Hadoopの現実解「バッチ処理」の常識をAsakusaで体得:ビッグデータ処理の常識をJavaで身につける(7)(1/4 ページ)
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載
“ビッグデータ”時代の「バッチ処理」
アプリケーション開発というと、システム利用者に一番近い画面系の開発が花形ですね。一方「バッチ処理」というと、何となく地味な感じがしますが、「バッチ処理」は縁の下の力持ち、これがないと、大概のシステムは稼働できません。
絶対に必要だけど、影の薄い「バッチ処理」でしたが、“ビッグデータ”への注目度が高まり、大量データを短時間に処理する「並列分散処理バッチ」が活躍する場面も増えてきました。
本稿では、並列分散で「バッチ処理」を行う方法について、「Asakusa Framework」(以下、「AsakusaFW」)を使って解説していきます。
いまさらおさらい、「バッチ処理」とは
いままで携わった分野によって「バッチ処理」のイメージはずいぶん違うかもしれません。オープン系の技術者であれば、Windowsのバッチファイルや、UNIX系のシェルスクリプトで記述されたシンプルなバッチ処理を連想するかもしれませんし、メインフレームに携わっていた技術者であれば、COBOL言語で書かれた比較的シンプルなプログラム群を複雑なジョブフローやジョブネットで構成する壮大なバッチ処理を連想することでしょう。
簡単にいうと、「対話処理」「オンライン処理」「リアルタイム処理」の対義語が「バッチ処理」です。コンピュータに何らかの処理をお願いして、すぐに処理結果が返ってくるものは「対話処理」に向いていますし、処理結果が返ってくるまで時間がかかるものは「バッチ処理」に向いています。
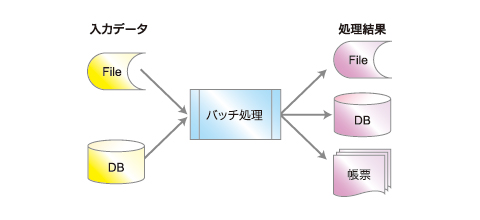
規模や複雑度の大小はあるにせよ、基本的に、比較的大量な入力データを集計などの処理をして処理結果を出力することを「バッチ処理」といいます。
Javaとバッチ処理
Javaが出始めたころは、バッチ処理をJava言語で開発することは、まずありませんでした。JVM上で動作するJavaと最終的にマシン語にコンパイルされて動作するCOBOLなどの高級言語では、「ウサギとカメ」ほどの性能差があったからです。
しかし近年では、ハードウェアの高速化に伴いJavaで「バッチ処理」を開発するといった事例も増えてきました。多少処理時間が遅くても、開発や保守を考えたときに「オンライン処理」「バッチ処理」で異なる言語スキルを持った要員を抱えるよりも、同じ言語で統一するメリットが大きいといったこともJava言語での「バッチ処理」開発が増えてきた要因です。
バッチ処理の使いどころ
「バッチ処理」によっては、コンピュータに高い負荷が掛かったり、DBを長時間ロックしたりしないとできない処理もあるので、システムの利用者が少ない夜間に稼働させることが多いです。
例えば、締め処理や期限切れデータ削除、DBバックアップなどの処理であれば、年次/月次/日次で夜間に自動実行します。また、DBリカバリや臨時のデータメンテナンスなどの異例処理であれば、手動で起動を掛ける場合もあります。
システムを再構築する場合は、必ず、旧システムから新システムへのデータ移行が発生しますが、システムの切り替え時間を可能な限り短縮するため、あらかじめジョブ管理ツールに登録した前後関係で、データ移行用の「バッチ処理」を順次実行するなどといった使われかたもします。
並列分散フレームワークである「Apache Hadoop」は、当初、検索エンジンのインデキシングや大量のアクセスログを集計、分析するために開発されましたが、ビッグデータを処理するツールとしてさまざまなシーンで利用されています。
実は昔からあったバッチ処理の高速化技法
Apache Hadoopに代表される「並列分散処理」を用いた高速化技法ですが、実はこの「並列」でバッチ処理を実行しての時間を短縮するという技術は古くから使われている技法です。
比較的、規模が大きいメインフレーム系の基幹システムを担当している技術者であれば、「ジョブの多重化」といえば、ピンとくると思います。「大量な件数のデータに対して一律の処理するのであれば、データを分割して同時に実行すれば速くなる」という考え方です。

ただし、1台のコンピュータで並列処理を行う場合、多重度を上げるにしても限界があり、高性能なメインフレームでも数十多重で処理速度が頭打ちになります。
この「並列処理」を複数のコンピュータに分散して処理させることで、高速処理することを「並列分散処理」と呼びます。Apache Hadoopは、数千台規模での「並列分散処理」を可能にしたフレームワークです。
バッチ処理を開発するためのJavaフレームワーク4選
「バッチ処理」といっても、シーンによって要件がさまざまなので、開発言語やフレームワークを適材適所で使い分けるのがよいです。「バッチ処理」に限った話ではありませんが、フレームワークを使った開発は、開発生産性の向上や、開発するアプリケーションの品質確保に大きく寄与するため、フレームワークの特性や向き不向きな分野を理解したうえで、慎重に選定した方がいいでしょう。
ここでは、Java言語でバッチ処理を開発するための主なフレームワークを4つ紹介します。
- AsakusaFW
- Javaで記述したAsakusa DSL(後述)によりHadoopのMapReduceを生成する機能
- 「バッチ処理」の開発に必要な部品の提供
- 基幹システムとHDFS間のデータ連携機能
- 並列分散環境でもテスト可能なテストドライバ機能
- Spring Batch
- マルチスレッド・マルチプロセスでの並列処理
- バッチプロセス管理
- トランザクション管理
- TERASOLUNA Batch Framework for Java
- Spring Frameworkの上で稼働するバッチアプリケーションに必要な機能を提供
- オンラインシステムの開発者が学習しやすいアーキテクチャ
- Java Batch System
- NQS(Network Queuing System):CPUやメモリ領域の制限や実行形態により最適なキューを選択して、バッチジョブをバッチシステムにキューイングする機能
- PBS(Portable Batch System):各ユーザーにCPUやメモリ領域を適切に割り振り、バッチジョブの管理を効率的に行うための分散型リソース管理システム
Javaのバッチ処理用フレームワークについては、以下も参照してください。
- バッチ処理はJavaでバッチリ?その現状とこれから
安藤幸央のランダウン(37)
基幹システムで多く見られるバッチ処理はJavaでどこまで適用できるのか。Spring Batchを筆頭に数々の製品やオープンソースも紹介しよう - Javaバッチ処理は本当に業務で“使える”の?
オープンソースフレームワークを使ってバッチ処理の開発手法やノウハウを学んでいく本連載。バッチ処理を知っている人も知らない人も、業務システムに欠かせないバッチ処理について理解を深めましょう
本稿では、この中からAsakusaFWに焦点を当てます。
AsakusaFWの概要と利点
AsakusaFWとは、ノーチラス・テクノロジーズが開発したHadoop上で大規模な基幹バッチ処理を行うためのフレームワークです。「基幹バッチ処理」とうたわれていますが、情報系などほかの分野のシステムでもデータサイズが大きい(数百Mbytes〜数百Gbytes)または、扱うデータレコードが大量(数千万件〜数億件)である「バッチ処理」であれば、AsakusaFWを適用して効果を得ることができます。
日本で開発されたオープンソースのフレームワークなのでドキュメントやコミュニティも日本語で、しかも無料で利用できるというのはうれしいところです。
基幹システムの並列分散バッチをMapReduceで開発するのも不可能ではないでしょう。ただ「業務仕様元にMapとReduceの組み合せでどう実装する」のか、しかも「Map関数とReduce関数のパラメタは、KeyとValueだけ」だとか、初めてMapReduceで業務バッチを開発しようとすると戸惑う人が多いことでしょう。
【利点1】従来のバッチ設計の考え方で設計できる
この点、AsakusaFWには、「バッチ処理」を開発するためのフロー制御、データ操作、結合、集計などの部品(AsakusaFWでは、「演算子」と呼びます)がそろっているので、汎用機でバッチ開発をしたことがある技術者であれば、比較的容易にAsakusaFWでの設計の仕方を理解できるのではないかと思います。
【利点2】MapReduceを知らなくても実装できる
AsakusaFWで実装していくに当たっても、MapReduceを意識する必要がなく、比較的少ないコーディング量で分散バッチを実装できます。具体的には、JavaのDSLでデータフローと処理の内容を実装すれば、DSLコンパイラがMapReduceに変換してくれます。
次ページでは、AsakusaFWの主な機能やAsakusaFWを使った設計と実装の順序、AsakusaFWを使うための環境構築の仕方を紹介します。
Copyright © ITmedia, Inc. All Rights Reserved.