フリーズしないアプリケーションの作り方:特集:.NET開発者のための非同期入門(1/3 ページ)
ユーザーは0.5秒のフリーズでストレスを感じ、3秒のフリーズはバグだと判断する。そうならないための非同期処理パターンとは?

powered by Insider.NET
「エンド・ユーザーは、0.5秒のフリーズでストレスを感じ、3秒のフリーズはバグだと思う」。昔、冗談半分に言ってみた言葉だが、回りの反応を見るに、割とみな思っていることらしい。
特にモバイル端末向けのOSでは、応答性の悪いアプリケーションはOSによって強制終了されたり、マーケットプレイスでの審査に落ちたりする。フリーズしないアプリケーション作りがますます重要になっている。
そこで、本稿では、フリーズしないアプリケーション作りに必要となる「非同期処理」*1について説明していく。
*1 時間のかかるAPIに対して、そもそも非同期版しか提供しないケースが増えてきている。Windows 8の新しいWindows API(WinRT)では、50ミリ秒以上かかるAPIを、すべて非同期なメソッドとして提供するそうだ。
■非同期処理の今までとこれから
ネットワークI/Oのように待ち時間の発生する処理や、重たい処理がしたいときには、非同期処理を行うべきだ。また、「マルチコア時代に備えて非同期が重要」と言われ始めてから久しい。
これはずっと言われ続けてきたことであり、当然、今まででも、できることはできた。ただし、デッド・ロックなどの深刻なバグを出さず、かつ、パフォーマンスのよい、正しい非同期処理は難しく、経験豊富で知識のある開発者にしかできなかった。そのため、妥協的に、フリーズするアプリケーションが許容されてきた。
もちろん、その間、OSレベル、ライブラリ・レベルでは脈々と非同期処理に関する機能が整備されてきている。そして最近では、その成果がアプリケーションに反映されつつある。そろそろ、「難しい」を理由にアプリケーションのフリーズが許容される時代は終わりを迎えようとしているのだ。
.NET Frameworkにおいても、バージョン4で追加されたTaskクラス(System.Threading.Tasks名前空間)の追加(と、それに伴うスレッド・プールの性能改善)によって、非同期処理がだいぶ楽になった。同時に、データ並列を扱うためのParallelクラス(同名前空間)も提供されている。
また、次期バージョンでは、C# 5.0に非同期制御フローを扱うためのasync/await構文*2や、.NET Framework 4.5に非同期データフローを扱うためのTPL Dataflowライブラリ*3が追加される予定である。
*2 現在、CTP(Community Technology Preview: ベータ以前の早期評価版)が公開されている。C#言語だけでなく、コード・エディタやデバッガに手を入れる必要があるので、Visual Studio 2010に対する拡張として提供されている:Visual Studio Async CTP
*3 もともと、Async CTPに含まれていたものだが、現在は単体でもダウンロード可能:TPL Dataflow
以降では、これら、すなわち、以下の3つの非同期処理パターンについて説明を行っていく。
- データ並列
- 非同期制御フロー
- 非同期データフロー/タスク並列
■タスク
その前にまず、Taskクラスの背後にあるインフラ的な仕組みについて説明しておこう。
後述するように、非同期処理にはいくつかのプログラミング・モデルが考えられるが、いずれも共通して、内部的には、細々とした処理を大量に同時実行する仕組みを必要とする。
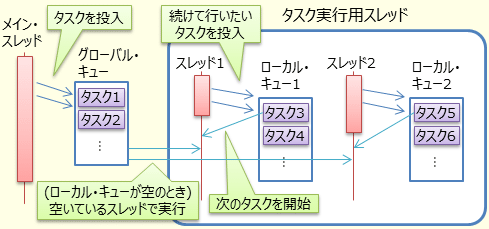
クラス名になっているタスク(task)という言葉はこの細々とした処理を指す。すなわち、Taskクラスは、この手の処理を効率よく同時実行するためのインフラを持っている。大まかにいうと、図 1に示すようなものである。
重要なのは以下の2点である。
- 可能な限り、スレッドを作らない
- 可能な限り、ロック(lock: データ読み書きの競合を避けるため、競合しそうなスレッドの動作を止める)を避ける
スレッドの新規作成やロックは、性能的なコストが大きく、避けるべきものである。
タスク実行用のスレッドは、CPUのコア数にぴったりの数を動かすのが最も効率がよい。それ以上の数のスレッドを作っても、スレッドの切り替え負荷が高まるだけで、CPUの利用効率は上がらない。そこで、Taskクラス内部では、タスクをいったんキューにためておいて、空いたスレッドに割り振ることで効率的にタスクを実行する。
ここで、キューは複数のスレッドから参照されるため、工夫なしでは、タスクの追加/取り出しにロックを必要とする。Taskクラス内部において、タスク実行用のスレッドがそれぞれ別個にローカル・キューを持っているのは、このロックを避けるためである。
■データ並列
データ並列(data parallelism)は、入力されたデータ列の各要素に対して、同じ処理を繰り返し適用していく処理方法である。図 2に示すように、複数のCPUコアで同じ処理を行うことで、計算にかかる時間を削減するために行う。
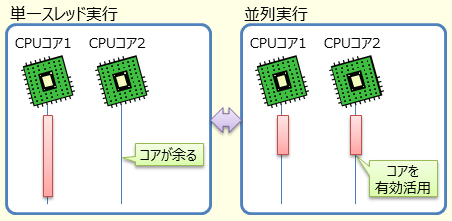
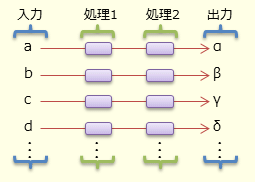
図 3のように、処理対象となるデータ列の各要素が独立していて、互いに干渉し合わない場合、並列化は非常に簡単である。
C#の場合、forステートメントを使ったものならば、リスト 1に示すように、Parallelクラス(System.Threading.Tasks名前空間)のForメソッドに置き換えるだけだ*4。
*4 ただし、並列化には大きなオーバーヘッドがかかるため、処理が簡素で、かつ、要素数が少ない場合に並列化するとかえって遅くなる。多くの場合、数万件程度のデータ量では並列化する意味がない。
// 単一スレッド実行
for (int i = 0; i < 入力.Length; i++)
{
var x = 入力[i];
var y = 処理1(x);
var z = 処理2(y);
出力[i] = z;
}
// 並列実行
Parallel.For(0, 入力.Length, i =>
{
var x = 入力[i];
var y = 処理1(x);
var z = 処理2(y);
出力[i] = z;
});
また、C# 3.0以降のLINQを使う場合、さらに簡単で、リスト 2に示すように、「AsParallel」(=ParallelEnumerableクラス(System.Linq名前空間)で定義された拡張メソッド)を付けるだけである。
// 単一スレッド実行
var 出力1 = 入力.Select(処理1).Select(処理2);
// 並列実行
var 出力2 = 入力.AsParallel().Select(処理1).Select(処理2);
●並列化が難しい場合1: 同期化と整列
もちろん、前述のような幸せなケースはそう多くない。並列化を難しくするいくつかの要因がある。分かりやすいのは同期化と整列が必要な場合である。図 4のような状況を考えてみよう。
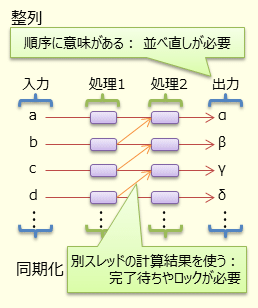
まず、別スレッドの計算結果が必要になるような継続処理がある場合、別スレッド処理の完了待ちや、書き込みが競合を避けるためのロックが必要である。
また、並列処理を行った場合、処理順序の保証ができない。このため、順序の保証が必要な場合には、全ての処理が完了するのを待ったうえで、並べ直す必要がある。
これらは、追加のオーバーヘッドを生むため、並列化による性能向上を阻害する。また、同期化は、デッド・ロックなど、致命的なバグを生みやすい。特に、並列処理に起因するバグは再現性が低く、テストでの発見が漏れる可能性もあり、非常に危険である。
●並列化が難しい場合2: I/Oバウンド
全データがメイン・メモリ上に乗り切らないような巨大データを処理する場合、CPUよりも、ストレージ(=ハードディスクやSSDなどの、不揮発性の記憶装置)の性能がネックになることが多い。
また、巨大データの場合、複数台のコンピュータで分散して並列処理することも考えられるが、この場合はコンピュータ間の通信がネックとなる。
ストレージにしろネットワークにしろ、計算自体ではなく、I/Oの制限によって性能の上限が決まる種類の処理は多い。この上限を、「I/Oに速度が縛られている」という意味で、「I/Oバウンド(I/O bound)」という。
I/Oバウンドな処理の場合、アプリケーションのレベルで性能改善を図るのは極めて困難だ。OSレベル、ミドルウェア・レベルでの対応(HadoopやWindows HPC Serverなど)が必要である。
続いて次のページでは、非同期制御フローを説明する。
Copyright© Digital Advantage Corp. All Rights Reserved.