解説Intel Coreマイクロアーキテクチャの目指す世界デジタルアドバンテージ 小林 章彦2006/05/13 |
 |
|
|
|
Intelは、IDF Spring 2006ならびにIDF Japan 2006において、次世代プロセッサのマイクロアーキテクチャ「Intel Coreマイクロアーキテクチャ(以下、Coreマイクロアーキテクチャ)」の概要を明らかにした。Pentium 4の世代では、デスクトップPC向けとサーバ向けにNetBurstマイクロアーキテクチャを採用する一方で、モバイル向けにはBaniasマイクロアーキテクチャ(正式な名称ではない)と異なるマイクロアーキテクチャを採用していた。Coreマイクロアーキテクチャでは、再びモバイル向けからサーバ向けまでが同じマイクロアーキテクチャに統一されることになる。
Coreマイクロアーキテクチャは、2006年後半のサーバ/ワークステーション向けの「Woodcrest(ウッドクレスト)」から採用される(現在のモバイル向けIntel Core Duo/SoloはBaniasマイクロアーキテクチャであり、Coreマイクロアーキテクチャではない)。続いてデスクトップPC向け「Conroe(開発コード名:コンロー)」、モバイル向けの「Merom(開発コード名:メロム)」が続いて2006年第3四半期にリリースされる予定だ。
2006年5月8日には、Coreマイクロアーキテクチャを採用したデスクトップPC向けとモバイル向けのプロセッサ・ブランドを「Intel Core 2 Duo」とすることを発表している(ハイエンド向けに「Intel Core 2 Extreme」というブランドも使われる)。なおサーバ向けのブランドは明らかにされていないが、引き続きIntel Xeonが採用されるものと思われる。
ここでは、IDFで明らかになったCoreマイクロアーキテクチャの特徴について解説する。
Coreマイクロアーキテクチャの設計方針
NetBurstマイクロアーキテクチャは、動作クロックを引き上げることで性能向上を目指した設計を採用している。当初、NetBurstマイクロアーキテクチャは、動作クロック5GHzをターゲットにするとIntelは述べていた。しかし実際には、動作クロックの引き上げとともに消費電力が増大し、事実上、4GHzを前にそれ以上の引き上げが行えなくなってしまった。動作クロックが引き上げられない以上、NetBurstマイクロアーキテクチャを採用するプロセッサの性能は頭打ちとなってしまう。2005年、Intelのプロセッサ製品が停滞した理由がここにある。
また市場も大きく変化してきた。サーバは、データセンターの消費電力と発熱が問題になり、性能とともに低消費電力化が求められるようになった。またデスクトップPCも、テレビなどのAV機能の強化とともに静音化が要求され、消費電力が大きい(つまり騒音の大きな冷却ファンが必要となる)プロセッサは敬遠されるようになってきた。性能が求められる一方で、いままで以上に低消費電力が要求されるようになってきたのだ。
一方のBaniasマイクロアーキテクチャは、消費電力や発熱の制限がきついモバイル向けが主用途ということもあり、動作クロックの引き上げよりも、命令の並列実行数を向上させるなどで性能を引き出した。また性能向上とともに、消費電力を低く抑える設計を採用した。こうした方針は、上述の市場のニーズにマッチし、一部のデスクトップPCやサーバなどでもBaniasマイクロアーキテクチャ(Pentium M)が採用されている。
Intelが新たに投入するCoreマイクロアーキテクチャでは、どちらかというとBaniasマイクロアーキテクチャの延長線ともいえる設計を採用した。Coreマイクロアーキテクチャの設計ポイントは、「性能と消費電力のバランスである」とIDFでも述べられている。またNetBurstマイクロアーキテクチャとBaniasマイクロアーキテクチャは、シングルコアを前提とした設計になっていたが、Coreマイクロアーキテクチャはデュアルコア/マルチコアを念頭に置いたものとなっている。
このような設計方針は、パイプラインの段数にも表れている。NetBurstマイクロアーキテクチャではハイパー・パイプライン技術を採用し、Pentium 4ではパイプラインの段数をPentium IIIの2倍となる20ステージとした。一方Baniasマイクロアーキテクチャは、マイクロアーキテクチャの詳細を公開していないため正確なパイプラインの段数は明らかではないが、Pentium II/III(P6マイクロアーキテクチャ)から2〜3ステージ増えた程度であるといわれている。これに対し、Coreマイクロアーキテクチャのパイプラインの段数は14ステージと、Baniasマイクロアーキテクチャとほとんど変わらない。
パイプラインの段数を多くすることは、動作クロックの引き上げに有効なものの、一方で分岐予測の失敗などによるペナルティも大きくなるというデメリットがある(「頭脳放談:第7回 パイプラインと動作クロックの密かな関係?」参照のこと)。Baniasマイクロアーキテクチャでは、それほど動作クロックを引き上げる予定がなかったため、パイプラインの段数はP6マイクロアーキテクチャに比べてあまり増やされていない。Coreマイクロアーキテクチャも同様に、動作クロックを大幅に引き上げる予定はないものと思われる。性能は動作クロックを引き上げるよりも、コアの数を増やす方向で向上させることになるだろう。実際、Intelのプロセッサ・ロードマップを見ても、デュアルコアのWoodcrest/Conroe/Meromの次には、クワッドコアのClovertown(クローバータウン:サーバ向け)/Kentsfield(ケンツフィールド:デスクトップPC向け)が投入される予定となっている。
一方で消費電力については、Baniasマイクロアーキテクチャ以上に低減できる工夫が施されている。Coreマイクロアーキテクチャでは、「インテリジェント・パワー機能(Intelligent Power Capability)」をサポートし、プロセッサの内部を細分化して利用していない部分を省電力モードに移行させたり、バスを必要とされる帯域だけ利用可能にしたりすることで、低消費電力を実現している。デスクトップPC向けのConroeでは、Pentium D 950(動作クロック3.4GHz)との比較において40%以上の性能向上を実現しながら、消費電力を40%以上も低減する。同様にモバイル向けのMeromではIntel Core Duoに対して20%の性能向上を、サーバ向けのWoodcrestではデュアルコアIntel Xeon-2.8GHzに対して80%以上の性能向上と35%以上の消費電力の低減をそれぞれ実現しているということだ。用途ごとに性能向上と消費電力低減の差があるのは、比較しているプロセッサが異なっているに加え、Coreマイクロアーキテクチャでは用途によって味付けを変えることが可能だからということだ。
Coreマイクロアーキテクチャのパイプライン構成
Coreマイクロアーキテクチャのパイプラインの特徴を、以下のブロック図を見ながら解説していこう。この図はデュアルコアの片側のみを示しているが、実際には2次キャッシュを共有して2つのコア(同じブロック)が存在することになる。
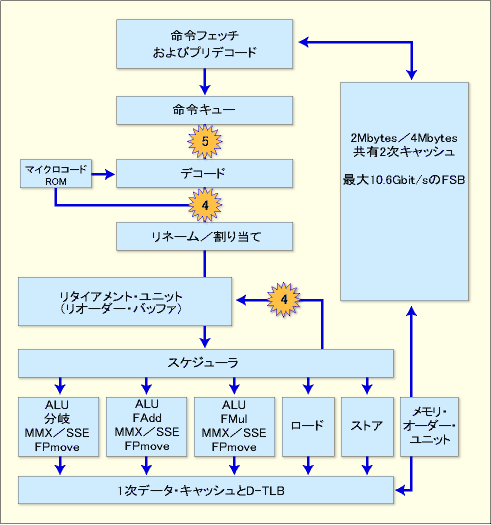 |
| Coreマイクロアーキテクチャのブロック図 |
| これはCoreマイクロアーキテクチャのコア1つ分を表している。Coreマイクロアーキテクチャでは、デュアルコアが基本となっているため、実際には2次キャッシュを共有して同じコア(ブロック)がもう1つ存在することになる。 |
Coreマイクロアーキテクチャでは、命令フェッチとプリデコードで同時に1サイクル当たり4つ以上のx86命令を命令キューに送ることが可能だ。次のステージとなる命令キューでは、最大5つの命令をデコードに送ることができる。
デコードでは、P6/NetBurst/Baniasマイクロアーキテクチャと同様、x86命令を分解し、内部の実行単位となるμOP(マイクロオペレーション)に変換される。P6/NetBurstマイクロアーキテクチャでは、その後のパイプラインのステージにおいて1サイクルで命令が実行できるように複雑なx86命令を複数の単純な命令(μOP)に変換していた。Coreマイクロアーキテクチャでは、基本的に1つのx86命令を1つのμOPに変換することが可能になっている。さらにBaniasマイクロアーキテクチャで導入された「マクロフュージョン」を拡張し、再構成可能な命令の組み合わせが増やされている。マクロフュージョンとは、複数の命令を単一のμOPに再構成することで性能向上を実現するものだ。
例えば、x86命令の比較命令のcmpやtestと条件分岐のjccを組み合わせて1つのμOPにすることが可能になっている。ある値と値を比較し、その結果で別のルーチンにジャンプするというコードは、プログラムでよく使われるものだ。これをcmpとjccそれぞれ別々のμOPに変換して実行した場合、最低でも2サイクルが必要になる。ところが、1つのμOPに変換できれば、1サイクルで実行できることになる。このようにプログラム・コード上で、組み合わされて利用されることが多い命令をフュージョン(融合)させることで、処理性能の向上を実現できるわけだ。
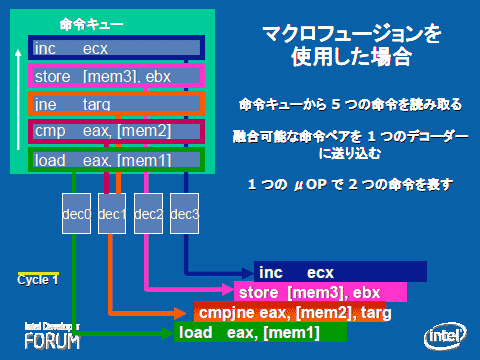 |
| マクロフュージョンを使用した場合の命令実行例(IDF Japan 2006の資料より) |
| マクロフュージョンがない場合、cmpとjneは別々に実行されるため、この5つの命令を実行するためには2サイクルが必要になる。しかしマクロフュージョンを使用することで、cmpとjneを1つの命令「cmpjne」として実行可能になり、結果として1サイクルで5つの命令が実行できるようになる。 |
その後のリネーム/割り当て、リタイアメント・ユニット(リオーダー・バッファ)、スケジューラでは、アウト・オブ・オーダーによって命令が実行される。同時に最大4つのμOPを実行/リタイアさせることができる。NetBurstマイクロアーキテクチャでは、1サイクル当たり最大3つのμOPの実行/リタイアであったので、Coreマイクロアーキテクチャはこの点でも高い性能が期待できる(ただしNetBurstとCoreでは、x86命令が同じμOPに変換されるわけではないので、単純な性能の比較はできない)。
Coreマイクロアーキテクチャは、実行ユニットの拡張も行われている。従来、MMX/SSE命令は64bitの演算を2回行うことで128bitの演算としていた。これに対し、Coreマイクロアーキテクチャでは1サイクルで128bitの演算が可能になっている。音声や画像の処理など、MMX/SSE命令が多用されるアプリケーションでは、大幅な性能向上が実現する可能性がある。
またメモリ・アクセスの性能改善も、Coreマイクロアーキテクチャの大きな特徴である。Coreマイクロアーキテクチャは、スマート・メモリ・アクセスと呼ぶメモリ・サブシステムへのアクセスの最適化によって、メモリ・アクセスのレイテンシを隠ぺいし、システム・パフォーマンスを高めている。
スマート・メモリ・アクセスは、アプリケーションのデータ参照パターンを検出し、データを共有2次キャッシュもしくは1次データ・キャッシュに先読みしておくことによって、メモリ・アクセスのペナルティを低減するというものだ。1つのコア当たり2つのデータ・プリフェッチャと1つの命令プリフェッチャ、動的に2つのコアで共有される2つの2次キャッシュ・プリフェッチャをサポートする。これにより、アプリケーションのデータ参照パターンを検出し、共有2次キャッシュや1次キャッシュに事前にデータを用意しておくことが可能になっている。当然ながら、メイン・メモリよりも、共有2次キャッシュ、1次キャッシュの順でメモリ・アクセスのペナルティは少なくなる。結果として、ロード/ストア演算におけるメモリ・アクセスが速くなることから、演算性能の向上が期待できる。
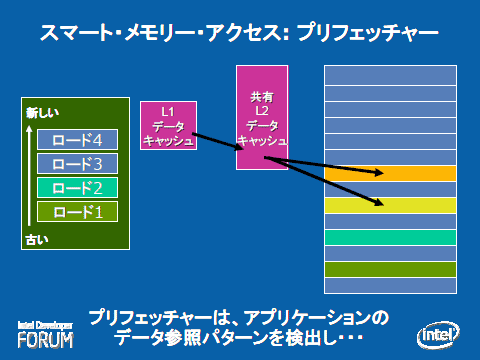 |
| スマート・メモリ・アクセスの概念(IDF Japan 2006の資料より) |
| 事前にアプリケーションのデータ参照パターン(必要とされるデータ)を検出し、メイン・メモリから共有2次キャッシュや1次キャッシュに先読みすることで、メモリ・アクセスのペナルティを低減できる。効率よく先読みするための高度なアルゴリズムが必要である。 |
スマート・メモリ・アクセスには、メモリ・ディスアンビグエーション(メモリの曖昧性解消)と呼ばれる機能が含まれている。これは、実行コアにインテリジェントなアルゴリズムを組み込むことによって、先行するストア命令が完了する前に、ロード命令を投機的に実行し、アウト・オブ・オーダー処理の効率を高めるというものだ。
このスマート・メモリ・アクセスは、プラットフォームやセグメントに合わせて最適化することが可能だとしている。つまり、サーバ向けのWoodcrestとモバイル向けのMeromでは、実装されるアルゴリズムが異なってくる可能性がある。
Coreマイクロアーキテクチャでは、2つのコアが1つの2次キャッシュを共有する構成を採用している(Intelでは、この構成を「アドバンスト・スマート・キャッシュ」と呼んでいる)。片方のコアが大きなキャッシュ容量を必要とする場合、もう片方が利用するキャッシュ容量を削減することで、プロセッサ全体の性能を向上させることができる。各コアに独立した2次キャッシュが実装されていた場合では、片方のコアではキャッシュ容量が足りずにキャッシュ・ミスが頻発し、もう一方のコアではキャッシュに空きが生じている可能性もある。こうした場合でも、動的に各コアが利用可能なキャッシュ容量が変更できるため、キャッシュ・ミスを削減できるわけだ。
本格的なマルチコア時代を開くCoreマイクロアーキテクチャ
このようにCoreマイクロアーキテクチャは、これまでのBaniasマイクロアーキテクチャをベースに消費電力と性能のバランスという観点から設計されたものだ。NetBurstマイクロアーキテクチャまでは、動作クロックを引き上げることが性能向上の主な手段として用いられてきたが、Coreマイクロアーキテクチャでは物理的にプロセッサ・コアの数を増やし、並列性を向上させる方向に大きく舵を切っている。
これまでプロセッサのライフサイクルは、数度の動作クロックの引き上げ、製造プロセスの微細化と同時にキャッシュ容量の増大などのマイナー・チェンジ、数度の動作クロックの引き上げ、マイクロアーキテクチャの変更といったものであった。しかし今後は、動作クロックの引き上げ回数は減り、微細化と同時にコアの数が2倍に増やされ、次にはマイクロアーキテクチャが変更される、といった流れに変わっていくものと思われる(場合によっては、2つのプロセッサを内部で接続して、実質的なコア数を増したバリエーションが挟まることもある)。
このように基本的な性能向上は、コア数を増やすことで図られることになるだろう。しかしこうした性能向上手法は、多人数で利用するサーバ用途では有効なものの、現時点のクライアント用途ではあまり有効でない。というのも、クライアント向けアプリケーションでは、並列性が高くない。また同時に動作しているアプリケーションの数もそれほど多くない。そのため、コアの数を増やしても、ほとんどのコアが遊んだ状態になってしまい、実質的な性能向上に結びつかない可能性があるためだ。逆に、多くのクライアントでマルチコアが前提となれば、それを生かしたアプリケーションや用途が生まれることも期待できる。仮想化技術を利用したセキュリティ機能などはその1例といえるだろう。
間に合わせの感の強かったPentium Dなどに対し、Coreマイクロアーキテクチャはデュアルコアを前提として設計されている。つまりIntelのマルチコア戦略は、Coreマイクロアーキテクチャによって本格的に開かれるわけだ。今後、プロセッサはマルチコアが前提となることから、プログラミング・モデルや利用モデルも大きく変化していくものと思われる。Coreマイクロアーキテクチャの先に何があるのか、Intelが示すコンピュータの利用モデルにも注目したい。![]()
| 更新履歴 | |
|
| 関連記事 | |
| 第7回 パイプラインと動作クロックの密かな関係? | |
| 「System Insiderの解説」 |
- Intelと互換プロセッサとの戦いの歴史を振り返る (2017/6/28)
Intelのx86が誕生して約40年たつという。x86プロセッサは、互換プロセッサとの戦いでもあった。その歴史を簡単に振り返ってみよう - 第204回 人工知能がFPGAに恋する理由 (2017/5/25)
最近、人工知能(AI)のアクセラレータとしてFPGAを活用する動きがある。なぜCPUやGPUに加えて、FPGAが人工知能に活用されるのだろうか。その理由は? - IoT実用化への号砲は鳴った (2017/4/27)
スタートの号砲が鳴ったようだ。多くのベンダーからIoTを使った実証実験の発表が相次いでいる。あと半年もすれば、実用化へのゴールも見えてくるのだろうか? - スパコンの新しい潮流は人工知能にあり? (2017/3/29)
スパコン関連の発表が続いている。多くが「人工知能」をターゲットにしているようだ。人工知能向けのスパコンとはどのようなものなのか、最近の発表から見ていこう
|
|





