IPv6も、IPv4と同じIPプロトコルであり、そのコンセプトや機能の多くはヘッダを通して知ることができる。今回は、IPv6のヘッダフォーマットを通して、その基本的な機能を探ることにする。図1(IPv4)と図2(IPv6)のヘッダを比較しながら、違いを確かめてみよう。
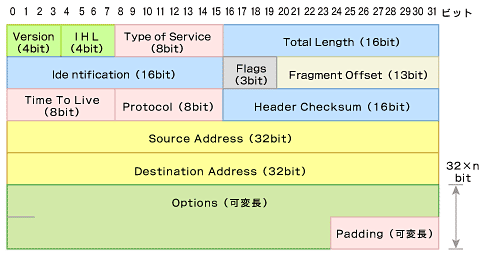

同じIPプロトコルでありながら、図2に示されたIPv6のヘッダは、図1のIPv4ヘッダに比べてかなりシンプルになっている。その大きな理由は、付加的な情報の多くを別個の「拡張ヘッダ」に再配置したことにある。図2に示されているのはIPv6の「基本ヘッダ」と呼ばれる部分であり、必要に応じて、このヘッダの後に「拡張ヘッダを追加する」ことによって、シンプルさと機能性の両立を可能にしている。基本ヘッダ内のフィールドの数が大きく減少したことにより、IPv6パケットの伝送における中継ルータの負荷が軽減されている。
基本ヘッダと拡張ヘッダの分離には、さまざまな効果がある。図1をご覧いただければ分かるが、IPv4のヘッダにはOptionsフィ—ルドがあり、この部分に暗号化をはじめとした、さまざまな付加サービスに関する情報を書き込むようになっている。このため、ヘッダが可変長であり、伝送経路上に存在するルータにとってはハードウェア処理がしにくい。また、IPv4におけるオプションは、ヘッダの一部であるということから、長さが限定されてしまう難点もあった。
これに対し、IPv6ヘッダは40バイトの固定長となり、ルータは処理を高速化することができるようになる。また、各種の拡張ヘッダは数珠つなぎに続けられる構造であり、長さに制限がなくなった。
図2にはNext Headerという8ビットのフィ—ルドが見られる。これは、次にどんなヘッダが続いているのかを表示するフィールドである。基本ヘッダのみの場合は次にTCPあるいはUDPヘッダがくることを示すが、拡張ヘッダが続く場合には、どんな拡張ヘッダが続くのかを示すことになっている。
拡張ヘッダは、その役割ごとに別個に用意されている。このように付加機能をそれぞれ別個のヘッダとして独立させたことにより、将来の機能変更や追加がやりやすくなるというメリットも生まれている(図3)。拡張ヘッダは、「ホップバイホップオプションヘッダ」と呼ばれるもの以外は、中間ルータによって処理される必要のないものである。このようにルータが見なくていい情報を明確化することで、処理の効率化が期待できる。
もう1つ高速化に寄与する要素として指摘できるのは、IPv4に見られるHeader Checksumフィ—ルドがIPv6では消えていることだ。ヘッダチェックサムとは、文字通り、ヘッダ内の情報についての誤り検出符号のことだ。へッダの中にはTTL (Time To Live)*1のように、ルータを通過するごとに変化する値が含まれているため、ヘッダチェックサム値は、各ルータにおいて再計算される。これは、ルータに大きな負荷をかけ、遅延をもたらす原因となっている。以前に比べ、IPよりも下のレイヤのサービスの信頼性は向上している一方、TCP/UDPのレイヤでは、TCP/UDPの情報に加えて、送信先、送信先IPアドレス、プロトコル番号、データ長からなる「擬似ヘッダ」を含めたチェックサムが実行されている。このため、IPv6ではIPレイヤでのヘッダチェックサムを廃止している。
IPv4のTTLフィールドは、IPv6ではHop Limitに改称された。IPv4では仕様上、TTLフィールドには許される残りのルータホップ数か残存時間(秒)のどちらかを指定できることとなっているが、実際にはホップ数しか使われていない。これを踏襲し、さらに明確化するために、ホップ数のみに統一し、名称も変更している。
*1TTL(Time To Live)TTL(Time To Live) IPパケットのネットワークにおける生存時間を示す値。“時間”とは表現されているが、実際にはルータなどの中継装置を通過する際のホップ数が示される。ルータを通過するごとにTTLの値は1ずつ減算され、0になったパケットはルータによって破棄される。TTLが存在する理由の1つは、中継数の限界点を設定することで、IPパケットの転送が無限ループに陥らないようにするためである
伝送品質制御への取り組み
アプリケーションやサービスの種類、提供先といった情報に基づいて、飛行機のファーストクラス、ビジネスクラス、エコノミークラスのように、サービス品質を相対的に差別化するための仕組みは長い間求められてきた。
IPv4では、8ビットのService Typeフィールドによって、優先制御のためのフレームワークを提供してきた。Service Typeフィールドは、TOS(Type of Service)フィールドとPrecedenceフィールドに分けられている。TOSではサービス差別化の物差しとして、コスト、信頼性、スループット、遅延、セキュリティのどれを使うのかを指定し、Precedenceフィールドでは0〜7までの8レベルで、各パケットにどのレベルの優先度を与えるのかを送信元や中間ルータが指定することになっている。IPv6では、Service Typeフィールドに代わって、Traffic Classフィールドが設けられ、同じ機能を果たすことになっている。相対的な優先制御の中身は、ルータの製品や設定によって異なってしまうが、単一の通信事業者のネットワーク内部で利用する場合は一定のメリットを提供するはずだ。
これに加え、IPv6には新たに20ビットのFlow Labelフィールドが設けられ、送信元が中継ルータ(あるいはネットワーク)に対し、自分の送信する特定のトラフィックフローに対する特別な扱いをリクエストできるようになっている。IPv4の世界では、トラフィックフローを認識するために、送信元と送信先のIPアドレスに加え、ポート番号も確かめなければならない。しかし、IPSecで暗号化されたパケットでは、ポート番号のようなIPレイヤより上の情報を見ることができない。このような問題を解決し、フロー単位でRSVP*2に代表されるような資源予約型のQoS技術などを活用できるようにするために用意されたのがFlow Labelである。だが、RFC2460に含まれている説明では、「これは実験的なものであり、インターネットにおけるフローへの対処方法が明確化するとともに変化していく余地がある」とされていて、このフィールドをどう使うかについては、詳しく触れられていない。
RFC2460の追記では、送信元がVoice over IPなどの一連のパケットに単一のランダム値を割り当て、これに対して特定のサービスをリクエストすることが一応想定されている。しかし、中継するルータは、送信元が指定してきたフローラベルに変更を加えることが許されるのかどうかであるとか、このフィールドがさまざまなメカニズムで使われることを想定して、タイプと値の2つに分割すべきなのではないかといった議論が続けられていて、現在のところまだ決着がついていない。
*2RSVP(Resource reSerVation Protocol) IPレベル(ネットワーク層)でのQoSを実現するネットワーク制御プロトコル(RFC2205)。特定のトラフィックフローに対し帯域予約を行うことでQoS通信を実現しているため、資源予約型QoSと表現されることがある(RSVPは帯域予約情報を中継ルータに伝えるためのプロトコルであり、実際のフロー制御はルータの実装による)。トランスポート層のプロトコルと位置付けられているため、IPv4とIPv6のどちらのプロトコルスタックでも動作することが可能
拡張ヘッダにおける付加機能
拡張ヘッダのほとんどは、中継ルータが処理する必要のないものである。唯一の例外は「ホップ・バイ・ホップ・オプションヘッダ」と名付けられたヘッダで、ホップ・バイ・ホップ、つまりパケットがルータを通過するごとに処理されなければならない情報は、ここに指定することになっている。使い道が当初から決められているヘッダではないが、RFC2675に示されたJumbogramオプションがあり、これはサイズの大きなパケットの伝送を補助するために使われる。
ルーティングヘッダは、特定のルーティング経路を指定するために利用される。これにより、プロバイダを選択するなど、特定の用途のためにパフォーマンスを確保することが可能になる。送信元は、このパケットが通過しなければならないルータのアドレスを、ルーティングヘッダ内にリストして伝送経路を示す。
パケットの認証と一貫性の保証に使われる認証ヘッダや、データの暗号化情報を示すESPヘッダも拡張ヘッダとして組み込まれる(詳細は次回に解説)。拡張ヘッダには、さらに「フラグメントヘッダ」と呼ばれるものもあるが、これについては後述する。
ルータによるパケット分割の禁止
IPv6では、データ転送の高速化を側面から支援するための配慮として、ルータによるパケット分割を禁止している。これによってルータの負荷を軽減するとともに、ハードウェア処理を促進している。
IPv4では、ネットワークトラフィックの通り道に存在するルータが、そのインターフェイスに設定されたMTU(Maximum Transmission Unit:最大転送単位)の値に従い、伝送媒体の速度に合わせてパケットを分割してから送信する作業を行っている。インターネットでは、アナログ電話回線でインターネット接続されたユーザーが、ギガビットクラスのインターネット接続を与えられたサーバから大容量データをダウンロードするといったように、データの送信元と送信先のネットワーク接続帯域がまったく異なっていることは日常茶飯事だ。送信元と送信先に広い帯域を与えられていたとしても、送信途中の経路が細いこともある。ルータによるパケット分割は、データが通過する各ネットワークセグメントの帯域に適した伝送を行えるようにするためのメカニズムである。
だが、この手法だと、データがルータを通過するたびにパケット分割を実行し、次のルータは受け取ったパケットを組み立て直したうえで再び分割し直し、また次のルータに送るという作業が繰り返されることもありうる。ルータにとって、こうした作業は大きな負担となり、スループットを落とすとともに、遅延を発生させる原因にもなる。そこでIPv6では、ルータによるパケット分割をさせないことにし、インターネットのさらなる高速化に対応している。パケット分割は、送信元のホストだけに許されるようになった。
IPv6では、最小のMTUが1280バイトと決められている(これ以下のMTU設定は許されない)。しかし送信元ホストでは、この値よりも大きいサイズのパケットを送ることができる。高速な環境であれば、データを多数のパケットに分けるよりも、できるだけ少数のパケットに詰め込んで送ったほうが効率的だからである。
この際に使われるのがPath MTU Discoveryという機能だ。これは、自分が送ろうとするデータが通る経路(path)の太さを知ってから、その太さに合わせてできるだけ大きなサイズを使って送信を行うというものだ。
Path MTU Discoveryでは、まず発信元ホストは、自分の接続されているローカルリンクのMTUを使ってデータ送信を始める。送信先ホストとの間のどこかで、リンクの太さと比較して「このパケットが大きすぎて扱えない」ようなことが起こった場合、この場所に位置しているルータはパケットを捨て、「Packet Too Big(パケットが大きすぎる)」というメッセージを送信元ホストに送り返す(図4)。このメッセージには、自分の扱えるMTU値を含める。発信元ホストは、このメッセージに含まれたMTU値でパケットを再送信する。こうして、発信元ホストは、どのルータからも文句が出ない範囲で最大のMTU値(これが「path MTU」)を利用し、送信を続ける。あるいは、受け取ったPacket Too Bigメッセージ中のMTU値が小さすぎる場合、発信元ホストは送信をやめてもよい。

インターネットでは、その時々でルーティング経路が変わり、これに応じてリンクが太くなったり、細くなったりすることがある。細くなった場合は、Packet Too Bigメッセージによって検知することができる。太くなった場合にこれを検知することを目的として、送信元ホストは定期的に、わざと最適値よりも大きなMTU値での送信を試すことを許される。しかし、これはパケット落ちを誘発するおそれがあるので、あまり頻繁に行うべきではないとされている。
なお、Path MTU Discoveryを規定したRFC1981では、IPv6ノードはこの機能を実装する“べき”であるとしている。つまり、必ず実装しなければならないというわけではない。実装しないノードは、MTUを1280バイトとして送信を行わなければならないとされている。その代わり、高速な環境を生かすことはできない。Path MTU Discoveryは、IPv4の世界でもRFC1191に規定されており、一部のTCP/IPスタックでは使われている。だが、この機能を当初から標準の一部として組み込んでいることの意味は大きい。
アプリケーションが上のようなメカニズムによるMTU値の調整にしたがって、パケットサイズを変えることができない場合には、送信元でパケットを分割し、拡張ヘッダの1つとして用意されたフラグメントヘッダで組み立て方を指示して送り、送信先でこれにしたがって再組み立てするという選択肢が残されている。ただし、可能なかぎりPath MTUによる調整を行うべきとされている。
今回は、IPv4時代の反省も踏まえ、よりシンプルで洗練された構造になったIPv6のヘッダフォーマットに着目しました。次回は、IPv6の特徴の1つである拡張ヘッダの仕組みや動作に踏み込んでいきます。
Copyright © ITmedia, Inc. All Rights Reserved.