解説FB-DIMMがサーバのメモリを変える?1.シリアル・インターフェイスを採用するFB-DIMM元麻布春男2006/04/26 |
 |
|
|
|
2006年第2四半期にデュアルプロセッサ対応サーバ向けの新プラットフォーム「Bensley(開発コード名:ベンスレイ)」が登場する。Bensleyでは、NetBurstマイクロアーキテクチャを採用したデュアルコアのDempsey(デンプシー)プロセッサから、Intel Coreマイクロアーキテクチャを採用するデュアルコアのWoodcrest(ウッドクレスト)プロセッサ、そしてクワッドコアのClovertown(クローバータウン)プロセッサと、3世代のプロセッサに渡って使われる予定だ。この3世代にわたってスケーラブルな性能を提供するためにBensleyプラットフォームでは、強化されたプロセッサ・フロント・バス、I/Oの高速化技術「I/OAT(Intel I/O Acceleration Technology)」技術を用いたネットワーク・インターフェイスに加え、メイン・メモリに新規格の「FB-DIMM」がそれぞれ採用される。つまり2006年後半から、サーバ向けのメモリが現行のRegistered DIMMからFB-DIMMに変わることになる。そこで本稿では、FB-DIMMの概要やロードマップ、サーバへの影響などについて解説する。
FB-DIMMの特徴はAMBチップにある
Fully Buffered DIMMの略であるFB-DIMMの名称は、メモリ・チップとやりとりされるコマンド、アドレス、データのすべてがいったんバッファ・チップに蓄えられることに由来する。現在、サーバで主流となっているRegistered DIMMは、メモリ・モジュール上にレジスタ・チップを持ち、コマンドとアドレスをバッファリングするのに対し、FB-DIMMではモジュール上にAMB(Advanced Memory Buffer)と呼ばれるチップを持ち、すべてがここを経由する。実際には、このAMBチップは単なるバッファではなく、実質的なメモリ・コントローラであり、プロトコル変換を行うキー・コンポーネントだ。
図1はFB-DIMMの概要をまとめたものだ。このようにチップセットのメモリ・コントローラとFB-DIMM間は、PCI Expressに類似したポイント・ツー・ポイント接続のシリアル・インターフェイスで接続される。標準規格であるPCI Expressに準じたインターフェイスということで、FB-DIMMのインターフェイスに関しては基本的にライセンス料の支払いが不要であり、すでにメモリ関連規格の標準化団体であるJEDECでの標準化が完了している。FB-DIMMインターフェイスがPCI Expressと大きく異なるのは、上り(読み出し)と下り(書き込み)で帯域が非対称であること、クロック信号がデータ信号と分離していることの2点だ。
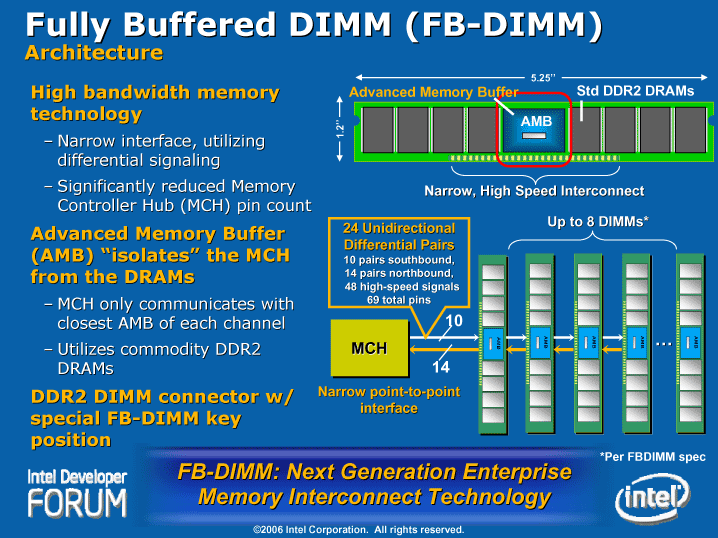 |
| 図1 FB-DIMMの概要 |
| FB-DIMMは、DIMM上にAMBチップと呼ぶ一種のメモリ・コントローラを搭載する。これによりパラレル・インターフェイスの従来のDDR2メモリなどを、シリアル・インターフェイスで接続することを可能にする。 |
メモリ・コントローラとAMBチップ間を接続するシリアル・インターフェイスは、1レーン(1bitのデータ転送を行う1対の信号線)当たりのデータ転送レートは3.2Gbits/s〜4.8Gbits/s(製品により異なる)で、上り用に14レーン、下り用に10レーンを用いる(図2)。1チャネルのFB-DIMMインターフェイスは、この24組の高速信号線(合計48ピン)を含む69ピンで構成される。1チャネルのインターフェイスに、2〜8本のFB-DIMM(製品により異なる)が接続可能だ。
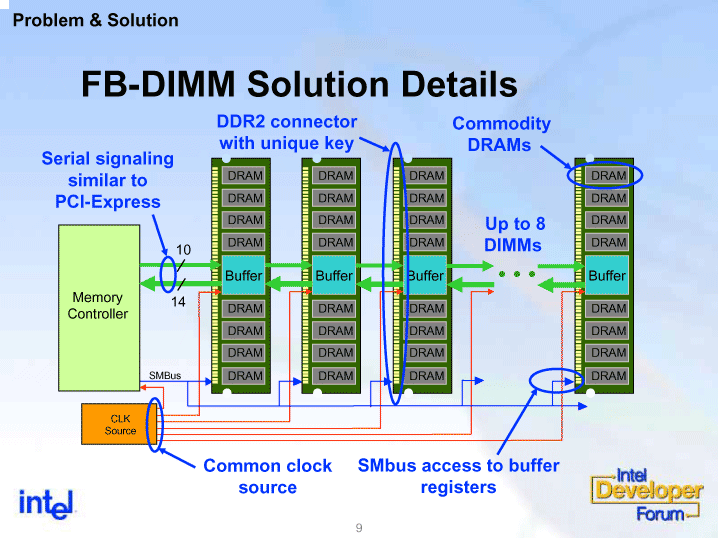 |
| 図2 FB-DIMMの接続形態 |
| 図のようにFB-DIMMは、読み出しと書き込みで帯域が非対称となっている。読み出しが14レーンを利用するのに対し、書き込みは10レーンとなっている。 |
インターフェイスのピン数の少なさは、マザーボード上の信号線の引き回しを容易にするだけでなく、チャネル数を増やすことも容易にする。最初のFB-DIMM対応プラットフォームとなるBensleyプラットフォームに用いられるBlackford(ブラックフォード)チップセットでは、メモリ・コントローラが4チャネルのメモリ・インターフェイスをサポートし、1チャネルに4本のFB-DIMMの実装をサポートする。つまり、これで最大16 DIMMの構成が可能になるわけだ。ポイント・ツー・ポイント接続で、上りと下りが完全に分離されているため、同時に読み書きが可能になることによる性能改善も期待される。
帯域が非対称に設定されている理由は明らかにされていないが、現在マルチプロセッサ対応サーバ向けに提供されているIntel E8500チップセットのメモリ・コントローラとXMB(eXternal Memory Buffer)間も非対称(上り5.33Gbits/s、下り2.67Gbits/s)になっており、恐らく意図したものだろう。書き込みの遅延に比べ、読み出しの遅延はプロセッサのストールにつながることから、プロセッサ・メーカーらしく読み出しを優先したのかもしれない。
また、PCI Expressでは8b/10bエンコーディング(8bitのパラレル・データを10bitのシリアル・データとして送るエンコーディング方式。シリアル・データの中にクロックを埋め込み、データとクロックの転送を1本の信号で行うことを可能にする)で埋め込まれているクロック信号が、FB-DIMMインターフェイスでデータ信号と分離されているのは、8b/10bエンコーディングによるオーバーヘッドを嫌ったものだと思われる。外部バス(拡張スロット)と異なり、メモリ・バスは物理的な長さが限られる上、接続されるデバイスもAMBチップに限定されるため、クロックとデータの信号タイミングがずれにくいことも、両者を分離できた理由として挙げられるだろう。
AMBチップとDRAMチップのインターフェイスは、通常のDDR2/DDR3インターフェイスを用いる。AMBチップはチップセットへのシリアル・インターフェイスと、DRAMへのパラレル・インターフェイス間のプロトコル変換を行うチップだと考えられる。信頼性向上の機能も、基本的にはAMBチップが担っており、DRAMそのものは通常のものがそのまま使える。
つまり、メモリ・メーカーはFB-DIMMのために特別なDRAMを生産する必要はない。バス幅を狭く、スタブを廃したポイント・ツー・ポイントのインターフェイスということで、FB-DIMMにDirect RAMBUS(RDRAM)RIMMとの類似性を感じるが、両者が決定的に異なるのがこの点だ。ライセンス料を払った上で専用のDRAMチップ(ダイ上にRACを内蔵したDRAM)を作る必要があるRIMMに対し、デスクトップPC向けと同じ汎用のDRAMが使えるため量産効果を享受しやすい点が、メモリ・メーカーにとってのFB-DIMMの利点である。
一方、システム・ベンダにとっての利点は、上述したピン数の少なさによる設計の自由度の増大に加え、1つのシステム・デザインを複数のDRAM世代で利用可能ということが考えられる。メモリ・デバイスは、一定の間隔で世代交代を行っており、ここ数年を見ても、DDR SDRAMからDDR2 SDRAMへの更新が行われた。そう遠くない将来、次世代のDDR3 SDRAMも登場してくることだろう。こうしたメモリの世代交代ごとに、基本的にDRAMの動作電圧は下がり、高速化のためにプリフェッチ・サイズが増す。従来のチップセットの場合、こうした変更に合わせて内蔵のメモリ・コントローラを変更しなければならなかった。
| 動作電圧 | プリフェッチ・サイズ | |
| DDR | 2.5V | 2bit |
| DDR2 | 1.8V | 4bit |
| DDR3 | 1.5V | 8bit |
| DDR SDRAMの世代による違い | ||
FB-DIMMの場合、本来のメモリ・コントローラはAMBが内蔵しているため、チップセット側のインターフェイスを変更する必要はない。FB-DIMMへ供給する電源電圧を変える程度で、DDR2からDDR3への切り替えに伴うシステム・デザインの変更は完了すると思われる(その代わりAMBチップはまったく新しいDDR3対応のもの、AMB2が必要になる)。こうした移行の容易さは、システム・ベンダにとっての利点だろう。
ユーザーにとってFB-DIMMの利点としてまず思いつくのは、サポート可能なメモリ・チャネル数の増加と、チャネル当たりでサポート可能なDIMM数の増加のかけ算による、大容量メモリの実現だ。メモリの高速化に伴い、メモリ・チャネルに接続可能なDIMMの数はコンスタントに減少してきた。加えて、既存の信号線の多いパラレル・インターフェイスでは、メモリ・チャネルを増やすことは大幅なコスト・アップにつながる。FB-DIMMであれば、比較的安価に大容量のメモリを実装できるシステムを構築することが可能だ。
| INDEX | ||
| [解説]FB-DIMMがサーバのメモリを変える? | ||
| 1.シリアル・インターフェイスを採用するFB-DIMM | ||
| 2.性能面でも大きなアドバンテージを持つFB-DIMM | ||
| 「System Insiderの解説」 |
- Intelと互換プロセッサとの戦いの歴史を振り返る (2017/6/28)
Intelのx86が誕生して約40年たつという。x86プロセッサは、互換プロセッサとの戦いでもあった。その歴史を簡単に振り返ってみよう - 第204回 人工知能がFPGAに恋する理由 (2017/5/25)
最近、人工知能(AI)のアクセラレータとしてFPGAを活用する動きがある。なぜCPUやGPUに加えて、FPGAが人工知能に活用されるのだろうか。その理由は? - IoT実用化への号砲は鳴った (2017/4/27)
スタートの号砲が鳴ったようだ。多くのベンダーからIoTを使った実証実験の発表が相次いでいる。あと半年もすれば、実用化へのゴールも見えてくるのだろうか? - スパコンの新しい潮流は人工知能にあり? (2017/3/29)
スパコン関連の発表が続いている。多くが「人工知能」をターゲットにしているようだ。人工知能向けのスパコンとはどのようなものなのか、最近の発表から見ていこう
|
|





