第2回では、フェイルオーバークラスタの仕組みについてLinuxではどのように実現されているのか解説しました。フェイルオーバークラスタは、可用性(Availability)を高める技術として非常に有効な手段です。今回は、高可用性システムを構築するために考えなければならない周辺技術などについて考えてみたいと思います。
Single Point of Failureの排除
高可用性システムを構築するうえで、求められるもしくは目標とする可用性のレベルを把握することは重要です。これはすなわち、システムの稼働を阻害し得るさまざまな障害に対して、冗長構成をとることで稼働を継続したり、短い時間で稼働状態に復旧したりするなどの施策を費用対効果の面で検討し、システムを設計するということです。
Single Point of Failure(SPOF)とは、システム停止につながる部位を指す言葉であると第1回で解説しました。クラスタシステムではサーバの多重化を実現し、システムのSPOFを排除することができますが、共有ディスクなど、サーバ間で共有する部分についてはSPOFとなり得ます。この共有部分を多重化もしくは排除するようシステム設計することが、高可用性システム構築の重要なポイントとなります。
クラスタシステムは可用性を向上させますが、前回書いたとおり、フェイルオーバーには数分程度のシステム切り替え時間が必要となります。従って、フェイルオーバー時間は可用性の低下要因の1つともいえます。このため、高可用性システムでは、まず単体サーバの可用性を高めるECCメモリや冗長電源などの技術が本来重要なのですが、ここでは単体サーバの可用性向上技術には触れず、クラスタシステムにおいてSPOFとなりがちな下記の3つについて掘り下げて、どのような対策があるか見ていきたいと思います。
- 共有ディスク
- 共有ディスクへのアクセスパス
- LAN
■共有ディスク
通常、共有ディスクはディスクアレイによりRAIDを組むので、ディスクのベアドライブはSPOFとなりません。しかし、RAIDコントローラを内蔵するため、コントローラが問題となります。多くのクラスタシステムで採用されている共有ディスクではコントローラの二重化が可能になっています。
二重化されたRAIDコントローラの恩恵を受けるためには、通常は共有ディスクへのアクセスパスの二重化技術を同時に使用する必要がありますが、次で説明するようにLinuxにおいてはまだ有効に活用できていないのが現状です。ただし、二重化された複数のコントローラから同時に同一の論理ディスクユニット(LUN)へアクセスできるような共有ディスクの場合、それぞれのコントローラにサーバを1台ずつ接続すればコントローラ異常発生時にノード間フェイルオーバーを発生させることで高可用性を実現できます。
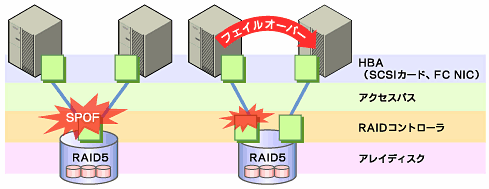
一方、共有ディスクを使用しないデータミラータイプのフェイルオーバークラスタでは、すべてのデータをほかのサーバのディスクにミラーリングするため、SPOFが存在しない理想的なシステム構成を実現できます。ただし、欠点とはいえないまでも、次のような点について考慮する必要があります。
- ネットワークを介してデータをミラーリングすることによるディスクI/O性能(特にwrite性能)
- サーバ障害後の復旧における、ミラー再同期中のシステム性能(ミラーコピーはバックグラウンドで実行される)
- ミラー再同期時間(ミラー再同期が完了するまでクラスタに組み込めない)
すなわち、データの参照が多く、データ容量が多くないシステムにおいては、データミラータイプのフェイルオーバークラスタを採用するというのも可用性を向上させるポイントといえます。
■共有ディスクへのアクセスパス
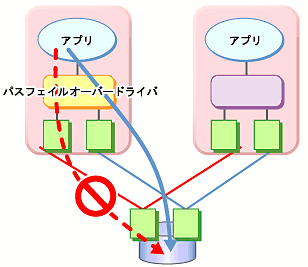
共有ディスク型クラスタの一般的な構成では、共有ディスクへのアクセスパスはクラスタを構成する各サーバで共有されます。SCSIを例に取れば、1本のSCSIバス上に2台のサーバと共有ディスクを接続するということです。このため、共有ディスクへのアクセスパスの異常はシステム全体の停止要因となり得ます。
対策としては、共有ディスクへのアクセスパスを複数用意することで冗長構成とし、アプリケーションには共有ディスクへのアクセスパスが1本であるかのように見せることが考えられます。これを実現するデバイスドライバをパスフェイルオーバードライバなどと呼びます。パスフェイルオーバードライバは共有ディスクベンダーが開発してリリースするケースが多いのですが、Linux版のパスフェイルオーバードライバは開発途上であったりしてリリースされていないようです。現時点では前述のとおり、共有ディスクのアレイコントローラごとにサーバを接続することで共有ディスクへのアクセスパスを分割する手法がLinuxクラスタにおいては可用性確保のポイントとなります。
■LAN
クラスタシステムに限らず、ネットワーク上で何らかのサービスを実行するシステムでは、LANの障害はシステムの稼働を阻害する大きな要因です。クラスタシステムでは適切な設定を行えばNIC障害時にノード間でフェイルオーバーを発生させて可用性を高めることは可能ですが、クラスタシステムの外側のネットワーク機器が故障した場合はやはりシステムの稼働を阻害します。
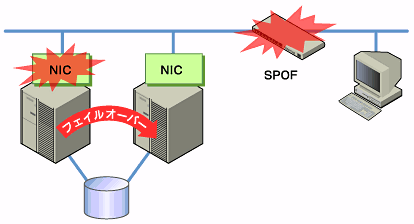
このようなケースでは、LANを冗長化することでシステムの可用性を高めます。クラスタシステムにおいても、LANの可用性向上には単体サーバでの技術がそのまま利用可能です。例えば、予備のネットワーク機器の電源を入れずに準備しておき、故障した場合に手動で入れ替えるといった原始的な手法や、高機能のネットワーク機器を冗長配置してネットワーク経路を多重化することで自動的に経路を切り替える方法が考えられます。また、インテル社のANSドライバのようにNICの冗長構成をサポートするドライバを利用するということも考えられます。
ロードバランス装置(Load Balance Appliance)やファイアウォールサーバ(Firewall Appliance)もSPOFとなりやすいネットワーク機器です。これらもまた、標準もしくはオプションソフトウェアを利用することで、フェイルオーバー構成を組めるようになっているのが普通です。同時にこれらの機器は、システム全体の非常に重要な位置に存在するケースが多いため、冗長構成をとることはほぼ必須と考えるべきです。
可用性を支える運用
■運用前評価
システムトラブルの発生要因の多くは、設定ミスや運用保守に起因するものであるともいわれています。このことから考えても、高可用性システムを実現するうえで運用前の評価と障害復旧マニュアルの整備はシステムの安定稼働にとって重要です。評価の観点としては、実運用に合わせて、次のようなことを実践することが可用性向上のポイントとなります。
- 障害発生個所を洗い出し、対策を検討し、偽障評価を行い実証する
- クラスタのライフサイクルを想定した評価を行い、縮退運転時のパフォーマンスなどの検証を行う
- これらの評価をもとに、システム運用、障害復旧マニュアルを整備する
クラスタシステムの設計をシンプルにすることは、上記のような検証やマニュアルが単純化でき、システムの可用性向上のポイントとなることが分かると思います。
■障害の監視
上記のような努力にもかかわらず障害は発生するものです。ハードウェアには経年劣化があり、ソフトウェアにはメモリリークなどの理由や設計当初のキャパシティプラニングを超えた運用をしてしまうことによる障害など、長期間運用を続ければ必ず障害が発生してしまいます。このため、ハードウェア、ソフトウェアの可用性向上と同時に、さらに重要となるのは障害を監視して障害発生時に適切に対処することです。万が一サーバに障害が発生した場合を例に取ると、クラスタシステムを組むことで数分の切り替え時間でシステムの稼働を継続できますが、そのまま放置しておけばシステムは冗長性を失い次の障害発生時にはクラスタシステムは何の意味もなさなくなってしまいます。
このため、障害が発生した場合、すぐさまシステム管理者は次の障害発生に備え、新たに発生したSPOFを取り除くなどの対処をしなければなりません。このようなシステム管理業務をサポートするうえで、リモートメンテナンスや障害の通報といった機能が重要になります。Linuxでは、リモートメンテナンスの面ではいうまでもなく非常に優れていますし、障害を通報する仕組みも整いつつあります。
以上、今回はクラスタシステムを利用して高可用性を実現するうえで必要とされる周辺技術やそのほかのポイントについて書きました。簡単にまとめると次のような点に注意しましょうということになるかと思います。
- Single Point of Failureを排除または把握する
- 障害に強いシンプルな設計を行い、運用前評価に基づき運用・障害復旧手順のマニュアルを整備する
- 発生した障害を早期に検出し適切に対処する
次回はロードバランスクラスタについて触れる予定です。
Copyright © ITmedia, Inc. All Rights Reserved.