ビジネスのデジタル化の落とし穴「何か遅い」アプリやシステムの原因、分かってますか?:ユーザー体験を向上させる「攻めの統合監視」とは
デジタルトランスフォーメーションを進める企業が重要視する監視や計測は、顧客との重要な接点となるスマホアプリなどのフロントエンドのユーザー体験において重要な役割を果たすケースもある。フロントエンドからバックエンドまで監視する企業向けソフトウェアを展開しているゾーホージャパンの担当者に、ユーザーに「何か遅い」と思わせないためのノウハウを聞いた。
ビジネスのデジタル化が進む中、「何か遅い」システムが増えてきた
デジタル技術を使って新しい事業を生み出したり、企業の在り方そのものを変えていったりできるとして熱い視線が注がれているデジタルトランスフォーメーション。さまざまな企業が取り組みを進めているが、そうした企業が一様に口をそろえることがある。監視や計測の重要性だ。
デジタルトランスフォーメーションの取り組みでは、センサーやユーザーから得られるデータを解析して新しい知見を得て、さらなる製品開発や品質向上に生かすことが有効なアプローチの1つとされる。センサーやユーザーからデータを得る際には、「データがきちんと収集されているか」「何か問題が発生していないか」といったことを監視し、きちんと計測できなければならない。監視や計測ができてはじめてデータを活用するための道が拓けるといっていい。
監視や計測が重要なのは、IoTやAI(人工知能)のような最先端の取り組みだけではない。ビジネスのデジタル化で顧客との重要な接点となるスマホアプリなどのフロントエンドのユーザー体験において重要な役割を果たすケースもある。加えて、バックエンドでは、顧客とのやりとりを処理するためのトランザクションの監視が不可欠になるケースも少なくない。「攻めのIT」といわれるようなデジタルビジネスを推進するためには、それに関わる全てのシステムが正しく監視、計測されることが必要なのだ。
フロントエンドからバックエンドまで監視する企業向けソフトウェアを展開しているゾーホージャパン ネットワーク管理カンパニー リーダーの小栗大幸氏は、最近の企業が抱えやすい課題について、こう話す。
「最近、お客さまからよく聞かれるようになった言葉に『何か遅いんだよね』があります。システムは障害なく動いていて、リソース不足のアラートが上がってきているわけではない。でも、スマホから自社Webサイトにアクセスしてみると、どこか遅いと感じる。調べても原因をはっきり特定できない。実は、この『何か遅い』は、ビジネスのデジタル化が進む中で多発してきているのです」(小栗氏)
自動化、複雑化したシステムを“人”が管理するのは限界
「何か遅い」と感じる背景には、さまざまな要因がある。分かりやすい例でいえば、自動化の仕組みを備えたクラウド環境がある。
クラウド環境では、リソースが足りなくなると自動的にスケールアウトしたり、サービスに問題が発生したら自動的にサーバが再起動したりといった仕組みが採用されている。最近ではブルーグリーンデプロイメントやImmutable Infrastructureといった仕組みで、サーバが再起動するとそれまで動いていた環境が廃棄され、新たに新しい環境として立ち上がる。サービス監視の面では、これがやっかいな問題となる。
「新しい環境でサービスが自動的に立ち上がるので、表面上は問題になることはありません。しかし、実際にはシステムに何かしらの問題が発生してサーバが再起動されています。そのイベントをうまく捉えられなかったり、捉えても気付かなかったりするのです。気付いたとしても、問題が発生してシステムは廃棄され、新しい環境になってしまっていますから、原因の特定がしにくいという問題もあります」(小栗氏)
実際に調べてみると、サーバ内のアプリケーションの設計に問題があり、そのアプリケーションが起動するたびに、ネットワーク帯域を圧迫して、システム全体を遅延させていたことがあるという。遅くなり過ぎるとサーバが新しく再起動されるため、気付かなかったのだ。
もう1つの要因としては、仮想化技術がサーバだけではなく、ネットワークやストレージといったシステム全体に拡大してきたことが挙げられる。クラウドが普及する以前は、これらの装置はそれぞれ分離されて管理されることが多く、障害の切り分けも比較的容易だった。だが、ネットワークやストレージまでが仮想化された環境で稼働するようになり、問題が発生してもどこから手を付けていいかの判断がしにくくなった。
「ひと言で言えば、運用が複雑になったのです。かつては、ネットワークやストレージに問題があると見た目で分かるので、1次対応を自社で済ませ、後はベンダーに任せることができました。でも今は、どこに問題があるかすら分かりません。管理ツールもサーバやネットワークを統合的に見ることができなかったり、逆に見るべき項目が増え過ぎたりして、頼りにならなくなりました」(小栗氏)
自動化し、複雑化したシステムを人が判断するには限界があるということだ。さらに言えば、「何か遅い」を数値化する困難さもある。以前から、特定の業務アプリケーションでは「保存するデータ量が増えるにつれシステムが遅くなる」事象はよく見られた。だが、こうした遅れをきちんとエンドユーザー体感として計測はしてこなかった。「何か遅い」ことは分かっても、「どういうタイミングで、どこまで速くすればユーザーが納得するか」のノウハウもない状況なのだ。
複雑化したシステムを、統合的に運用管理できる「ManageEngine OpManager」
こうした悩みを抱えた企業に対して、ゾーホージャパンが提案しているのが、アプリケーションのパフォーマンスからサーバの稼働状況、ネットワークのトラフィック分析までを統合的に監視することだ。小栗氏は、こう話す。
「何か遅いと感じたら、まずは、エンドユーザー体験の遅さを計測します。いつから遅くなったか、どのくらい遅くなったかを数値化すれば、明らかに遅いと判断できます。遅いと分かったら、その原因を調べます。システム構成に変更は見られないか、データベースの書き込みに遅れが出ていないか、ネットワークトラフィックが増えていないか、増えたとしたらどのアプリケーションが帯域を使っているかなどを調査していき、さらにアプリケーションを構成するミドルウェアやデータベースまでドリルダウンして問題を取り除くのです」(小栗氏)
これを実現するのが、ゾーホージャパンが提供する運用管理ソフト「ManageEngine OpManager(以下、OpManager)」だ。シンプルで使いやすいことに定評があるソフトで、全世界100カ国1万社以上に導入実績がある。ゾーホーでは、IT運用管理のためのソフトウェアを機能や目的ごとにさまざまな製品をラインアップしており、OpManagerは、それらのソフトウェアをプラグインやオプション機能として内部に取り込むことができる。これにより、多種多様なシステムを一元的に監視、計測することが可能になる。
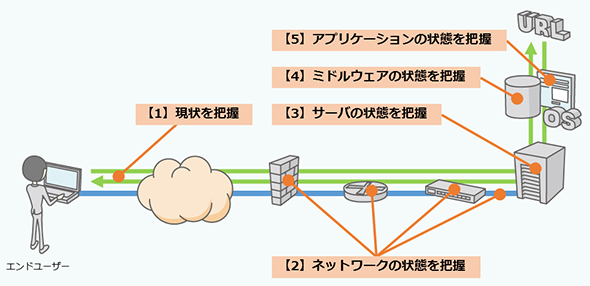

まず、サービスを利用するエンドユーザーが体感する応答時間の現状、さらにはミドルウェアやアプリケーションの状態を把握する(図の【1】【4】【5】)に効果を発揮するのが、アプリケーションパフォーマンス監視ソフト「ManageEngine Applications Manager」(以下、Applications Manager)だ。プラグインとしてOpManager上で使用できる。
「エンドユーザー体感を可視化するには、例えば、ECサイトの訪問者が商品を『買い物かご』に入れてから精算するまでのページ遷移を登録します。そのページ遷移の開始から終了までに、どのくらいの時間がかかっているかを計測しグラフ化します。しきい値を設定し通知を受けることで、今サービスを利用しているユーザーがページ表示の遅延によりストレスを感じている可能性が高いことを把握できます。ページ表示が遅くなるボトルネックまで可視化されるので、アプリケーションのUIを改善したり、A/Bテストに活用したりといった、開発と運用が連携した使い方も可能です」(小栗氏)
次のステップであるネットワーク状態の把握(図の【2】)で効果を発揮するのが、OpManagerの標準機能であるネットワーク機器のリソース監視やトラフィック監視だ。ネットワーク機器のリソース監視では、ルーターやスイッチ、ファイアウォールが対象となり、トラフィック監視では、帯域の使用量やネットワーク構成を確認でき、死活監視や可用性監視も行える。
ネットワークトラフィックを詳細に知りたい場合は、フローデータによるネットワーク解析ソフトウェア「ManageEngine NetFlow Analyzer」(以下、NetFlow Analyzer)を、オプション機能としてOpManager上で利用できる。NetFlow Analyzerは、Cisco NetFlow、sFlow、IPFIX、Cisco AppFlowといったフロー技術を利用して、ネットワーク帯域の利用状況を詳細に監視、解析するソフトだ。IPアドレスごと、アプリケーションごとに帯域がどのくらい占有されているかといった、SNMP(Simple Network Management Protocol)ではできないトラフィックの詳細状況を把握できる。
次のステップであるサーバ状態の把握(図の【3】)では、OpManagerの標準機能であるサーバのリソース監視機能が有効だ。CPUやメモリ、ディスクの監視といった基本から、プロセス監視、サービス監視、URL監視、ログ監視などまで行える。仮想サーバの監視もサポートしており、物理環境も含めて分かりやすく可視化できる。可視化機能はカスタマイズ可能で、サーバルームのフロアマップに合わせてラック配置を3Dで表示したり、自社施設におけるWi-Fi設置環境を地図として表示したりできる。
サーバ状態に問題が見つからなければ、さらにミドルウェアの状態まで把握する必要も出てくるだろう(図の【4】)。Applications Managerは、Webサーバやプリケーションサーバ、データベースサーバのパフォーマンスを監視し、アプリケーションの遅延や障害切り分けを容易にする。加えて、SQLクエリの返り値を監視し、可視化したり、正常でない場合に通知したりする機能を実装している。
このように、OpManagerに、APMプラグイン(=Applications Manager)とフロー分析オプション(=NetFlow Analyzer)を組み合わせることで、エンドユーザー体験など、原因がよく分からず対処が難しかった課題に対応できるようになるわけだ。
エンドユーザー体験を向上させた、統合監視の成功事例
OpManagerを使うと、実際にどんな効果が得られるのか。これについては事例を紹介するのが分かりやすいだろう。
デジタルトランスフォーメーションの取り組みを支える好事例ともいえるのが「福岡 ヤフオク!ドーム」全体をマップで可視化した、福岡ソフトバンクホークスのケースだ。ドーム内には、200台超の無線アクセスポイントが配置され、それを支えるためのサーバ、ルーター、スイッチ、ファイアウォール、UPSなど、数百台のインフラ機器が存在する。これらを実際の地図に当てはめて、どの機器に障害が発生しているかを一目で分かるようにしたのだ。
 ヤフオクドームのビジネスビュー(※使用イメージです。実際のものとは異なります)
ヤフオクドームのビジネスビュー(※使用イメージです。実際のものとは異なります)ヤフオクドームでは、来場者向けサービスを拡充する中で、ITインフラ機器の監視対象が拡大し、障害対応の迅速化が課題になっていた。また、管理の負荷が高まり、管理コストが増大することも課題だった。そこで、使いやすく設定が容易で、コストメリットが大きいOpManagerに注目。システム管理の内製化を進めながら、OpManagerを使ってインフラ全体を自分たちで管理できるようにした。この取り組みの結果、障害対応は迅速化し、内製化などによって、5年で1000万円以上のコスト削減を達成できたという。
ECサイトへの適用事例としては、工場・作業現場のプロツール(工場副資材)を販売するサイト「トラスコ オレンジブック.Com」を運営するトラスコ中山のケースが興味深い。同社では、売上の6割がWebサイトからの注文で、ITシステムはビジネスに欠かせない基盤になっている。課題は、サイトの突然のパフォーマンス低下だった。エンドユーザーから「サイトがおかしい」といった指摘を受けることがあり、早急な対応が求められた。監視ツールは導入していたが、アラートメールが来るだけのもので、システムダウンでログそのものが消えることもあった。
そこで、OpManagerをApplications Managerとともに導入し、サーバ約50台に対し「142」のしきい値を設定。死活監視に加え、3段階のしきい値を使って、システム全体のパフォーマンス監視を行えるようにした。これにより、従来はアラームやクレームを受けた後の事後対応しかできなかったところが、しきい値によって事前に異常検知が可能になった。また、ユーザーに影響を与える前に、障害の予兆を検知することもできるようになった。
いずれの事例においても、OpManagerによりエンドユーザー体験が向上したのは言うまでもないだろう。
シンプルで使いやすい障害対応や予兆検知の自動化で「攻めの統合監視」を
こうした事例からも分かるように、デジタルトランスフォーメーションに向けた企業の取り組みが進む中、「何か遅い」という言葉が示すような、原因不明のトラブルは増え続けている。中には、障害の原因を特定することも、障害そのものの発生に気付かないケースもある。
もちろん運用管理ソフトベンダーは、こうした新しいトラブルに対応できるよう開発に力を注いでいる。だが、その結果、運用項目が増えて管理が難しくなったり、導入コストが高くなったりしては意味がない。デジタル時代の取り組みでは、トライ&エラーやスモールスタートがしばしばキーワードとして挙げられる。これは、ビジネスを支えるITシステムにもいえることだろう。
その点、OpManagerはシンプルで使いやすく、導入のハードルも低い。前述のヤフオクドームのようなマップビューをGUI上でドラッグ&ドロップしながら簡単に設定できる他、障害対応や予兆検知についても、通知の仕方から通知後の対応を自動化するワークフローも同様に設定できる。

導入については、サイトからダウンロードして、すぐに試すことができる評価版もあるので、「何か遅い」と感じたら、すぐに試すことができる。「何か遅い」をデジタルビジネス時代の活動に向けた第一歩としてとらえ、「攻めの統合監視」への取り組みを進めていきたいところだ。
関連記事
 「運用保守を収益化」――究極のコスト削減を実現する運用管理ツールの条件
「運用保守を収益化」――究極のコスト削減を実現する運用管理ツールの条件
仮想化、クラウドでシステムが複雑化し、運用管理も煩雑になっている近年、多くの企業が運用管理の効率化に頭を悩ませている。だが多数の企業に対し、運用保守をサービスとして提供しているSIerの視点で見れば、「複雑・大規模なインフラを効率的に運用する」ことはビジネスの大前提。そうしたプロの視点で見ると、多くの企業でありがちな、コスト、リソース、スキルという運用管理の三大課題を解決する上では何がポイントになるのだろうか? 約100社のインフラ運用を担うオリゾンシステムズに話を聞いた。 Cisco NetFlowが、ネットワーク運用の武器として再び注目される理由
Cisco NetFlowが、ネットワーク運用の武器として再び注目される理由
シスコが推進してきたフロー可視化技術のNetFlowが、この2、3年新たな注目を浴びるようになってきたという。それはなぜなのか。シスコシステムズとゾーホーのエンジニアたちが、NetFlowの真髄を語る。 「ManageEngine OpManager」を編集部が徹底検証
「ManageEngine OpManager」を編集部が徹底検証
仮想化、クラウドでシステムインフラが複雑化する一方で、運用管理の現場ではスキルの属人化やスキルレベルのばらつきに悩んでいるケースが多い。そうした中、ゾーホージャパンの統合監視ツール「ManageEngine OpManager」はグローバルでシェアを伸ばし続けている。支持される理由とは何なのか? 編集部が実際に触って、その使い勝手を体感してみた。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
提供:ゾーホージャパン株式会社
アイティメディア営業企画/制作:@IT 編集部/掲載内容有効期限:2017年4月30日
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。