【LLTVレポート】劇的ビフォーアフター、匠の技(後編)
システム統合にSOA? RDBMS? bashで十分!
2009/09/07
毎年夏に開催される軽量プログラミング言語(LL:Lightweight Language)をテーマにした「LLイベント」。第7回目となる「LLTV」が、2009年8月29日に東京・中野で開催された。この記事ではプログラムの一部、「大改善!!劇的ビフォーアフター」をレポートする。前編では、Rubyによるfortuneコマンドの“増築”と、Firefox拡張によるslコマンドの実装というネタ系発表をレポートした。中編ではC言語にLisp風のマクロを取り入れ、lsコマンドのソースコードを約半分に削減する匠の技をレポートした。後編となる本記事では、売り場業務が滞りがちだった販売管理システムをbashコマンドで“建て直した”という劇的ビフォーアフターの発表をレポートする。
DBを捨ててテキストファイルに変換
 パイプの匠、當仲寛哲氏
パイプの匠、當仲寛哲氏「100万件ぐらいの検索なら、シェルだけでも1000分の数秒でできます」。こう豪語するのは「パイプの匠」として紹介されたUSP研究所の當仲寛哲氏だ。當仲氏らが改修した良品計画(無印良品)の情報システムは、一般的なPCにLinuxを搭載したシステムで、「シェルスクリプトだけで、バッチ処理、Web画面作成、運用監視などすべて行っている」という。
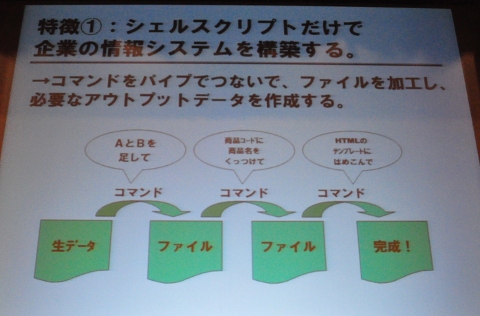 當仲氏らが手がける情報システムは、UNIXのパイプ処理をベースにしているという
當仲氏らが手がける情報システムは、UNIXのパイプ処理をベースにしているという當仲氏らが改修に取り組む以前、無印良品の情報システムは、いくつか問題を抱えていた。商品検索、在庫確認、発注システム、社内電話帳など、個別システムがバラバラに存在したために、「顧客の商品の問い合わせに回答するために複数のシステムにまたがった作業が必要で、手間と時間がかかる」という状態で、店頭で顧客を待たせる結果になることが多かったという。
當仲氏は、このシステムを、Linuxの標準コマンドと自作コマンド群、bashスクリプトで劇的に改善したという。
まず、RDBに入っていたデータを「全部生データで吐き出せと、プレーンテキストに変えてしまった」(當仲氏)という。データベースは一切使わず、いわゆるマスターデータも含めてデータはすべてテキストファイル。「データベースと違って更新という概念がない。発生したデータはすべて残していく、大福帳方式」(當仲氏)。テキストファイルであるため、圧縮やバックアップにも特別な仕組みは不要だ。
コマンドを自作、パイプ処理でアプリ作成
テキストとして記録したデータのカラムを足し合わせたり、最新のものを切り出したりといったテキスト処理だけで複雑な業務処理を行う。さまざまなテキストデータを加工、統合して、HTMLファイルまで作ってしまうという。それまでバラバラだったシステムも、「1画面で、すべての情報が見れたり、連携ができるようになった」(當仲氏)。
 作成するbashスクリプトは、コマンドを組み合わせた多段パイプ処理
作成するbashスクリプトは、コマンドを組み合わせた多段パイプ処理テキストの処理には標準コマンドのほか、「Linuxのコマンドでは足りないので、C、Java、Pythonで自作コマンドも作っている」(當仲氏)。例えば、フィールドのセレクト(self)、サムアップ(sm)、縦横変換(map)、桁揃え(keta)など自作コマンドやsed、awkを組み合わせ、「コマンドをパイプでつないで加工して、つなぐだけで最終的な形を作っている。長い場合にはパイプを30本ぐらい一気につなげて書くようなアプリもある」(當仲氏)という。bashのシェルスクリプトとして書かれたアプリのソースは、短く、読みやすい。データベースのようにスキーマがないため、項目の追加や変更も容易で、システムの改変や新規アプリの開発が機敏にできるのが特徴だという。「ユーザーのニーズを低コストであっという間に作れる」(當仲氏)。
テキストファイルとはいえ膨大な商品点数を扱うため、1つのファイルに数十万行が含まれるケースもある。「(テキストファイルを検索したり書き換えたりすると)遅いんじゃないかと思われるかもしれませんが、最近のPCは非常に速いので、ファイルサイズが1GBぐらいあっても全件なめるのに10秒を切る」(當仲氏)。ソートも十分に高速で実用的という。
當仲氏はデモンストレーションとして、26万レコードを含む商品データをgrepで検索しても、たかだか0.5秒で全文検索が終了することを示してみせた。さらに、商品名を1文字ずつ切り出して、それらの文字をファイル名に含むようにしてマスターファイルを分割。この分割したファイルを検索対象とすることによって100万点の商品検索であっても所要時間を1000分の1秒オーダーに縮めることが可能ということを実演してみせた。
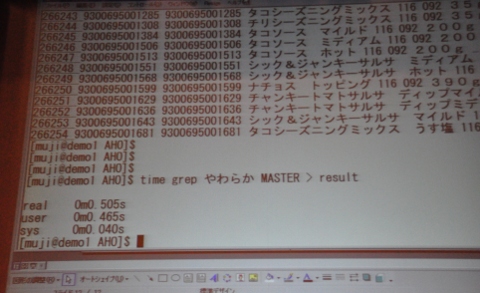 26万行のマスターファイルをgrepしても0.5秒。26万行というと、そこそこのサイズに思えるが、実は68MBしかないし、今どきのPCは非常にパワフルなので検索やソート処理も楽々というわけだ
26万行のマスターファイルをgrepしても0.5秒。26万行というと、そこそこのサイズに思えるが、実は68MBしかないし、今どきのPCは非常にパワフルなので検索やソート処理も楽々というわけだ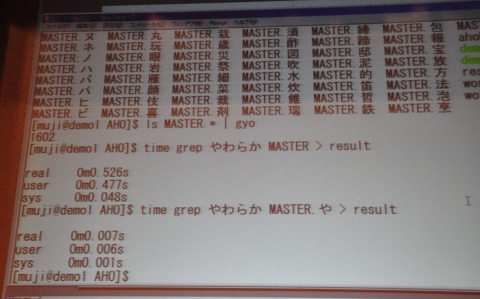 商品名の先頭文字別にマスターファイルを分割すれば、さらに検索は高速に
商品名の先頭文字別にマスターファイルを分割すれば、さらに検索は高速にサイロ化する業務システムの連携強化や統合といえば、「SOAやWebサービスによる疎結合」という話がITベンダの提案のお決まりコース。数十万点を超える商品データベースとなれば、もちろんRDBMSの出番だ。しかし、すべての企業の情報システムで、本当にそのような大げさな仕組みが必要なのだろうか? 當仲氏らの成功事例は、21世紀になった現在も、標準入出力とパイプ、小回りの利くコマンド群の組み合わせというUNIX設計哲学を踏襲したアプローチが通用する領域が、思いのほか広いことを示しているのかもしれない。
関連記事
情報をお寄せください:
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
キャリアアップ
注目のテーマ




転職/派遣情報を探す


「ITmedia マーケティング」新着記事
「サイト内検索」&「ライブチャット」売れ筋TOP5(2025年5月)
今週は、サイト内検索ツールとライブチャットの国内売れ筋TOP5をそれぞれ紹介します。
「ECプラットフォーム」売れ筋TOP10(2025年5月)
今週は、ECプラットフォーム製品(ECサイト構築ツール)の国内売れ筋TOP10を紹介します。
「パーソナライゼーション」&「A/Bテスト」ツール売れ筋TOP5(2025年5月)
今週は、パーソナライゼーション製品と「A/Bテスト」ツールの国内売れ筋各TOP5を紹介し...