多様化するクラスタ方式:Linuxクラスタリングへの招待(1)
現在では、コンピュータを導入していない企業はないといえるほど、私たちの業務はコンピュータに依存しています。また、インターネット利用による新しいビジネスは、コンピュータがあればよいというものではなく、いかにサービスを提供し続けるかが成功のための重要なカギとなります。例えば、1台のマシンが故障や過負荷によりダウンしただけで、顧客へのサービスが全面的にストップしてしまうことがあります。そうなると、莫大な損害を引き起こすだけではなく、顧客からの信用を失いかねません。
このような事態に備えるのがクラスタシステムです。クラスタシステムを導入することにより、万一のときのシステム稼働停止時間(ダウンタイム)を最小限に食い止めたり、負荷を分散させることでシステムダウンを回避することが可能になります。
「群れ」「房」の言葉どおり、クラスタシステムとは「複数のコンピュータを一群(または複数群)にまとめて、信頼性や処理性能の向上を狙うシステム」といえます。しかし、その種類はさまざまで、次のように分類することができます。
- HA(High Availability)クラスタ
- フェイルオーバークラスタ
- 共有ディスクタイプ
- データミラータイプ
- 遠隔クラスタ
- 負荷分散クラスタ
- ロードバランスクラスタ
- 並列データベースクラスタ
- フェイルオーバークラスタ
- HPC(High Performance Computing)クラスタ
それでは、これから主にHAクラスタを中心に、それぞれのクラスタについて説明していきます。
HA(High Availability)クラスタ
一般的にシステムの可用性を向上させるには、そのシステムを構成する部品を冗長化し、Single Point of Failure(注1)をなくすことが重要であると考えられます。HAクラスタとは、サーバを複数台使用して冗長化することにより、システムの停止時間を最小限に抑え、業務の可用性(availability)を向上させるクラスタシステムをいいます。
システムが停止しては困るようなデータベースなどの基幹業務をはじめ、アプリケーションサーバ、ファイルサーバのほか、最近ではダウンタイムが致命傷となるインターネット上のサーバ(ファイアウォールサーバやメールサーバなど)にクラスタシステムが求められています。
注1 Single Point of Failureとは、コンピュータの構成要素(ハードウェアの部品)が1つしかないために、その個所で障害が起きると業務が止まってしまう弱点のことを指します。
フェイルオーバークラスタ
■共有ディスクタイプ
クラスタシステムでは、サーバ間でデータを引き継がなければなりません。このデータを共有ディスク上に置き、ディスクを複数のサーバで利用する形態を共有ディスクタイプといいます。
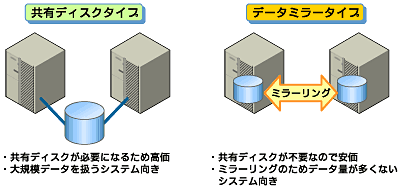 図1 HAクラスタ構成図
図1 HAクラスタ構成図業務アプリケーションを動かしているサーバ(現用系サーバ)で障害が発生した場合、クラスタシステムが障害を検出し、待機系サーバで業務アプリケーションを自動起動させ、業務を引き継がせます。これをフェイルオーバーといいます。クラスタシステムが引き継ぐ業務は、ディスク、IPアドレス、アプリケーションなどのリソースと呼ばれるもので構成されています。
クラスタ化されていないシステムでは、アプリケーションをほかのサーバで再起動させると、クライアントは異なるIPアドレスに再接続しなければなりません。しかし、多くのクラスタシステムでは、業務単位に仮想IPアドレスを割り当てています。このため、クライアントは業務を行っているサーバが現用系か待機系かを意識する必要はなく、まるで同じサーバに接続しているように業務を継続できます。
データを引き継ぐためには、ファイルシステムの整合性をチェックしなければなりません。通常は、ファイルシステムの整合性をチェックするためにfsckやchkdskを使用しますが、ファイルシステムが大きくなるほどチェックにかかる時間が長くなり、その間業務が止まってしまいます。この問題を解決するために、ジャーナリングファイルシステムなどでフェイルオーバー時間を短縮します。
業務アプリケーションは、引き継いだデータの論理チェックをする必要があります。例えば、データベースならばロールバックやロールフォワードの処理が必要になります。これらによって、クライアントは未コミットのSQL文を再実行するだけで、業務を継続することができます。
障害からの復帰は、障害が検出されたサーバを物理的に切り離して修理後、クラスタシステムに接続すれば待機系として復帰できます。業務の継続性を重視する実際の運用の場合は、ここまでの復帰で十分な状態です。
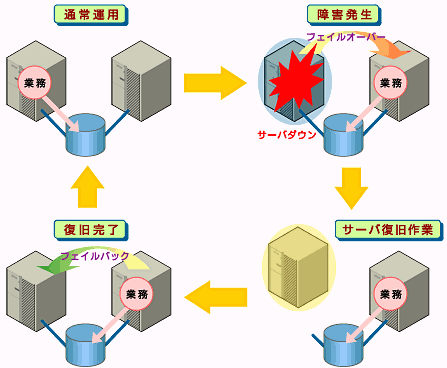 図2 障害発生から復旧までの流れ
図2 障害発生から復旧までの流れフェイルオーバー先のサーバのスペックが低かったり、双方向スタンバイ(注2)で過負荷になるなどの理由で元のサーバで業務を行うのが望ましい場合には、元のサーバで業務を再開するためにフェイルバックを行います。
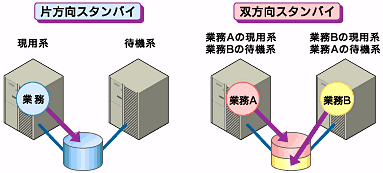 図3 HAクラスタの運用形態
図3 HAクラスタの運用形態■データミラータイプ
前述の共有ディスクタイプは大規模なシステムに適していますが、共有ディスクはおおむね高価なためシステム構築のコストが膨らんでしまいます。そこで共有ディスクを使用せず、各サーバのディスクをサーバ間でミラーすることにより、同じ機能をより低価格で実現したクラスタシステムをデータミラータイプといいます。
しかし、サーバ間でデータをミラーする必要があるため、大量のデータを必要とする大規模システムには向きません。
アプリケーションからのWrite要求が発生すると、データミラーエンジンはローカルディスクにデータを書き込むと同時に、インターコネクト(注3)を通して待機系サーバにもWrite要求を振り分けます。待機系のデータミラーエンジンは、受け取ったデータを待機系のローカルディスクに書き込むことで、現用系と待機系間のデータを同期します。
アプリケーションからのRead要求に対しては、単に現用系のディスクから読み出すだけです。
現用系のディスクに障害があった場合、データミラーエンジンは障害発生ディスクへの読み書きは行わず、インターコネクト経由で待機系ディスクに対してのみ読み書きを実行します。
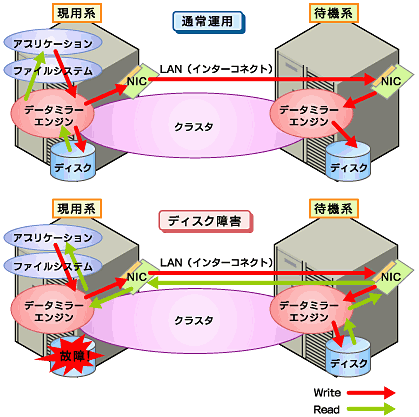 図4 データミラーの仕組み
図4 データミラーの仕組みデータミラーの応用例として、スナップショットバックアップの利用があります。データミラータイプのクラスタシステムは2カ所に共有のデータを持っているため、待機系のサーバをクラスタから切り離すだけで、バックアップ時間をかけることなくスナップショットバックアップとしてディスクを保存する運用が可能です。
注3 インターコネクトとは、サーバ間をつなぐネットワークのことで、クラスタシステムでは死活監視のために必要になります。データミラータイプでは死活監視に加えてデータの転送に使用することがあります。
■遠隔クラスタ
HAクラスタの運用例の1つに、遠隔地にフェイルオーバーする遠隔クラスタがあります 。万一地震などの災害が発生して一方のサイトが破壊されても、ほかのサイトで運用を継続できます。
負荷分散クラスタ
■ロードバランスクラスタ
インターネット上でのビジネスが盛んになるにつれ、サーバアクセスをより快適に、またサーバがダウンする確率を大幅に下げ、可用性を高めることが求められています。これらの観点からロードバランス機能を持つスイッチや専用アプライアンスが大変注目されています。
ロードバランスクラスタ(ロードバランス装置など)を導入することにより、急激なアクセス数の増加に対応できるだけでなく、サーバを止めずにサーバの更新やメンテナンスを行うことができます。
例えば、ECサイトなどでサーバを止めてしまうことは、せっかくアクセスしてきた顧客やビジネスチャンスを逃すことにもなりかねません。あらかじめ負荷の増加を見越してロードバランスクラスタ構成にしておくことで、負荷の増加に対応できるとともに、サーバ1台当たりの処理負荷を低減させて全体のスループットを高めることができます。
図5は一般的なロードバランスクラスタの例です。この例では、ロードバランス装置を2重化しています。また、ロードバランスグループとしてWebサーバとFTPサーバの2つを構成しています。サーバのどれかがダウンした場合でも、残りのサーバがクライアントからのリクエストを処理します。さらにアクセスが増えるようであれば、新規にサーバを追加することもできます。クライアントへのレスポンスが快適であること、システムが止まらないことが重要なのです。
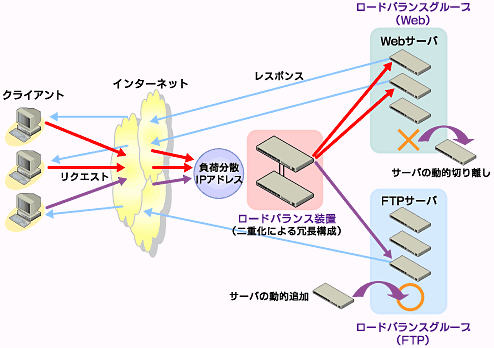 図5 ロードバランスクラスタ構成例
図5 ロードバランスクラスタ構成例分散方式としては、DNSを使ったラウンドロビンの利用が一般的でしたが、ロードバランス専用の装置では、さまざまな方式による分散が可能となっています。ロードバランスクラスタについては、第4回で詳細に説明する予定です。
■並列データベースクラスタ
並列データベースクラスタとは、複数台のデータベースサーバで処理の分散と可用性の向上を行うクラスタシステムをいいます。並列データベースエンジンは、サーバ間通信によるデータベースの管理と各サーバの状態監視を行うことで、処理の分散と可用性の向上を行っています。
HPC(High Performance Computing)クラスタ
1990年代中盤、パーソナルコンピュータの性能向上を背景に、NASAのBeowulfプロジェクトによるクラスタシステムが発展しました。Beowulfは、既存の低価格なマシンとLinux環境でオープン化されている並列処理プログラミングを利用しているため、安価でアプリケーションの変更作業の手間がない科学技術計算用のコンピュータシステムを実現しています。
SCoreもBeowulfとほぼ同時期にRWCP(RealWorld Computing Partnership:新情報処理開発機構)により開発が始まりました。Beowulfと異なり、SCoreは当初からクラスタコンピューティングのためのシステムソフトウェア環境の提供を目的にしているLinuxベースのオープンソースです。クラスタとしての特徴は、独自のPM通信機構(注4)による高速化、SCore-DによるTSS(Time Sharing System)環境、ジョブスケジューリングの機能が挙げられます。
注4 この通信機構に名前がなかったころ、すでにAM(Active Messages)、FM(Fast
Messages)という通信ライブラリがありました。FM開発者がAM変調よりよいというジョークをいったこともあり、この開発者は独自の通信機構をPMと名付けたそうです。
以上、クラスタシステム入門編としてクラスタシステムを紹介してきました。次回からはクラスタシステムの詳細を解説していきます。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。