Hadoopによるテキストマイニングの精度を上げる2つのアルゴリズム:テキストマイニングで始める実践Hadoop活用(最終回)(1/3 ページ)
Hadoopとは何かを解説し、実際にHadoopを使って大規模データを対象にしたテキストマイニングを行います。テキストマイニングを行うサンプルプログラムの作成を通じて、Hadoopの使い方や、どのように活用できるのかを解説します
Passive-Aggressiveとロジスティック回帰で精度向上
前回の「実践! 「MapReduceでテキストマイニング」徹底解説」では、「青空文庫」の作品から学習を行い、テキストデータから著者の寿命を推定するMapReduceプログラムを作成しました。
今回は、前回のプログラムを少し変更するだけで、精度が上がる「Passive-Aggressive」というアルゴリズムを実装します。また、テキスト分類のアルゴリズムとして、「ロジスティック回帰」を実装していきます。ロジスティック回帰という名前が付いていますが、今までのように寿命の値を直接推定する回帰問題ではなく、寿命を10〜14歳、15〜19歳、20〜24歳などにカテゴリに分けて、どのカテゴリに属するか推定するテキスト分類問題として扱います。
今回のサンプルプログラムを使って、テキストから作者の寿命を推定するWebページを作ってみました(筆者個人のページとして運用しています)。

今回の記事のサンプルコードは、こちらからダウンロードできます。
なお、★マークが付いた数式が実装に使用する数式です。それ以外は、「なぜ★マークの数式を実装すればいいのか」という解説です。途中の解説がよく分からなかった場合は、★の数式さえ実装できればいいと思って、読み飛ばしても構いません。MapReduceのプログラムを見て、★マークの数式をどのように実装しているか理解できればいいと思います。
寿命がどれぐらい予測できるか検証
本題に入る前に、今回の記事で紹介したアルゴリズムを使ってどれぐらい寿命が推定できるのか検証してみます。
平均絶対誤差
寿命がどれぐらい推定できているか、検証してみました。
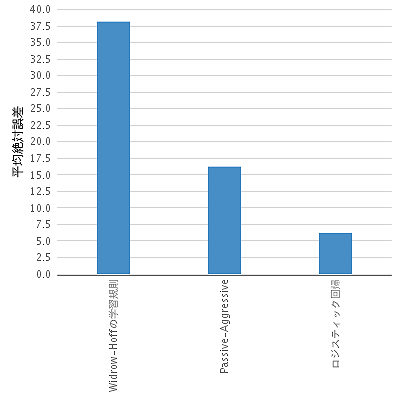
グラフの縦軸は、寿命の推定結果と、正しい寿命との差の絶対値の平均を表しています(これを「平均絶対誤差」といいます)。「データ(青空文庫の作品)を5分割して、4つで学習させて、1つでテストを行う」というのを5回繰り返しました。
ロジスティック回帰では、正しい寿命と予測の差の平均が6.2歳なので、それなりに推定できていると思います。
「存れ」「獣」がマイナス、「福井」「ユンケル」がプラス
では、どのような言葉が寿命に影響しているのでしょうか。Passive-Aggressiveでの推定で寿命に影響している単語を調べてみました。まず、マイナスに影響している単語です。
| 単語 | 重み |
|---|---|
| ひとつ | -2.3490952926530935 |
| 獄中 | -2.215392573800847 |
| 吟 | -2.0407175740818566 |
| トイヒマシタ | -1.8762846261693076 |
| 量 | -1.8652872750753478 |
| 読み | -1.65054168228299 |
| ソコデ | -1.3017743391732801 |
| 大正 | -1.2847275072432964 |
| 善悪 | -1.1744053479185608 |
| 獣 | -1.143285711705295 |
| 諦めよ | -1.1169379081509474 |
| 在れ | -1.1160287032541225 |
| ソシテ | -1.0602089805162926 |
| トイツテ | -1.0203184756096302 |
| ヴィヨン | -1.0108418211159045 |
| ケレド | -1.0032180137925168 |
「獄中」「大正」が寿命に影響しているのは納得できます。「諦めよ」「存れ」「善悪」「獣」辺りが入っているのも面白いです。
次に、プラスに影響している単語です。
| 単語 | 重み |
|---|---|
| 売る | 10.810189741837185 |
| 怪 | 3.9862610275203356 |
| 材木 | 2.528997307015219 |
| 市政 | 2.158867763729628 |
| 金 | 1.6600355729272516 |
| 所感 | 1.460162266579702 |
| mammy | 1.4013235923008573 |
| 福井 | 1.3899969923102247 |
| 継母 | 1.3737683861670225 |
| 友人 | 1.353957403718172 |
| 巻 | 1.3367896033700861 |
| 合わせ | 1.262231509457941 |
| 猟官 | 1.2258982703131782 |
| 持 | 1.1203198883182555 |
| 此処 | 1.0965084910063474 |
| 重み | 1.094712752386234 |
| 直接 | 1.072193807049893 |
| 標準 | 1.049241580064576 |
| ユンケル | 1.0356141596661617 |
| 平生 | 1.0116518017405913 |
「売る」「材木」「金」「市政」辺り、やはり寿命を伸ばすにはお金が大きく関係しているようです。「mammy」「継母」は女性の方が寿命が長いからでしょうか。「福井」は長寿が多い県だというのが影響しているのかもしれません(参考)。
また、手軽に寿命を伸ばすには「ユンケル」がいいようです。
Gmailの優先トレイでも使われる「Passive-Aggressive」
では、本題に戻り、Passive-Aggressiveについて説明していきます。Passive-Aggressiveは、Gmailの優先トレイでも使われているアルゴリズムで、実装が比較的容易です。カテゴリに分類するのに使われることが多いですが、数値を推定する回帰にも使えます。
例えば、Gmailの優先トレイでは、Passive-Aggressiveでメールの重要度のスコアを推定しています。そして、ある一定以上のスコアのメールを優先トレイに振り分けるということを行っています。今回は、テキストの著者の寿命を、Passive-Aggressiveを使って推定してみましょう。
Passive-Aggressiveの損失関数
前回は、寿命の予測値と正しい寿命の誤差の2乗を「損失関数」としていました。
Passive-Aggressiveでは、以下のような損失関数を考えます。
「寿命の予測値と正しい寿命の誤差の絶対値が一定の“しきい値”
以下だったら、損失はゼロ」と考えます。そうでなければ、寿命の予測値と正しい寿命の誤差の絶対値にしきい値
を引いたものを損失とします(前回は誤差の2乗でした)。
正しい寿命を「56歳」というようにピンポイントで決めずに、「55〜57歳」というようにある程度のマージンを持たせて、それと寿命の予測値の誤差を考えるというイメージです。「Passive-Aggressiveでは、予測値が55〜57歳の間だった場合に、損失がゼロになる」という点がとても重要になります。
次ページでは、 Passive-Aggressiveの“重み”の更新について解説し、Passive-AggressiveのMapReduceプログラムを作成します。
Copyright © ITmedia, Inc. All Rights Reserved.