なぜTwitterは低遅延のままスケールできたのか
秒間120万つぶやきを処理、Twitterシステムの“今”
2010/04/19
 Twitterのシステム・アーキテクト、Nick Kallen氏
Twitterのシステム・アーキテクト、Nick Kallen氏ユーザー同士のつながりを元に時系列に140文字のメッセージを20個ほど表示する――。Twitterのサービスは、文字にしてしまうと実にシンプルだが、背後には非常に大きな技術的チャレンジが横たわっている。つぶやき数は月間10億件を突破、Twitterを流れるメッセージ数は秒間120万にも達し、ユーザー同士のつながりを表すソーシャル・グラフですらメモリに載る量を超えている。途方もないスケールのデータをつないでいるにも関わらず、0.1秒以下でWebページの表示を完了させなければならない。そのために各データストレージは1〜5ms程度で応答しなければならない。
Twitterのリスト機能の実装でプロジェクトリーダーを務めたこともあるNick Kallen氏が来日し、2010年4月19日から2日間の予定で開催中の「QCon Tokyo 2010」で基調講演を行った。「Data Architecture at Twitter Scale」と題した講演では、Twitterが最初に実装した素朴なシステムから、どのような課題に直面し、それをどうやって解決してきたかを概説した。ローカリティ(局所性)を考慮したデータのパーティショニング戦略の重要性や、それがアクセスパターンに強く依存したものであること、あるいは重たい計算処理が発生するクエリでは事前に処理を行っておくことなど、興味深い技術的洞察に満ちた講演だった。
 Twitterが配信するメッセージは秒間120万にも達するという
Twitterが配信するメッセージは秒間120万にも達するという単純なパーティショニングでは解決しない
サービスの構造がシンプルなTwitterは、サービス開始当初には実装もシンプルだったようだ。各つぶやきのIDをプライマリキーとして、ユーザーIDやテキスト、時刻などを1つのテーブルに保存。これをマスター・スレーブ構成とすることで、readの性能を上げるというストレートなスケーリングを行っていたという。
 もともとのTwitterのDBスキーマ
もともとのTwitterのDBスキーマmemcachedによる高速化も行ったものの、最初に直面した課題は意外にもディスク容量の上限だったという。つぶやきの数が30億に近づき、800GBというディスク容量の上限の9割にまで迫った時期があるという。「800GBを超えるサイズのディスク・アレイを導入することは避けたかった」(Kallen氏)というあたりは、Web系企業らしい発想で、これに対処するために、パーティショニングを行ったという。
パーティショニングとは、例えばユーザーIDを偶数、奇数に分けて2つのDBに分けて保存するテクニック。特定のユーザーのつぶやきを表示する場合、IDが偶数か奇数かで問い合わせすべきDBが一意に決まるため、分割すればするほどレスポンスが上がり、1つ1つのDBのサイズも抑えられる。
ただ、ユーザーIDに基づくパーティショニングでは、特定のIDを持つつぶやきを見つけることができなくなる。そのIDのつぶやきを誰がしたかが分からないからだ。このため、せっかくパーティショニングした複数のDBをすべて検索しなくてはいけなくなる。
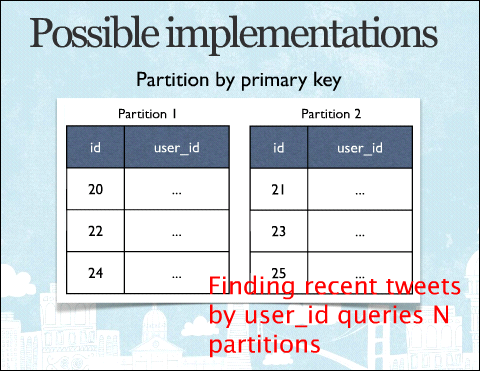 パーティショニングの1つの方法。つぶやきのIDを元に分けることが考えられるが、この分割方法ではユーザーIDに対応するつぶやきの検索には全パーティションに対するアクセスが発生してしまう
パーティショニングの1つの方法。つぶやきのIDを元に分けることが考えられるが、この分割方法ではユーザーIDに対応するつぶやきの検索には全パーティションに対するアクセスが発生してしまうつぶやきのIDでパーティショニングしても、逆の問題が起こる。特定のIDを持つつぶやきがどのパーティションにあるかは分かるが、あるユーザーIDに紐付いたつぶやきのIDは、結局すべてのパーティションを検索しないと分からないからだ。
時系列にパーティショニング
つぶやきの量が多すぎるため、単一のテーブルに保存するのは非現実的。かといって、ユーザーIDやつぶやきIDに基づいて何らかの形で分割するというのも、あまりうまくいかない。
そこで現在のTwitterでは、時系列のパーティショニングを行っているという。1月のつぶやき、2月のつぶやき、3月のつぶやき、今月(4月)のつぶやき、というように時間軸に沿ってデータを分割しているのだという。
 現在のTwitterのデータのパーティショニング方法。時系列に分割しているという
現在のTwitterのデータのパーティショニング方法。時系列に分割しているというこの分割戦略は「当初はとてもまずい実装のように思えた」(Kallen氏)という。n個のパーティションに分割したら、そのアクセス時間の平均はO(n)となるからだ。ところがTwitterというサービスには、Kallen氏が「時間的局所性」(temporal locality)と呼ぶ独特のアクセスパターンがある。「実際にはほとんどのクエリは、より新しい情報へのバイアスがかかっている」(同)からだ。ほとんどの人のリクエストは最新のパーティションに対するクエリで完結する。すべてのユーザーがアクティブなわけではないため、「あるユーザーの直近のつぶやき20件」は、複数のパーティションにさかのぼっていくことになるが、それでもこの戦略によりアクセス時間の平均は事実上O(1)となっているのだという。
今後はFacebookで開発されたオープンソースのCassandraを使い、つぶやきのIDとユーザーIDのそれぞれをプライマリキーとしたテーブルを使う計画だという。
メール配送に似た非同期の仕組み「fan out」
Twitterで次に大きな問題となるのはタイムラインだ。
タイムラインにはフォローしている人のつぶやきが流れてくるが、これはつまり以下のようなSQL文に相当する。
 サービス開始当初の素朴なクエリ。矢印で示した部分がメモリ上に載らなくなり、非常に遅くなったという
サービス開始当初の素朴なクエリ。矢印で示した部分がメモリ上に載らなくなり、非常に遅くなったという上のようなストレートな実装では、フォロワー数が増えていくると途端にスケールしなくなる。メモリに載り切らずにディスクアクセスが発生し、レスポンスが落ちるためだ。ディスクアクセスのペナルティは大きく、1秒以下で終わるはずのページの描画が数秒かかるということになる。
さらにTwitterの技術上の課題を大きくしているのは、リストやブロック関係、あるいは「@someone」というリプライによってメッセージの配信先が変わるということだ。これは非常に大きな計算処理である一方、「Hadoopを使って50分かけて処理するタイプの問題ではない」(Kallen氏)。あくまでも数msという低遅延で行わなくてはいけない。
こうした問題への対処方法として、Kallen氏は2つのアプローチを紹介した。
1つは「fan out」と呼ぶメール配送に似たアーキテクチャを使うこと(fan outは漢字で書くと“扇出”か。風で一気にまき散らすようなイメージ)。各ユーザーのタイムラインをメールの受信箱のように見立てて、そこにメッセージを配信する。つぶやきはいったんmemcachedに保存され、それが各受信箱(タイムライン)に送られるが、その配送処理は非同期のオフライン処理だという。ただ、オフラインといっても夜間バッチのような半日単位というものではなく、秒単位の遅延を上限としたものであるという。
 現在Twitterではメール配送に似た仕組みでフォロワーにつぶやきを配送しているという
現在Twitterではメール配送に似た仕組みでフォロワーにつぶやきを配送しているというもう1つの工夫は、フォローと被フォローの関係をそれぞれ別にデータに持つこと。論理的には片方向のグラフだけ持っておけば十分だが、あえて「誰をフォローしているか」「誰にフォローされているか」に分けてデータ化しておく。データの整合性に気を付ける必要はあるものの、こうしておけばクエリは特定パーティションへのアクセスで完結するため、メモリに乗り切らないという問題も解消するのだという。
こうした仕組みにより、書き込み側のデッドロック(すべてのつぶやきは巨大な単一のデータセットに放り込まれる)を解消しつつソーシャル・グラフがメモリに乗り切らないという課題を乗り越えて、リアルタイム性の高いサービスを実現できている。
2008年時点でTwitter上で生まれるつぶやきの数は秒間30だったが、2010年4月現在は約700にまで膨れ上がっている。スポーツイベントやオスカーの発表時など、ピーク時には秒間2000に達するという。そして1つのつぶやきは平均600個もfan outされるため、秒間120万のメッセージ配送を処理する能力が求められるという計算だ。
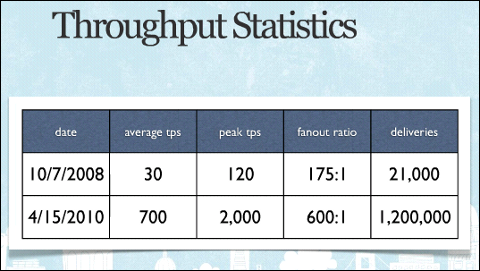 2008年時点と現在とでのTwitterの統計情報。秒平均30だったつぶやき生成速度は700にまで上がり、その結果最大で秒間120万程度のメッセージを配送しているという
2008年時点と現在とでのTwitterの統計情報。秒平均30だったつぶやき生成速度は700にまで上がり、その結果最大で秒間120万程度のメッセージを配送しているというTwitterは現在もまださまざまな技術的課題を抱えている。例えば検索インデックスについても時系列のパーティショニングを行っているため、検索される頻度が低い単語などでは最新パーティションにインデックスがないため何もヒットしないということが起こる。このため、現在MySQLベースで行っている検索インデックスを時系列のパーティショニングだけでなく、ドキュメント単位にパーティショニングする案や、MySQLの代わりに全文検索エンジンの「Lucene」を使うという案を検討しているという。
原理は自明でも定石のない世界
余談だが、Nick Kallen氏は2008年9月にTwitterに加わる以前から、Ruby on Railsコミュニティでは広く知られたハッカーだった。RailsのORM層であるActiveRecordで、より抽象度の高いクエリを構成できる「Named_scope」を実装したのがKallen氏だ。Named_scopeを使えば、例えば「公開フラグが立っているブログエントリ」という条件に名前を付けておくことで、積集合の演算を端的に表現できるようになる(参考)。このNamed_scopeの発想をさらに押し進めて関係代数に基づいてKallen氏が実装したのがRuby向け汎用データクエリライブラリ「Arel」で、これは、まもなく正式版がリリースされる次期Ruby on Railsのメジャーバージョンアップ、Ruby on Rails 3にも含まれる。ArelはC#などにあるLINQに似て、条件をメソッドチェーンとしてつなげていくことができる。
Arelというクエリの抽象化を行う実装を行ったKallen氏だが、Twitterのような実サービスで重要なのは、むしろ、パーティショニングやローカリティの利用の方法論にはこれという単一のアプローチが存在しないという認識を持つことだと指摘する。「すべてのエンジニアリング上の解決策というのは、一時的なものだ」(Kallen氏)。
Twitter規模のスケーラビリティの問題を抱えるエンジニアは多くはないかもしれないが、今後、巨大なデータセットに対してリアルタイム性の高いシステムを設計・実装することがあれば参考になるのかもしれない。
関連記事
情報をお寄せください:
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
キャリアアップ
注目のテーマ




転職/派遣情報を探す


「ITmedia マーケティング」新着記事
「サイト内検索」&「ライブチャット」売れ筋TOP5(2025年5月)
今週は、サイト内検索ツールとライブチャットの国内売れ筋TOP5をそれぞれ紹介します。
「ECプラットフォーム」売れ筋TOP10(2025年5月)
今週は、ECプラットフォーム製品(ECサイト構築ツール)の国内売れ筋TOP10を紹介します。
「パーソナライゼーション」&「A/Bテスト」ツール売れ筋TOP5(2025年5月)
今週は、パーソナライゼーション製品と「A/Bテスト」ツールの国内売れ筋各TOP5を紹介し...