あの谷川氏が聞きたかった、ITエンジニアが知るべきインメモリデータベースSAP HANAのポイント
「ERPを速くしたい」――その想いから始まった。SAP HANAは超高速インメモリデータベースと聞いているが、技術的に一体何が特徴なのか、何ができるのか? ITエンジニアとして知っておくべき高速データベース技術の実態を徹底的に聞いた。
座談会参加メンバー
SAPジャパン リアルタイムコンピューティング事業本部 シニアマネージャ 大本 修嗣氏
SAPジャパン リアルタイムコンピューティング事業本部 プリンシパルデータベースアーキテクト 花木 敏久氏
SAPジャパン リアルタイムコンピューティング事業本部 プリンシパルアーキテクト 松舘 学氏
SAPジャパン ソリューション統括部 ビジネスアナリティクス・テクノロジー本部 ビジネスアナリティクス・テクノロジー部 シニアソリューションスペシャリスト 森﨑 敏朗氏
有限会社タルク・アイティー 代表取締役社長 谷川耕一氏
SAPの「HANA」をご存じだろうか。SAP HANAは「超高速インメモリデータベース」であるということを知っていても、その詳細な動きや、そもそも何に使うべきものなのかまでおさえているエンジニアはまだ少ないかもしれない。
SAP HANAの可能性はどこにあるのか。今回、SAP HANAのスペシャリストたちと、IT、そしてデータベース業界に詳しい有限会社タルク・アイティー 代表取締役社長の谷川耕一氏がその可能性、そしてテクノロジーについて本音で語った。谷川氏は特にデータベース業界に詳しく、自身のブログで業界トレンドを発信する傍ら、Web媒体でもデータベース専門のチーフキュレーターとして活躍している。業界を知り尽くした谷川氏が、ITエンジニアの関心を代弁してSAP HANAの「中の人」に「技術の話」を聞いた。
そもそも「SAP HANA」は、何を目的としているのか?
谷川氏 まず、SAP HANAは「インメモリデータベース」で速い、というイメージが強く、実際に何ができるのか、どうして開発したのか、といったエピソードはあまり聞こえてきません。このあたりのお話はどうなんでしょうか?
松舘氏 SAP HANAはデータベースそのものを作ろうと考えてスタートしたものではなく、最初は「ERPシステムを速くしたい」というところから始まりました。その後、このアーキテクチャはERP以外にも展開できるのではないかと考えたのです。
SAP HANAの特徴は4つあります。「カラムストア/ローストア対応」「SQLインターフェイス」「インメモリ圧縮」「マルチコア/並列化」です。
SAP HANAは大量データを超高速に処理する「インメモリ専用データベース」です。カラムストア/ローストアともに対応し、分析向けのカラムストア型データベースとしても、トランザクション処理向けのローストア型データベースとしても利用できます。エンジン部分はインテルさまとの技術協力のもと、開発しています。CPUのコアが増え、多くのメモリが扱える部分をソフトウェアで最適化した、マルチコア前提のデータベースです。
統計系の機能としては、予測アルゴリズムなどの独自の統計関数ライブラリを持っておりSAP HANAのエンジンで処理できます。さらにオープンソースの「R」言語を統合、全文検索エンジンも持っています。現在はアプライアンスとして、認定パートナー7社から出荷されています。分析系だけではなく、2013年にはSAP ERPにもSAP HANAが利用される予定で、トランザクション系でも使えるインメモリデータベースです。
SAP HANAがカラムストアとローストアの両方をカバーする理由
谷川氏 この機会に私が深掘りしたいと思っていたのは、カラムストアだけでなくローストアにも対応している点です。SAP HANAでは行列変換を内部的に行っているということですが、いまSAP HANAが対応しているのはカラムストア(列)のみですか?
花木氏 いまはOLAPとしての利用がほとんどですから、カラムで持っていますね。ただ、現在でもデータベースそのものの管理系情報の一部はローストア(行)で持っています。アクティブなコネクションや、データベースの統計情報(パフォーマンスデータ)などはローの形で持っています。また、運用面で見ると、通常のデータベースでは定期的に統計情報の更新をする必要があるのですが……。
森﨑氏 多くのRDBMSは、統計情報を使いコストベースのオプティマイザを利用して最適な実行計画を立てることで性能の劣化を防いでいますが、これはSAP HANAのカラムストアの場合、いらなくなります。夜間バッチで統計情報を更新していかないと、パフォーマンスが低下するというようなことはありません。この時間がいらなくなるわけです。単純にデータをロードする時間だけでいい。リアルタイムで更新し、リアルタイムで表示する。24時間動きっぱなしでも、パフォーマンスの問題が発生する心配はないのです。
花木氏 実は現在、SAPの内部では、SAP ERP向けのSAP HANAの開発が進んでいます。2013年前半には詳細を公表できるでしょう。OLTP用途で動作するSAP HANA第1弾として、SAP CRMの特定顧客向けリリースを既に開始しています。
トランザクション処理に最適なのはやはりローストア形式です。1件1件のトランザクションが飛んでくるような内容では、ローストアのデータベースが効率的。しかし、売上をまとめるなど、確定したデータに対しての解析処理はカラムストアで処理する方が都合がいいことが多いのです。
UPDATE処理はどのように行われているのか?
谷川氏 SAP ERPのようにトランザクション処理系でSAP HANAを利用するとき、UPDATE処理はどう動いているのでしょう? どこにアップデートが働くのでしょうか?
花木氏 カラムストア、ローストアにはおのおの適正がある一方で、苦手な処理もあります。SAP HANAはそれらのデメリットをカバーするように設計されています。
松舘氏 まず、OLAPの場合、カラムストアを利用し、UPDATEやINSERTのときは、カラムストア内のアペンドのみを行う「デルタストレージ」を利用しています。このストレージに対して、更新分だけを渡せばいい、という構造です。
森﨑氏 さらにいうと、SAP HANAにはコンシステントビューマネージャという機構があります。このビューでどこが変更されたかを全て管理しています。
READ処理については、このコンシステントビューマネージャーにより読み取りに最適化されたメインストレージと差分データのデルタストレージの両方の最新データを見ているので、一貫性については問題ありません。デルタストレージに入ったデータも定期的にマージを行い、デルタストレージとメインストレージを統合する処理を行います。もし、このタイミングでさらに処理が行われた場合でも、新しいデルタストレージが作られるため、データ整合性の問題が発生しないようになっています。
そのため、どこに書き込まれても最新のデータがどこにあるのかを把握でき、SQLが発行されたときに正しいデータを取得できるわけです。
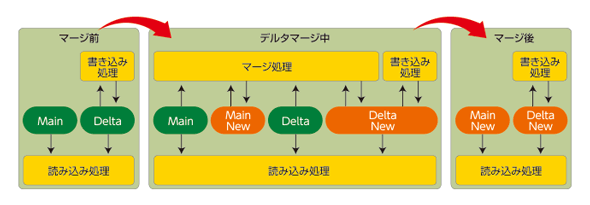 デルタマージが実行されているときの挙動イメージ
デルタマージが実行されているときの挙動イメージ松舘氏 次に、OLTPの場合、SAP HANAの内部ではまずローバッファでデータを受け取ります。これをある一定の間隔でカラムバッファに転送してカラム変換を行い、最終的にカラムに保管するという2段階の変換処理を行っています。ローストア型だけの場合、さほどデータ圧縮が効かないため、多くのデータ容量が必要となります。そのため、ワーキングバッファとしてまずバッファで受けて、最終的にテーブルとしてストアする際には、圧縮して読み込みに最適化した状態が可能なカラムストアに入れています。
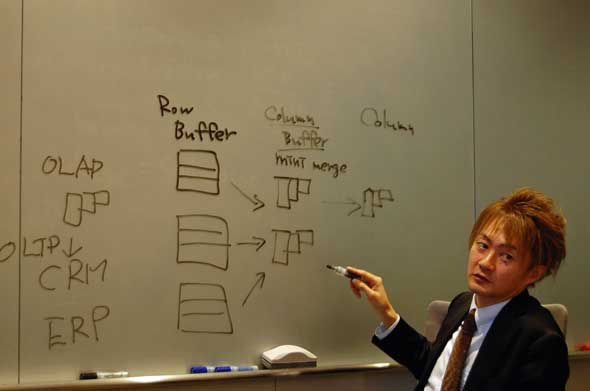 松舘氏はローバッファのカラムへの変換と圧縮の挙動について図示しながら解説してくれた
松舘氏はローバッファのカラムへの変換と圧縮の挙動について図示しながら解説してくれた森﨑氏 いままでのローストアでは、行を特定してからそのデータをUPDATEしていましたが、SAP HANAのこの方式の場合なら、INSERTのみを行えばいいのです。その分、速く処理できるわけです。
どうスケールさせているのか
谷川氏 並列処理についてお話を聞かせてください。サーバ構成が複数台に別れているとき、サーバのメモリ空間はSAP HANAからはどう見えているのですか? 複数台のサーバのメモリは1台として見えているのでしょうか。
松舘氏 シェアードナッシング的なイメージと考えてください。
森﨑氏 つまり、1台のサーバごとにSAP HANAがそれぞれ入っていて、自分のノードに入っているデータを把握しています。
松舘氏 例えば、年ごとにテーブルを分けておいて、どのテーブルにどの要素があるかというトポロジー情報をマスターネームサーバが持っている、というイメージです。
森﨑氏 テーブル分割は、ハッシュ、レンジ、ラウンドロビンの3モードに対応しています。
谷川氏 ハッシュパーティショニングだけではないのですね。これだけかと思っていました。
松舘氏 パフォーマンス的にはハッシュを使うと有利な場合が多いでしょう。分割し、分散配置したデータがどこにデータがあるかはマスターネームサーバが管理します。
谷川氏 マスターネームサーバは1台だけの構成ですか?
森﨑氏 HA構成をとる場合ならば、マスターネームサーバはバックアップとして3台まで持つことができます。
谷川氏 データの更新があったとき、その3台がノード間のデータ整合性を確保するためのデータのやりとりで競合が発生することはあるのでしょうか?
森﨑氏 マスターネームサーバは、実際のデータというよりもシステムのトポロジ情報とデータがどのように分散しているかの情報になります。そのため、テーブル分割がどのサーバで構成されているのかなどのデータが置かれています。ですから、ネームサーバの情報は、クエリによりどのサーバにデータがあるかについてのテーブル情報を参照する場合が多いです。どのようなデータを保持しているのかといった情報については、実際のデータが格納されている各サーバ上で管理を行っています。
インメモリは揮発性が心配? SAP HANAはどうしているか
谷川氏 もう1つ気になっているのは、トラブル時の対応です。何かあったときに戻す(リカバリする)ことは可能なのでしょうか。
松舘氏 いまのところ、テーブル単位で戻すことは考えていません。ただし、ポイント・イン・タイム・リカバリは可能です。障害発生前の時点のデータベースに戻すことができます。
谷川氏 ハッシュパーティショニングでSAP HANAを構成した場合は、全てのノードを戻さなくてはならない?
松舘氏 各ノードがそれぞれのノードのデータとログを持っています。リストアする際は全てのノードを戻すことになりますが、ノード間のマージ処理は不要です。
谷川氏 リカバリは作業が完了するまでの時間がどれくらいかが重要な関心事です。戻す時間はどのくらいかかるのでしょうか。
松舘氏 データ量に依存しますが、各ノードそれぞれ並列に戻せるので、大幅な時間がかかるような処理ではありません。
谷川氏 なるほど、並列に戻せるわけですね。バックアップ/リカバリについては気にされているユーザーも多いと思います。
森﨑氏 バックアップツールについては、2012年11月末に出荷したSPS5よりバックアップ用のAPIを提供し、既に他のシステムで使っているバックアップツールをSAP HANAに対しての認定プログラムを開始する予定です。
インメモリのアーキテクチャで基幹系の心配どころ
谷川氏 可用性についてもう少し聞かせてください。分析系であればそこまで気にする必要はないかもしれませんが、ERPのようなトランザクション系の処理を行う場合、SAP HANA自体を多重化して持つことは可能ですか?
松舘氏 現在のSAP HANAにおいてHA構成を取る場合、ストレージの機能を使ってミラーリングを行い、セカンダリのシステムを遠隔地のデータセンターで構成することは可能です。これはSAP HANAの機能ではなく、あくまでストレージの機能で、ハードウェアアプライアンスベンダさまごとに固有のソリューションを提供いただいています。
現在、新機能として計画しているのは、プライマリからセカンダリへログを送り、ウォームスタンバイ構成を取ることが可能になるものです。
 座談会のメンバー。左から森崎氏、谷川氏、松舘氏、花木氏
座談会のメンバー。左から森崎氏、谷川氏、松舘氏、花木氏取材を終えて:基幹システムを速くするための技術の集大成としてのSAP HANA
インメモリデータベースとしてのイメージが先行していたSAP HANAだが、実際の技術詳細を知ると、その特性は、速さだけではないことが分かる。
SAP ERPという基幹システムを安全かつ安定的に動作させ、ビジネススピードを支えることを目的に開発がスタートしたSAP HANAには、実に多くの最先端技術トレンドが含まれている。それゆえに他の用途にも十分に展開可能な、従来のデータベース製品以上の仕上がりに至ったというわけだ。その開発思想や技術実装の詳細については、今後SAP自らが発信していく予定だという。今後の情報にも注目していきたい。
■この記事に関連するホワイトペーパー

【技術解説】速いだけじゃない!インメモリーコンピューティングSAP HANAがビジネスを変えられる理由
最新のテクノロジーを駆使した高速データベースであり、かつ高速なリアルタイム分析プラットフォームとしての一面も持つSAP HANA。意思決定のための情報をリアルタイムで手に入れるためにSAPが作り上げたテクノロジーの全てをここに紹介します。
関連記事
 「SAP HANA Cloud」計画を発表、AWSマーケットプレイスでの展開は即日スタート
「SAP HANA Cloud」計画を発表、AWSマーケットプレイスでの展開は即日スタート
AWS MarketplaceにSAP HANAが登場。パブリッククラウドを使ったスモールスタートビジネスへもHANA適用の門戸を開く- Database Watch 2012年6月版:HANAはSAPの中軸製品になれる?
今月は、最近注目を集めているインメモリデータベース「SAP HANA」SP4の発表に伴って、担当者の方にHANAの生い立ちや戦略、なかなか見ることができない実機を見せてもらいました。また、IBMとマイクロソフトによる“夢!?”のコラボレーションを取材しました。 - SAP、HANA 2.0でOLAPとOLTPの共存を実現
独SAPは11月15日、中国・北京において「SAPPHIRE NOW in Beijing」を開幕した。アジア地域では初の開催となる「SAPPHIRE NOW」は、同社が成長市場として期待しており、2015年までに20億ドルの投資を約束した中国での開催となった。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
提供:SAPジャパン株式会社
アイティメディア営業企画/制作:@IT 編集部/掲載内容有効期限:2013年1月18日
関連ホワイトペーパー

最新のテクノロジーを駆使した高速データベースであり、かつ高速なリアルタイム分析プラットフォームとしての一面も持つSAP HANA。意思決定のための情報をリアルタイムで手に入れるためにSAPが作り上げたテクノロジーの全てをここに紹介します。
関連記事
AWS MarketplaceにSAP HANAが登場。パブリッククラウドを使ったスモールスタートビジネスへもHANA適用の門戸を開く
今月は、最近注目を集めているインメモリデータベース「SAP HANA」SP4の発表に伴って、担当者の方にHANAの生い立ちや戦略、なかなか見ることができない実機を見せてもらいました。また、IBMとマイクロソフトによる“夢!?”のコラボレーションを取材しました。
独SAPは11月15日、中国・北京において「SAPPHIRE NOW in Beijing」を開幕した。アジア地域では初の開催となる「SAPPHIRE NOW」は、同社が成長市場として期待しており、2015年までに20億ドルの投資を約束した中国での開催となった。
関連リンク
技術資料や動画コンテンツ、ソリューション一覧など、SAP HANAの情報を集約しています。
事例やファクトシートなど、SAPが提供するSAP HANA関連の資料を検索できます。
インタビュアーについて
本記事でインタビュアを担当した谷川氏のブログ。
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。