Apache Mahout偺巊偄曽丗僥僉僗僩暘椶偺傾儖僑儕僘儉傪妶梡偡傞丗Mahout偵傛傞婡夿妛廗偺幚嵺乮2/3 儁乕僕乯
婡夿妛廗偼屆偔偐傜偁傞忣曬張棟偺傾儖僑儕僘儉偺憤徧偱偡丅偙傟傪Apache Hadoop忋偱幚巤偡傞嵺偺僼儗乕儉儚乕僋偺1偮偑Apache Mahout偱偡丅杮峞偱偼Apache Mahout傪巊偭偨婡夿妛廗偺弶曕傪妛傫偱偄偒傑偡丅
Mahout偱乽暥彂暘椶乿偵挧愴偟偰傒傛偆
僨乕僞偺儀僋僞壔
丂Mahout偺僫僀乕僽丒儀僀僘偱寁嶼張棟偑偱偒傞傛偆丄慜儁乕僕偱MeCab傪巊偭偰惗惉偟偨僥僉僗僩僼傽僀儖傪丄偝傜偵儀僋僞宍幃偵曄姺偟傑偡丅
丂偼偠傔偵丄暘偐偪彂偒偟偨僼傽僀儖傪Hadoop撪偵奿擺偟丄僔乕働儞僗僼傽僀儖宍幃偵曄姺偟傑偡丅Hadoop偵偍偗傞僔乕働儞僗僼傽僀儖偲偼丄Hadoop撪偱偺崅懍側張棟傪栚揑偲偟偨僉乕僶儕儏乕宆偺僨乕僞奿擺僶僀僫儕僼傽僀儖偱偡丅壓婰偺傛偆偵丄nb/偲偄偆僨傿儗僋僩儕傪嶌惉偟丄惵嬻暥屔偺僨乕僞傪僔乕働儞僗僼傽僀儖偲偟偰奿擺偟傑偡丅
hadoop fs -mkdir nb hadoop fs -put aozora nb/ $MAHOUT_HOME/bin/mahout seqdirectory -i nb/aozora -o nb/aozora_seq
丂僔乕働儞僗僼傽僀儖宍幃偵曄姺偟偨僼傽僀儖偺撪梕傪妋擣偡傞偲丄師偺傛偆偵側偭偰偄傑偡丅乽seqdumper乿偼丄僔乕働儞僗僼傽僀儖傪僥僉僗僩偵曄姺偟偰壜帇壔偡傞Mahout偺僣乕儖偱偡丅seqdumper偺僐儅儞僪傪巊偭偰妋擣偟偰傒傑偟傚偆丅
$MAHOUT_HOME/bin/mahout seqdumper -i nb/aozora_seq -n 3 -b 30 Key: /0_憤婰/乽暟彂帪戙乿偺弌尰.txt.wakati: Value: 棫朄 晹栧 偑 帺暘 偱 棫朄 婡娭 傪 傕偮 偲偄偆 Key: /0_憤婰/僲僂傾僗僼傿傾偺奐崵.txt.wakati: Value: 1 偦傕偦傕 偺 柕弬 僀儞僞乕僱僢僩 偺 Key: /0_憤婰/僴僢僇乕椣棟偲忣曬岞奐丒僾儔僀僶僔乕.txt.wakati: Value: 1 偼偠傔 偵 僋儕儞僩儞 惌尃 偑 忣曬 僗乕僷
丂Key偵僨傿儗僋僩儕僷僗傪娷傓僼傽僀儖柤丄Value偵僥僉僗僩暥彂偺慡暥偑擖偭偨僼傽僀儖偑偱偒偰偄傑偡丅偙偺屻偺Mahout僫僀乕僽丒儀僀僘偺張棟偵偍偄偰丄Key偵彂偐傟偨1偮栚偺僨傿儗僋僩儕柤乮乽0_憤婰乿側偳乯偑暘椶偝傟偨僇僥僑儕偲偟偰埖傢傟傞偙偲偵側傝傑偡丅
丂師偵僔乕働儞僗僼傽僀儖傪乽seq2sparse乿傪巊梡偟偰儀僋僞壔偟傑偡丅
$MAHOUT_HOME/bin/mahout seq2sparse \ -i nb/aozora_seq \ -o nb/aozora_vectors \ -a org.apache.lucene.analysis.core.WhitespaceAnalyzer \ -ow
丂儀僋僞壔偡傞嵺偵僆僾僔儑儞偱偝傑偞傑側愝掕偑偱偒傑偡丅僫僀乕僽丒儀僀僘偺寁嶼張棟偺愢柧偱弎傋偨廳傒晅偗曽幃傗奺庬惓婯壔丄尵梩偺拪弌偵娭偡傞愝掕側偳丄幚嵺偺暘愅嶌嬈偱偼暘愅張棟傪堦搙幚峴偟偨屻丄僠儏乕僯儞僌偵傛傞暘愅惛搙岦忋偺偨傔偵搙乆偙偙偵栠偭偰棃傞偙偲偵側傝傑偡丅偙偙偱偼暘偐偪彂偒偝傟偨僥僉僗僩暥復偐傜偺扨岅偺拪弌傪乽WhitespaceAnalyzer乿傪梡偄偰峴偄丄懠偼愝掕側偟乮偮傑傝僨僼僅儖僩偺愝掕乯偱幚峴偟偰偄傑偡丅
岎嵎専掕偺偨傔偺僨乕僞暘妱
丂杮峞偱偼乽岎嵎専掕乿偺峫偊曽傪梡偄偰僨乕僞偺暘妱傪峴偄傑偡丅堦斒偵丄岎嵎専掕偲偼暘愅偡傞僨乕僞悢偑彮側偄応崌偵梡偄傜傟傞庤朄偱丄僨乕僞慡懱偺堦晹傪妛廗僨乕僞偲偟偰夝愅偵巊梡偟丄巆傝偺僨乕僞傪帋尡僨乕僞偲偟偰夝愅撪梕傪僥僗僩偡傞偙偲偱丄夝愅撪梕偺懨摉惈傪専徹偟傑偡丅
丂慡懱偺棳傟偼壓恾偺捠傝偱偡丅僨乕僞偺暘妱偐傜暘椶幚峴傑偱傪孞傝曉偟乮儖乕僾乯丄彮側偄僨乕僞偱儌僨儖昡壙帺懱偺惛搙傪崅傔傞偙偲偑岎嵎専掕偺慱偄偱偡丅杮峞偱偼丄偙偺1儖乕僾栚偺傒傪埖偄傑偡丅
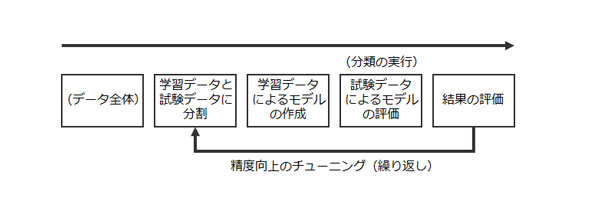
丂愭傎偳偺儀僋僞壔偟偨僼傽僀儖傪乽split乿偵傛傝妛廗僨乕僞偲帋尡僨乕僞偵暘妱偟傑偡丅
丂偙偙偱偼儔儞僟儉偵暘妱偡傞妱崌乮rs(randomSelectionPct)乯傪20亾偲偟偰丄妛廗僨乕僞乮aozora_train_vectors乯傪80亾丄帋尡僨乕僞乮aozora_test_vectors乯傪20亾偲偟偰暘妱偟傑偡丅
$MAHOUT_HOME/bin/mahout split \ -i nb/aozora_vectors/tfidf-vectors \ -tr nb/aozora_train_vectors \ -te nb/aozora_test_vectors \ -rs 20 \ --sequenceFiles \ -xm sequential -ow
儌僨儖偺嶌惉乛暘椶偺幚峴
丂僫僀乕僽丒儀僀僘偺妛廗幚憰乽trainnb乿傪梡偄偰丄妛廗僨乕僞傪擖椡偲偟偰儌僨儖乮aozora_model乯傪峔抸偟傑偡丅
丂trainnb偺僆僾僔儑儞偱丄擖椡偡傞妛廗僨乕僞僼傽僀儖(i)丄弌椡偡傞儌僨儖僼傽僀儖(o)丄弌椡偡傞僇僥僑儕偺儔儀儖僼傽僀儖(li)丄僇僥僑儕儔儀儖偺弌椡(el)丄弌椡僼傽僀儖偺忋彂偒(ow)傪巜掕偟偰偄傑偡丅懠偵乽-c乿偱曗姰宆僫僀乕僽丒儀僀僘乮Complementary NaiveBayes乯偱偺幚峴傕巜掕偱偒傑偡丅
丂傑偨丄testnb偺僆僾僔儑儞偱丄擖椡偡傞僨乕僞僼傽僀儖(i)丄擖椡偡傞儌僨儖僼傽僀儖(m)丄擖椡偡傞僇僥僑儕偺儔儀儖僼傽僀儖(li)丄弌椡偡傞幚峴寢壥僼傽僀儖(o)丄弌椡僼傽僀儖偺忋彂偒(ow)傪巜掕偟偰偄傑偡丅trainnb偲摨條偵乽-c乿傕巊梡偱偒傑偡丅
$MAHOUT_HOME/bin/mahout trainnb \ -i nb/aozora_train_vectors \ -o nb/aozora_model \ -li nb/aozora_labelindex \ -el -ow
丂懕偄偰帋尡幚憰乽testnb乿偵傛傝丄峔抸偟偨儌僨儖傪巊梡偟偰帋尡僨乕僞偺暘椶傪幚峴偟傑偡丅
$MAHOUT_HOME/bin/mahout testnb \ -i nb/aozora_test_vectors \ -m nb/aozora_model \ -l nb/aozora_labelindex \ -o nb/aozora_test \ -ow
暘椶偺幚峴寢壥乛儌僨儖偺昡壙
丂暘椶傪幚峴偡傞偲丄昗弨弌椡偲偟偰暘椶寢壥偺奣梫偑弌椡偝傟傑偡丅
======================================== Summary ---------------------------------------- Correctly Classified Instances : 80 66.1157% Incorrectly Classified Instances : 41 33.8843% Total Classified Instances : 121 ======================================== Confusion Matrix ---------------------------------------- a b c d e f g h i j <--Classified as 5 0 0 4 0 1 1 2 0 1 | 14 a = 0_憤婰 0 5 0 3 0 0 1 0 0 4 | 13 b = 1_揘妛 1 0 6 2 0 0 0 0 0 0 | 9 c = 2_楌巎 0 0 0 7 0 0 0 1 0 2 | 10 d = 3_幮夛壢妛 1 0 1 0 3 0 0 0 0 0 | 5 e = 4_帺慠壢妛 0 0 1 0 1 20 0 0 0 1 | 23 f = 5_媄弍丒岺嬈 0 0 0 0 0 0 5 0 0 0 | 5 g = 6_嶻嬈 0 0 1 2 0 0 0 7 0 1 | 11 h = 7_寍弍丒旤弍 0 0 1 0 0 0 0 0 5 4 | 10 i = 8_尵岅 0 0 0 1 0 0 0 1 2 17 | 21 j = 9_暥妛 ======================================== Statistics ---------------------------------------- Kappa 0.4739 Accuracy 66.1157% Reliability 59.308% Reliability (standard deviation) 0.277
丂暘椶寢壥傪尒傞偲丄Summary偲偟偰丄帋尡僨乕僞121屄偵懳偟丄惓偟偔暘椶偝傟偨僨乕僞偑80屄丄娫堘偭偰暘椶偝傟偨僨乕僞偑41屄偱偁傝丄惓夝棪偑66.1亾偱偁偭偨偙偲偑弌椡偝傟偰偄傑偡丅
丂懕偄偰丄偦偺撪栿偲偟偰丄崿摨峴楍乮Confusion Matrix乯偑丄偦傟偧傟杮棃偺乮僨乕僞偲偟偰搊榐偟偰偄傞乯僇僥僑儕偼乽峴乿丄暘椶幚峴偟偨寢壥偺僇僥僑儕偼乽楍乿偲偟偰弌椡偝傟偰偄傑偡丅嵍忋偐傜塃壓傊偺懳妏慄忋偺抣偑惓夝偺悢丄偦傟埲奜偺抣偑晄惓夝偺悢偱偡丅
丂嵟屻偵摑寁忣曬偲偟偰怣棅嬫娫偵娭偡傞忣曬偑弌椡偝傟偰偄傑偡丅怣棅嬫娫偲偼丄曣悢偑偳偺傛偆側斖埻偵偁傞偐傪妋棪揑偵帵偡傕偺偱偡丅
丂師儁乕僕偱偼丄幚峴寢壥偺捛愓曽朄丄暘愅惛搙傪岦忋偝偣傞椺傪尒偰偄偒傑偡丅
Copyright © ITmedia, Inc. All Rights Reserved.