共有メモリとファイルシステム――その1:知ってトクするシステムコール(6)(2/2 ページ)
今回は、mmap(2)で共有メモリを実装すると処理能力の向上が見込めること、そしてその実装方法にはいくつもの選択肢があることを紹介し、次回以降の比較につなげていく。(編集部)
共有メモリ mmap(2)+メモリファイル(tmpfs)
メモリファイルシステムを作成する方法としては、mdconfig(8)/mdmfs(5)以外にも、tmpfs(5)が存在する。tmpfs(5)は、mdconfig(5)のようにいったんnewfs(8)でファイルシステムを構築する必要がなく、ダイレクトにファイルシステムを提供する。処理するレイヤの関係から、mdconfig(5)を利用して用意したメモリファイルシステムよりも高速に動作するといわれている。コードは次のようになる。
# mkdir /tmp3 # chmod 1777 /tmp3 # mount -t tmpfs tmpfs /tmp3
% dd if=/dev/zero of=/tmp3/shm bs=4096 count=1
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
int
main(void)
{
int fd, i, rp=1000000000;
char *s;
fd = open("/tmp3/shm", O_RDWR);
s = mmap(0, 4096, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
*s = '0';
for (i = 0; i < rp; i++) {
while ('1' == *s)
;
*(s+1) = 'a';
*s = '1';
}
}
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
int
main(void)
{
int fd, i, rp=1000000000;
char *s;
fd = open("/tmp3/shm", O_RDWR);
s = mmap(0, 4096, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
for (i = 0; i < rp; i++) {
while ('0' == *s)
;
*s = '0';
}
}
ここまで作業すると、メモリファイルシステムは次のような状況になっているはずだ。
% df -h Filesystem Size Used Avail Capacity Mounted on /dev/ada0p2 94G 3.3G 83G 4% / devfs 1.0k 1.0k 0B 100% /dev /dev/md0 9.4M 8.0k 8.7M 0% /tmp1 /dev/md1 9.4M 8.0k 8.7M 0% /tmp2 tmpfs 4.3G 4.0k 4.3G 0% /tmp3 %
% mount /dev/ada0p2 on / (ufs, local, journaled soft-updates) devfs on /dev (devfs, local, multilabel) /dev/md0 on /tmp1 (ufs, local) /dev/md1 on /tmp2 (ufs, local) tmpfs on /tmp3 (tmpfs, local) %
基本的にバックエンドのファイルシステムを変更しただけで、処理するmmap(2)のコードは同じだ。
実行速度の比較結果
ここまで準備したら実行速度を測定する。/usr/bin/timeとtruss(1)を使って、送信側のプロセスについて処理時間やリソースの消費具合、システムコールの呼び出し回数などを調べる。ここではFreeBSD 9.0-RELEASEで計測を実施した。
| 実装方法 | 実行時間[秒] |
|---|---|
| mmap+fork:r | 77.94 |
| mmap+fork:u | 77.84 |
| mmap+fork:s | 0 |
| mmap+md(malloc):r | 77.8 |
| mmap+md(malloc):u | 77.7 |
| mmap+md(malloc):s | 0 |
| mmap+md(swap):r | 78.19 |
| mmap+md(swap):u | 78.09 |
| mmap+md(swap):s | 0 |
| mmap+tmpfs:r | 78.16 |
| mmap+tmpfs:u | 78.06 |
| mmap+tmpfs:s | 0 |
| mmap+ufs:r | 77.92 |
| mmap+ufs:u | 77.81 |
| mmap+ufs:s | 0 |
| 表1 /usr/bin/timeとtruss(1)を使って計測した送信側プロセスの処理時間 | |
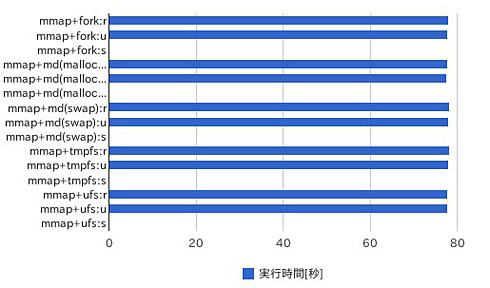
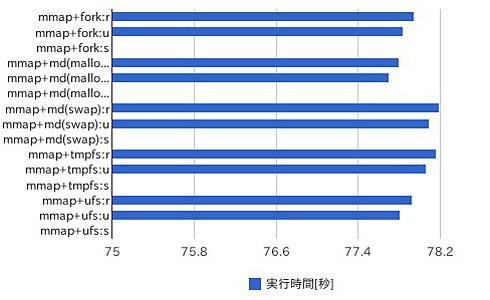
処理時間のほとんどがユーザー時間で消費されており、システム時間がほとんど発生していないことが分かる。mmap(2)を使い共有メモリを利用することで、処理がカーネルに渡る時間が省略されていることも分かるだろう。
実行速度ではmdconfig(8)+malloc(9)が最速で、mmap(2)+fork(2)とmmap(2)+ufsがそれに続く結果になっている。ただ、最も速いものと最も遅いものとを比較しても0.5%も差がなく、それほど際立った性能差が見られるとはいいにくい。
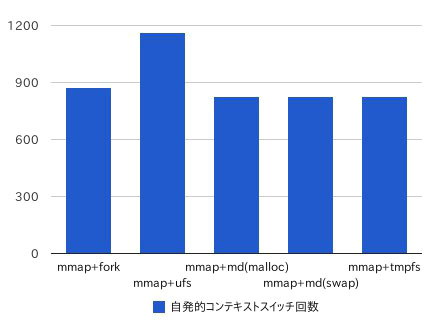
/usr/bin/timeが報告する結果では、あとは自発的なコンテキストスイッチの回数に若干の差が見られる。しかし今回のケースでは、それほど性能には影響を及ぼしているようには見えない。
| 実装方法 | 自発的コンテキストスイッチ回数 |
|---|---|
| mmap+fork | 875 |
| mmap+ufs | 163 |
| mmap+md(malloc) | 824 |
| mmap+md(swap) | 828 |
| mmap+tmpfs | 828 |
| 表2 /usr/bin/timeで計測した自発的なコンテキストスイッチの回数 | |
truss(1)で計測したシステムコールの呼び出し回数には、下記の通りほとんど違いが見られず、ほとんどの処理をユーザー側で処理していることが分かる。
| 実装方法とシステムコール回数 | fork | lseek | mmap | open | close | fstat |
|---|---|---|---|---|---|---|
| mmap+fork | 1 | 1 | 7 | 3 | 2 | 1 |
| mmap+ufs | 0 | 1 | 7 | 4 | 2 | 1 |
| mmap+md(malloc) | 0 | 1 | 7 | 4 | 2 | 1 |
| mmap+md(swap) | 0 | 1 | 7 | 4 | 2 | 1 |
| mmap+tmpfs | 0 | 1 | 7 | 4 | 2 | 1 |
| 実装方法とシステムコール回数 | access | sigprocmask | munmap | read |
|---|---|---|---|---|
| mmap+fork | 1 | 8 | 1 | 2 |
| mmap+ufs | 1 | 8 | 1 | 2 |
| mmap+md(malloc) | 1 | 8 | 1 | 2 |
| mmap+md(swap) | 1 | 8 | 1 | 2 |
| mmap+tmpfs | 1 | 8 | 1 | 2 |
| 表3 truss(1)で計測したシステムコールの呼び出し回数 | ||||
単純に考えると、UFSをバックエンドにした場合に性能が劣化しそうに思えるが、今回のケースではそういった性能劣化は起こっていない。
考察、そして次回へ
今回の実装でほとんど実行速度に差が見られないのは、共有メモリを4KB(1ページ分)しか利用しておらず、実際やりとりしているデータも2バイトに過ぎないためではないかと考えられる。この状況で性能差を生む方が難しいだろう。
今回はここでいったん止めておき、次回、もっと大きなデータを読み書きさせた場合にどのような違いが現れるかを検証する。
今回のまとめとしては、共有メモリを活用することで性能の向上を実現でき、その実装にはいくつかの方法があることを知ってもらえればと思う。ここでは共有メモリの実装としてmmap(2)システムコールを利用しているが、ほかにも、SYSV共有メモリ系の実装としてshmget(2)/shmat(2)/shmctl(2)/shmdt(2)、またシステムコールではなく標準ライブラリとなるがPOSIX.1系のsem_open(3)/sem_close(3)/sem_unlink(3)なども存在する。
著者紹介
BSDコンサルティング株式会社取締役/オングス代表取締役
後藤 大地
@ITへの寄稿、MYCOMジャーナルにおけるニュース執筆のほか、アプリケーション開発やシステム構築、『改訂第二版 FreeBSDビギナーズバイブル』『D言語パーフェクトガイド』『UNIX本格マスター 基礎編〜Linux&FreeBSDを使いこなすための第一歩〜』など著書多数。
Copyright © ITmedia, Inc. All Rights Reserved.