試すのが難しい―機械学習の常識はMahoutで変わる:ビッグデータ処理の常識をJavaで身につける(4)(2/3 ページ)
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載
Mahoutで「クラスタリング」に挑戦してみよう
Mahoutを利用して機械学習を行うには、大まかには下図のステップを踏むことになります。Mahoutはオレンジ色のステップで登場します(黄色のステップでも少し使います)。
「クラスタリング」とは
本稿では機械学習のうち、「クラスタリング」(クラスタ分析)を題材にします。「クラスタリング」とは、ひと言でいうと、データを「似たもの同士」のグループに分けることです。
例えば、下図は2つの属性(価格と販売数とか、身長と体重とか)を持つデータを点で表した散布図ですが、近い点の集まりを赤丸で囲っています。この赤丸がクラスタで、囲む行為がクラスタリングです。
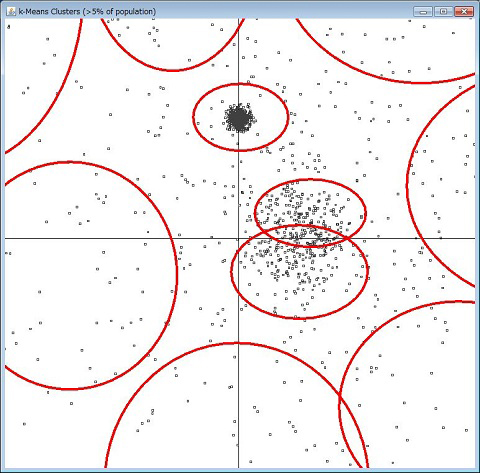
機械学習で扱うデータは普通多くの属性を持つので二次元の図には表せませんが、同じように属性を「次元」と考えると、1件のデータは多次元空間における点になります。その点同士の距離を計算し、近い同士を同じクラスタに分類します。
何をもって「近い」とするかは、データの表し方と、距離の計算方法によって決まります。以下で述べるテキストデータのクラスタリングにおいては、各テキストに登場する語を属性とし、その登場頻度を属性値としてデータを表します。データ同士の距離はコサイン距離で計算します。
【1】計画を立てる
まず目的をはっきりし、そこから計画を立てるのが肝心です。得たい結果、結果を評価する基準と方法、どのようなデータにどのアルゴリズムを適用すればよさそうか、そのデータはどこからどのように入手するか、といったことを決定・計画します。
ここでは、「店名と電話番号しか分からない取引先の業種を調べたい」という目的に対し、以下のように考えたとします。
- 店名と電話番号でインターネットの情報を集め
- 業種ごとにクラスタリングできないか
いささか楽観的過ぎますが、先に進みましょう。
【2】データ収集
今回は、飲食店に限定して検討することにします。簡単なクローリング・プログラムを作って飲食店の情報サイトからデータを集めました(実際は、手ごろなデータがあるとは限りませんし、データ所有者の利用規約に反しないか慎重に検討する必要があるでしょう)。
【3】ゴミ掃除
集めたデータから、HTMLタグ、ヘッダやフッタ、広告など業種の判断には不要な部分を取り除きます。店名、紹介文、メニューからなる、以下のようなテキストデータができたとしましょう。

【4】ベクタ化
テキストをベクタ(ベクトル)に変換します。ベクタには分野によっていろいろな意味がありますが、ここでは単純に、レコードの属性を数値に変換したものと思ってください。
例えば、「(1, 2, 3) 」「(0.5, 0.1, 1.2)」は3つの属性を持つベクタです。本稿の例では前述のとおり、1つのテキストファイルを1つのベクタとし、登場する語の登場頻度を属性値とします。
ここでMahoutのコマンドを2つ使います。まずは、「seqdirectory」コマンドによってテキストファイルをHadoopの「SequenceFile」に変換します。
$MAHOUT_HOME/bin/mahout seqdirectory \ --input data/text \ --output data/seq \ -c UTF-8
次に、「seq2sparse」コマンドでSequenceFileからベクタに変換します。属性とする語の選択や登場頻度の計算そのものは「Apache Lucene」のライブラリを使っています。形態素解析や同義語の処理などはLuceneの仕組みでコントロールできます(詳しくはLuceneのドキュメントを見てください)。
なお、日本語をうまく処理するには日本語に対応する「Analyzer」を作る必要があります。
$MAHOUT_HOME/bin/mahout seq2sparse \
--input data/seq \
--output data/vector \
--analyzer {作成したAnalyzer} \
--minSupport 10 \ ……レコードごとの最少登場回数
--minDF 20 \ ……最少登場文書数
--maxDFPercent 40 \ ……登場する文書の割合がこれを超えたら不採用
--maxNGramSize 3 \ ……熟語の可能性を検討する最大語数
--minLLR 300 \ ……熟語として採用するための同時発生確率の最少値
--sequentialAccessVector \ ……逐次アクセス用のファイル形式
--namedVector ……各ベクタに名前を付ける
生成されたベクタ(data/vector/tfidf-vectors/part-* ファイル)はHadoopのSequenceFileで、「hadoop fs -text」コマンドで見ると、下図のようになっています。
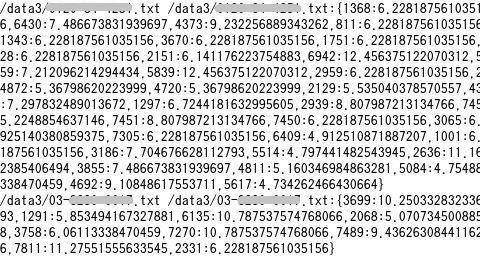
各行が1ファイル(1件の店)を表し、1行目のファイルにはID1368の語が6.2の頻度で登場し、ID7394の語も6.2の頻度で登場しているというわけです。
次ページでは、いよいよクラスタリングに取りかかります。
Copyright © ITmedia, Inc. All Rights Reserved.