NoSQLデータベースを使い始める前に:RDB開発者におくるNoSQLの常識(2)(2/3 ページ)
前回はNoSQLデータベースとRDBMSの設計思想の違いを解説しました。今回は、それを踏まえてNoSQLデータベースでデータベースを設計するときに覚えておきたいポイントを解説します。(編集部)
読み取り時にデータを加工しても間に合わない
RDBMSがデータにアクセスする手順を整理したところで、RDBMSを分散環境で運用したらどうなるか、ということを考えてみましょう。図3はネットワーク上に存在する複数のサーバを1台の「問い合わせ処理役」のサーバと、複数の「データ置き場」役のサーバに分けて、疑似的な分散データベースととした環境をイメージしたものです。ここで問い合わせ処理役のサーバにデータの読み取りを要求すると、問い合わせ処理サーバはネットワーク上に存在する複数のデータ置き場役のサーバにアクセスして、必要なデータを探し集めることになります。
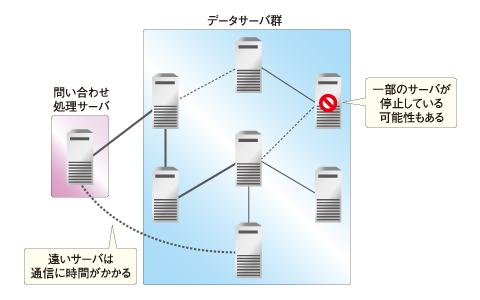
RDBMSのパフォーマンスチューニングでは「低速なディスクストレージへのアクセスを可能な限り減らし、できるだけメモリにキャッシュしたデータを返す」のが定石です。しかし、分散環境ではディスクストレージよりもさらに速度が遅く、安定しない、ネットワーク経由のデータアクセスを余儀なくされてしまいます。
さらに前述したように、RDBMSを使うときはデータを集めてきた後にもまだ仕事が残っています。RDBMSではデータ更新の処理速度を上げるために、保存するデータから重複を排除(正規化)していました。導出項目の計算や複数データの集計など、「あとで計算すれば分かる」データは読み取り後に一括で計算して生成するのです。
取得したデータの量が多ければ多いほど、すべての計算結果がそろうまでの時間は長くなります。また、結果セットに含まれる大量データを集計したり並べ替えるには、それだけ多くの一時領域が必要になります。一時領域として使えるリソースが少なければ、さらに余分な時間がかかります。
動的生成から分散キャッシュへ
ここまで説明したように、分散環境では「ユーザーは問い合わせ言語を使ってデータを返すように要求する。データベースは問い合わせ内容に合わせて加工したデータを戻す」というRDBMSのスタイルは向きません。これは、RDBMSの考え方が間違っていたからではなく、技術の急速な進歩によって物理的な制約条件が大きく変わってしまったことが原因です。
RDBMS登場当初、処理性能向上のために余分なディスク入出力をできるだけ減らすことは今よりもずっと大きな効果がありました。今ほどネットワークも発達しておらず「複数のサーバにデータを配置する」というアイデアは検討する価値もありませんでした(注1)。このような状況では「One fact in one place(1つの事実は、1つの場所に)」というRDBMSの考え方は理にかなったものでした。
注1:もちろん、何がボトルネックになるかはデータベースに対する要件や技術の進歩によって変わります。いまは「大量の読み取りアクセスに対応するため分散環境にデータを配置したとしても、ディスク入出力の速度と比較してネットワーク通信の速度が遅い」状況だといえます。ここでは「できるだけサーバ間の通信量を減らすこと」が処理性能を上げるために有効なアプローチになります。しかし今後通信速度が速くなっていくとしたら、また前提条件も変化します。データ入出力(ディスクとネットワークの両方)がどちらも十分に高速になるとしたら、今度は集めたデータを処理する能力(プロセッサの性能や処理アルゴリズムのよし悪し)が新たなボトルネックになりうるでしょう。なお、大量データを高速に処理する技術としては「Hadoop」などの並列分散フレームワークが現在注目を集めています。
しかし、データの保存場所が単一のサーバからネットワークに分散する複数のサーバへと移りつつある現在、今度はネットワークの速度が新たなボトルネックになったのです。この限界を打ち破るべく登場したのがNoSQLデータベースというわけです。
NoSQLデータベースでは、分散環境で高い処理性能を発揮することを念頭に置いて設計してあるので、その多くはRDBMSのように多機能な(=複雑な)データ検索の機能を備えていません。
Copyright © ITmedia, Inc. All Rights Reserved.