
バックアップを効率化する重複排除テクノロジ(1)
重複排除とは何か
株式会社シマンテック
プロダクトマーケティング部 プロダクトマーケティングマネージャ
浅野 百絵果
2010/6/1
| 企業内のデータ量は年々増加の一途をたどっている。こうした中、莫大かつ重要なデータを効率的に取り扱う技術として注目されているのが「重複排除」だ。この連載では重複排除のテクノロジに着目し、どのようにコストメリットがあるのか、また適用時のノウハウについて解説する。 |
 増加し続ける企業内データにどう立ち向かうか?
増加し続ける企業内データにどう立ち向かうか?
企業においてデータへの依存度が高まり、データは重要な資産であるという考え方が一般的になっている。データ量は年々増加の一途をたどっており、その増加率は年次で50〜60%が一般的ともいわれている。
とはいえ、データの保全や管理に投下できるITコストは、データ量の増加と正比例に増額することは難しいのが実情ではないだろうか。いまこそ、膨大かつ重要なデータを効率的に保護する方法が求められているのだ。そうした状況下、注目を集めているのが重複排除という技術なのである。
重複排除の基本的な考え方
データを取り扱うITシステムでは、同じデータが複数回にわたって送信、受信、保存されるという処理がよく発生する。例えば、データベースにおいて、非常によく似たレコードの、ある一部のフィールドだけが異なる値を持っているとする。そういう場合でも、一般には同じデータを何度もやりとりするという処理が行われている。
しかし、すでに処理済みの記録を使い、異なる一部のデータだけを処理すると、転送データの縮減や処理速度の向上が期待できる。これが重複排除の基本的な考え方だ。重複排除は最近、特にバックアップソフトウェアやバックアップストレージに搭載されるケースが増えているが、データを保存する際に重複排除を使うと、少ないストレージ容量で多くのデータを保存できるようになる。
文書データを例に見てみよう。全社で決まったテンプレートを使って文書作成をしたり、作成済みの文書の一部だけを改変して別名で保存したりと、企業内には類似のデータが数多く存在する。また、複数の社員で情報共用するために同じ文書ファイルが配布されたとき、それをファイルサーバの別の場所に保存したなら、内容が完全一致するファイルがいくつもあることになる。ファイルの全部、または一部のデータが重複している場合、その部分を同じであると識別し、インデックスを付けて、同じデータは1度しか保存しないようにすれば、ストレージを大幅に節約できる。
ちなみに、これに似た技術に「シングルインスタンス・ストレージ」がある。これは完全に同じ内容を持つファイルが複数ある場合に、これを1度だけ保存するという技術だ。上記の例でいうと、完全に同一内容のデータベースファイルが2つある場合にのみ、これを1度の保存で済ますことが可能になる。企業内にあるデータは上記のように“ほとんど同じだが一部だけが書き換えられているデータ”が多く、この場合はシングルインスタンス・ストレージのデータ削減効果は限定的といえる。
重複排除を使ったバックアップ
同じようなデータが多く存在すればするほど、重複排除の効果は高くなるがそれだけではない。ここで着目すべきは、バックアップにはそもそもそれ自体に重複が多く存在するという点である。重複排除を適用した場合のバックアップのプロセスは、以下のようになる。
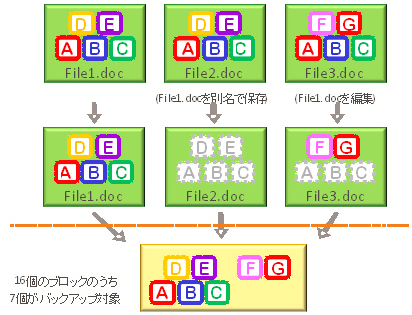 |
| 図1 1回目のバックアップ |
重複排除では、まず、ファイルを細かい単位(ブロック)に分割する。File1.docは一度もバックアップされていないデータなので、ファイル内のすべてのデータがストレージに書き込まれる。次に、File2.docだが、これは実際にはFile1.docを別名で保存したもので、データとしては同じものである。File1.docがすでにバックアップ済みなので、File2.docはどのブロックで構成されているなどのインデックスが作られるのみで、データは書き込まれない。File3.docはFile1.docを編集したもので、一部のブロックに重複がある。この場合は重複しないブロック(この例ではFとGのブロック)だけが書き込まれ、同様にどのブロックを使えばFile3.docができるのかインデックスが付けられる。
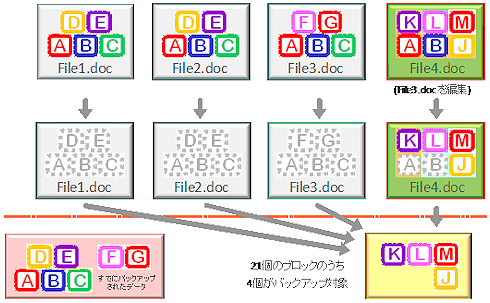 |
| 図2 2回目以降のバックアップ |
2回目以降のバックアップでは、すでにバックアップされたデータ(ブロック)がすでにストレージにあるので、インデックスを参照したうえで、前回のバックアップ以降に新しく作成された異なるブロックだけがストレージに書き込まれる。つまりすでにバックアップされたファイルについて2度とデータが追記されることはない。またこの図のFile4.docのように、すでにバックアップされたファイルとの間で一部のブロックに重複があれば、異なるブロックだけがストレージに書き込まれる。
1/2 |
| Index | |
| 重複排除とは何か | |
| Page1 増加し続ける企業内データにどう立ち向かうか? 重複排除の基本的な考え方 重複排除を使ったバックアップ |
|
| Page2 バックアップの実態 重複排除によるコスト削減効果は? |
|
- Windows 10の導入、それはWindows as a Serviceの始まり (2017/7/27)
本連載では、これからWindows 10への移行を本格的に進めようとしている企業/IT管理者向けに、移行計画、展開、管理、企業向けの注目の機能について解説していきます。今回は、「サービスとしてのWindows(Windows as a Service:WaaS)」の理解を深めましょう - Windows 10への移行計画を早急に進めるべき理由 (2017/7/21)
本連載では、これからWindows 10への移行を本格的に進めようとしている企業/IT管理者に向け、移行計画、展開、管理、企業向けの注目の機能を解説していきます。第1回目は、「Windows 10に移行すべき理由」を説明します - Azure仮想マシンの最新v3シリーズは、Broadwell世代でHyper-Vのネストにも対応 (2017/7/20)
AzureのIaaSで、Azure仮想マシンの第三世代となるDv3およびEv3シリーズが利用可能になりました。また、新たにWindows Server 2016仮想マシンでは「入れ子構造の仮想化」がサポートされ、Hyper-V仮想マシンやHyper-Vコンテナの実行が可能になります - 【 New-ADUser 】コマンドレット――Active Directoryのユーザーアカウントを作成する (2017/7/19)
本連載は、Windows PowerShellコマンドレットについて、基本書式からオプション、具体的な実行例までを紹介していきます。今回は、「New-ADUser」コマンドレットです
|
|
注目のテーマ





