フリーズしないアプリケーションの作り方:特集:.NET開発者のための非同期入門(2/3 ページ)
ユーザーは0.5秒のフリーズでストレスを感じ、3秒のフリーズはバグだと判断する。そうならないための非同期処理パターンとは?
■非同期制御フロー
非同期処理の中には、制御フロー(control flow)上は通常の同期的なコードと変わらないものも多い。フローチャートやシーケンス図を書くと、図 5に示すように、同期コードと同じ構造になるものだ。
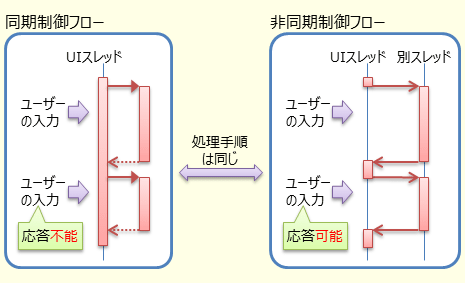
この種類の非同期処理は、スレッド・リソースの無意味な浪費を回避する目的で使う。スレッド浪費がなくなることで、例えば、以下のようなメリットが得られる。
- クライアントUI: 応答性の改善
- 時間のかかる処理でも、UIスレッド(=エンド・ユーザーからの入力を受け付けるためのスレッド)を止めず、フリーズを回避する
- ビジネス・ロジック: 並列データ取得
- 複数のデータ・ソースから、データを並列に取得することで待ち時間を減らす
- サーバ: スケーラビリティ向上
- 1リクエストにつき1スレッド使う必要性をなくし、より多くのリクエストに応答する
理想を言うと、制御フローが同じなのだから、図 6に示すように、同期処理と非同期処理で同じ構造のコードを書きたい。

図 6の非同期処理の例は、C#の次期バージョンで入る予定の非同期メソッドおよび“await”キーワードを使っている。非同期メソッドを使えば、同期の場合とまったく同じ制御フロー構造のコードで非同期処理を書ける。
ここでは、先に現状のC#、すなわち、C# 4.0の場合について、非同期制御フローの書き方を説明していこう。その後、次期バージョンの非同期メソッドについても簡単に触れる。
●サンプル
例えば以下のようなものを考えてみよう。
- Webで特定のURLにアクセスすることで、100件ずつデータを取得できる
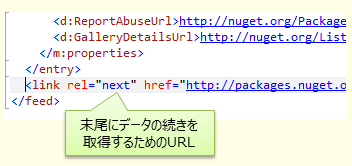
- データの末尾に、まだデータが残っているか、残っているならデータの続きを取得するためのURLが入っている
具体的には、ODataがこの形式でデータを返す。ここでは、NuGetギャラリで公開されているパッケージの一覧を取得してみよう。図 7に、パッケージ一覧をブラウザでの取得結果の例を示す。これはAtomPub形式のXMLデータになっていて、図 8に示すように、末尾に続きを取得するためのURLが入っている。
●同期制御フロー
この処理を同期的なコードで書くと、リスト 3のようになる。
public void LoadTitles()
{
var wc = new WebClient();
string url = startUrl;
while (!string.IsNullOrEmpty(url))
{
var body = wc.DownloadString(url); // Webからデータ取得
var titles = ExtractTitles(body); // データの構造解析
foreach (var title in titles)
{
_titles.Add(title);
}
url = GetNextUrl(body);
}
}
「_titles」は表示先のリストボックスにひも付けるコレクションで、「ExtractTitles」と「GetNextUrl」は別途定義されたメソッドである。ここで、Webからのデータ取得の部分(=「DownloadString」メソッド)はかなりの時間を要する。また、それほどではないにしても、データの構造解析(=「ExtractTitles」メソッド)もそれなりに時間がかかる。
当然、このまま実行すると、アプリケーションがフリーズしてしまう(データ量がそれなりに多いため、数分はフリーズする)。このため、DownloadStringメソッドやExtractTitlesメソッドを非同期に実行する必要がある。
●ループを含まない非同期制御フロー
非同期制御フローも、ループを含まない場合はそれほど難しくない。例えば上記の例でいうと、データ取得が1ページだけでいいならwhileループは不要だ。
この場合、Taskクラスが使えるならコードの記述はまだ幾分か楽で、リスト 4のようになる。ただし、WebClientクラスに対して、リスト 5のような拡張メソッドを定義してある。
public void Load1PageAsync()
{
var wc = new WebClient();
wc.DownloadStringTaskAsync(startUrl) // 非同期にDownloadString
.ContinueWith(t => ExtractTitles(t.Result)) // 非同期にExtractTitles
.ContinueWith(t =>
{
foreach (var title in t.Result.Distinct())
{
_titles.Add(title);
}
}, TaskScheduler.FromCurrentSynchronizationContext());
}
public static Task<string> DownloadStringTaskAsync(this WebClient c, string uri)
{
var tcs = new TaskCompletionSource<string>();
DownloadStringCompletedEventHandler handler = null;
handler = (sender, e) =>
{
if (e.Cancelled) tcs.TrySetCanceled();
else if (e.Error != null) tcs.TrySetException(e.Error);
else tcs.TrySetResult(e.Result);
c.DownloadStringCompleted -= handler;
};
c.DownloadStringCompleted += handler;
c.DownloadStringAsync(new Uri(uri));
return tcs.Task;
}
元の同期版のコードとずいぶん変わってしまったが、手順どおりに上から処理が並んでいるだけ、Taskクラス登場以前と比べればまだ分かりやすくなっている。
●ループを含む非同期制御フロー(C# 4.0)
問題は、ループや条件分岐を含む制御フローの場合だ。前節のような、ContinueWithメソッドをつないでいく書き方ができなくなる。そこで登場するのが、次期バージョンのC#で導入される非同期メソッドである。
しかしその前に、現状のC# 4.0での回避策的な方法を紹介しておこう。リスト 6に示すように、イテレータ構文(yield return)を使って非同期制御フローを書く手法がある。
public Task LoadTitlesAsyncPattern()
{
return StartAsyncMethod(LoadTitlesIterator());
}
public IEnumerator<Task> LoadTitlesIterator()
{
var wc = new WebClient();
string url = startUrl;
while (!string.IsNullOrEmpty(url))
{
var tBody = wc.DownloadStringTaskAsync(url);
if (!tBody.IsCompleted)
yield return tBody;
var body = tBody.Result;
var tTitles = Task.Factory.StartNew(() => ExtractTitles(body));
if (!tTitles.IsCompleted)
yield return tTitles;
var titles = tTitles.Result;
……後略…… // 残りは同期処理と同じ
}
}
private static Task StartAsyncMethod(IEnumerator<Task> e)
{
Action a = null;
var tcs = new TaskCompletionSource<object>();
var scheduler = TaskScheduler.FromCurrentSynchronizationContext();
a = () =>
{
if (e.MoveNext())
{
var t = e.Current;
t.ContinueWith(_ => a(), scheduler);
}
else tcs.TrySetResult(null);
};
a();
return tcs.Task;
}
同期版(リスト 3)のLoadTitlesメソッドと、非同期版(リスト 6)のLoadTitlesIteratorメソッドの違いは、定型的な置き換えのみで、図 9に示すとおりである。

●ループを含む非同期制御フロー(C#次期バージョン)
図 9のような置き換えは完全に機械的に行えるもので、それをC#/VBコンパイラにやらせてしまおうというのが、次期バージョンで導入される非同期メソッドである。リスト 7に示すように、メソッドにasync修飾子、非同期処理の手前にawaitキーワードを付けるだけで、非同期制御フローが書けるようになる。
public async Task LoadTitlesAsync()
{
var wc = new WebClient();
string url = startUrl;
while (!string.IsNullOrEmpty(url))
{
var body = await wc.DownloadStringTaskAsync(url);
var titles = await Task.Factory.StartNew(() => ExtractTitles(body));
……後略…… // 残りは同期処理と同じ
}
}
これで、当初「理想を言うと」と説明したような、「同期と非同期で、同じ制御フローを同じようなコードで書く」を実現できるようになる。
最後に次のページで、非同期データフローを説明する。
Copyright© Digital Advantage Corp. All Rights Reserved.