Hadoopの現実解「バッチ処理」の常識をAsakusaで体得:ビッグデータ処理の常識をJavaで身につける(7)(2/4 ページ)
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載
AsakusaFWの6つの主な機能
AsakusaFWには、バッチ処理をHadoopクラスタで稼働させるためのさまざまな機能が用意されています。これらの機能を簡単に紹介します。
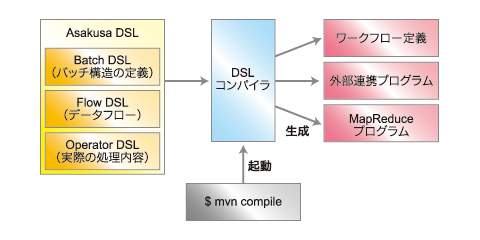
【1】DSLコンパイラ
AsakusaFWの実装は、Asakusa DSL(Domain Specific Language)をJava言語で記述していきます。DSLには、下記の3種類があります。
- Batch DSL
ジョブの実行順序(実行の前後関係)を定義するDSL - Flow DSL
JobFlowとFlowPartの2階層でデータフローが定義できるDSL - Operator DSL
実際の処理内容を記述するDSL
これらのDSLをコンパイルしてMapReduceのソースコードやバッチの実行に必要なワークフロー定義、外部連携プログラムを生成してくれるのが、DSLコンパイラです。DSLコンパイラには、「バッチ処理」がより高速に動作するように最適化する機能もあります。
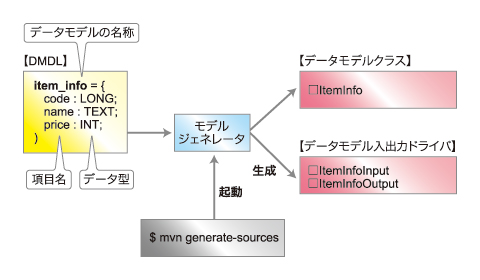
【2】モデルジェネレータ
DDLやAsakusaFW独自のデータモデル定義言語であるDSLをデータモデルクラスに変換する機能です。
基幹システム側RDB(MySQL)のDDL(CREATE TABLE文やCREATE VIEW文)からデータモデルクラスや入出力ドライバを生成してくれます。

また、DMDL(AsakusaFW独自のデータモデル記述言語)で記述したデータモデルからデータモデルのクラスや入出力ドライバを生成してくれます。
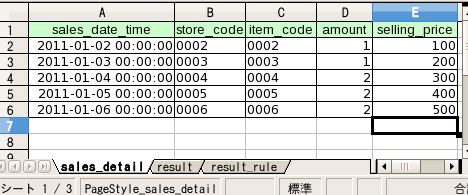
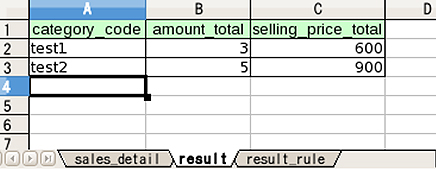
【3】テストドライバー
Excelシートにテストデータ&テスト結果の想定値&検証ルールを定義しておけば、テスト実行したときに自動でテスト結果の検証をしてくれる機能です。データモデルからテンプレートのシートが自動生成されるので内容を埋めるだけで使えます。

【4】ThunderGate
MySQLとHadoop間でデータをやりとりする機能です。ロングトランザクションのサポートやファイルキャッシュ機能といったHDFSへは、前回インポートからの差分のみを転送する仕組みによってデータ連携を高速化します。
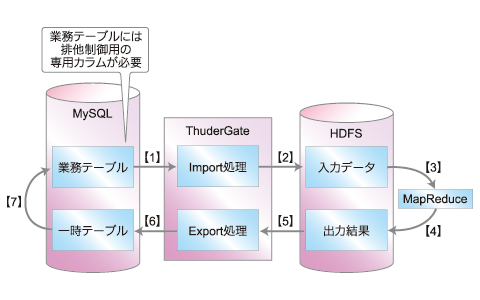
- 業務テーブルより処理対象レコードのデータを取得(このとき、抽出したレコードをロック)
- HDFSに業務テーブルから取得したデータを配置
- HDFSの入力データを使用してバッチ処理
- バッチ処理の出力結果ファイルをHDFSに出力
- HDFSの出力結果ファイルを取得
- 一時テーブルへ一括ロード
- 一時テーブルのデータを基に重複チェックなどを行いながら業務テーブルを更新、更新が完了したレコードのロックを解除
【5】WindGate
WindGateは、MySQLに限らず、任意の外部システムとのデータ連携が可能です。JDBCドライバを使用してアクセス可能なRDBとの連携や、CSVファイルの入出力をサポートしています。さらに外部システムとの連携用プラグインを開発し組み込むことで任意の外部システムとの連携が可能になります。
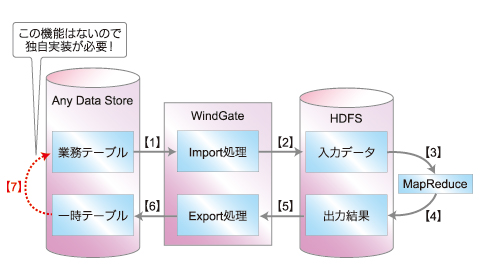
- 業務テーブルより処理対象レコードのデータを取得(このとき、ロック制御は行わない)
- HDFSに業務テーブルから取得したデータを配置
- HDFSの入力データを使用してバッチ処理
- バッチ処理の出力結果ファイルをHDFSに出力
- HDFSの出力結果ファイルを取得
- 一時テーブルへ一括INSTERT
- 業務テーブルへの戻し機能は、WindGateにはないので、独自に実装が必要となる
ただし、ThunderGateのようなトランザクションはサポートしていません。従って、業務テーブルに排他制御用の専用カラムは必要ないので、既存システムのDBやアプリケーションを変更する必要がありません。
また、ThunderGateのような一時テーブルから業務テーブルへデータを書き戻す機能はないため、独自実装する必要があります。
【6】YAESS(Yet Another experimental Shell Script)
YAESSはAsakusaFWで開発したバッチを実行するためのツールです。TenjinやJP1などのジョブ管理ツールからYAESSを経由してバッチを実行することもできます。実行中のバッチの制御やバッチの進捗状況のモニタリングもできます。
AsakusaFWを使った設計と実装
設計の順序
繰り返しますが、AsakusaFWで作成するアプリケーションは、「Batch DSL」「Flow DSL」「Operator DSL」という3種類のDSLを階層的に組み合わせて構成します。
「Batch DSL」はJobの呼び出し順序を定義します。「Flow DSL」は「演算子」を組み合わせてデータフローの構造を記述するDSLです。「Operator DSL」は「演算子」と呼ばれるデータフロー処理の最小単位を記述します。
データフローが複雑になる場合は、「Flow DSL」をJobFlowとFlowPartといった形で階層的に定義することもできますし、シンプルなデータフローであれば、FlowPartは省略して、JobFlowから直接Operatorを呼び出すこともできます。

AsakusaFWの設計手順は、上流から下流へ、すなわち以下の順番で進めていきます。
- バッチフローの設計
- ジョブフローの設計
- フローパートの設計(データフローが複雑になる場合)
- オペレータの設計
実装の順序
AsakusaFWの実装手順は、設計とは逆方向つまり、下流から上流へ進めていきます。

下流から進める理由を簡単にいうと、下流で作成したクラスを上流で使用するからです。
例えば、DDLやDMDLで記述したデータモデルをモデルジェネレータでデータモデルクラスに変換します。Operatorの入出力の実装には、このデータモデルクラスが必要です。通常のアプリEclipseで開発する場合は、存在しないクラスやメソッドの呼び出しは、エラー表示されてしまうので、本当にコンパイルエラーなのか、部品となるクラスがまだ実装されていないだけなのか分からなくなるので、下流の部品から実装します。

AsakusaFWを使うための開発環境の準備
実装の前に、開発環境の準備とAsakusaFWで開発する場合のプロジェクトのディレクトリ構成について触れておきます。
開発環境は、Asakusa Framework Documentationの「開発環境の準備」を参照して作成してください。筆者はまだ試せていないのですが、開発環境を手軽に構築できる「Jinrikisha(人力車)」というインストーラパッケージも提供されています。

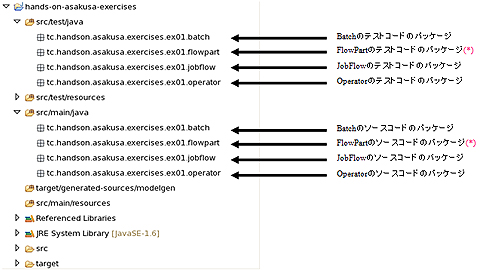
AsakusaFWで開発する場合のパッケージ構成(*データフローがシンプルな場合は、FlowPartのパッケージは作成せず、JobFlowから直接OperatorFactoryのメソッドを呼び出してもOK)
次ページでは、AsakusaFWでの実装イメージをつかむために簡単なバッチを実装してみましょう。
Copyright © ITmedia, Inc. All Rights Reserved.