブロックサイズも4KBが最適値です。
また、パンチカードは80カラム×10行でしたが、それと互換性を持たせた3270端末装置の主流は80カラム×24行で、文字色や点滅・ハイライトなどの属性データを合わせても4KBに収まるように設計されていました。キーボードをたたくと送信されるデータ、あるいは画面に表示されるデータ量も4KB以下でした。
つまり、すべてのI/O処理やメモリ処理を4KB単位で行い、4KBで処理すれば最高のパフォーマンスが得られる仕組みになっていたのです。
これを引き継ぎ、メインフレームLinuxの仮想メモリも4KBページで実装しています。メインフレームハードウェアが持っているページ命令をフルに活用できるため、メモリ処理を効率よく行うことができました。
しかしながら、時代とともに処理対象となるデータサイズが大きくなる傾向にあり、メモリ価格もどんどん安価になると、4KBのページサイズというのは時代にそぐわなくなってきました。数十GBから数TBのメモリを搭載するサーバが当たり前になってきたにもかかわらず、4KB単位で仮想メモリを管理すると、ページテーブルだけでも大きなサイズになってしまってメモリを圧迫します。また、ページングなどの処理でオーバーヘッドも生じます。
特に、仮想アドレスと物理アドレスの変換のためのキャッシュであるTLB(Translation Lookaside Buffer)は、限られたサイズの中で処理を行う必要があるため、ページサイズを大きくする方がヒット率は向上します。
ページング処理の負荷を軽減するにはブロックページングという手法もありますが、それには限界があり、TLBの問題も解決できていませんでした。
これらの問題を解決するために、Linuxではラージページ(Large page)として2MBのページ(hugetlbfs)をサポートするようになりました。またメインフレームLinuxでは、カーネル 2.6.25からz10のラージページ命令(1MBページ)を使用するようにしました(リスト1)。ただし、古いメインフレームではハードウェア命令でラージページをサポートできないため、その場合はカーネル内でエミュレーションするように実装しています。
|
|
| リスト1 ラージページの確認例 |
| 第5回へ | 1/3 |
|
||||||
|
||||||
- 【 pidof 】コマンド――コマンド名からプロセスIDを探す (2017/7/27)
本連載は、Linuxのコマンドについて、基本書式からオプション、具体的な実行例までを紹介していきます。今回は、コマンド名からプロセスIDを探す「pidof」コマンドです。 - Linuxの「ジョブコントロール」をマスターしよう (2017/7/21)
今回は、コマンドライン環境でのジョブコントロールを試してみましょう。X環境を持たないサーバ管理やリモート接続時に役立つ操作です - 【 pidstat 】コマンド――プロセスのリソース使用量を表示する (2017/7/21)
本連載は、Linuxのコマンドについて、基本書式からオプション、具体的な実行例までを紹介していきます。今回は、プロセスごとのCPUの使用率やI/Oデバイスの使用状況を表示する「pidstat」コマンドです。 - 【 iostat 】コマンド――I/Oデバイスの使用状況を表示する (2017/7/20)
本連載は、Linuxのコマンドについて、基本書式からオプション、具体的な実行例までを紹介していきます。今回は、I/Oデバイスの使用状況を表示する「iostat」コマンドです。
|
|





