IoTやビッグデータ分析が注目される現在、企業がSparkでビジネスを拡大するには:“エンタープライズSpark”超入門
Hadoopよりも高速なデータ分析ができると話題のApache Spark。Sparkを企業で活用し、本当の意味でのビッグデータ分析を行ってビジネスに役立てるためには、どのようにすればよいのだろうか。
IoTやビッグデータが注目されている中、Apache Hadoop(以下、Hadoop)よりも高速でニアリアルタイムに大規模データを分析できる存在としてApache Spark(以下、Spark)が注目されている。オープンソースとして提供されているSparkを企業で活用し、本当の意味でのビッグデータ分析を行ってビジネスに役立てるためには、どのようにすればよいのだろうか。日本アイ・ビー・エム アナリティクス事業部 テクニカル・リードの土屋敦氏に話を聞いた。
Hadoopよりも扱いやすく高速なSpark
Sparkは、2009年にカリフォルニア大学バークレー校のAMPLabのプロジェクトとして生まれ、2010年にオープンソース化されて以降、Apache Software Foundationで最もアクティブなプロジェクトの一つとして進化を続けている。Sparkは、分散クラスター環境で積極的なメモリキャッシュ処理が行えるだけではなく、さまざまな工夫や最適化がされており、Hadoopよりもオーバーヘッドなどが少なく、より高速に処理でき、より使いやすいことで注目を集めている。
IoTが注目される中、大量かつリアルタイムに発生するデータを収集して、どのように有効活用するかが重要になってきている。IBMでは、これらの分析を行うプラットフォームとしてSparkに注目しており、前述のAMPLabの創設メンバーの一社としてSparkの開発に貢献してきた。
また、100万人のデータサイエンティストとデータ活用の技術者育成を目指して投資を継続し、「Sparkテクノロジ・センター」を設立。AMPLabや、AMPLabの開発メンバーが中心となって設立されたDatabricks社と協業し、これまでIBMが培ってきた機械学習のライブラリ「SystemML」をオープンソースソフトウエアとして提供している。これにより、機械学習アルゴリズムの精度を上げて大規模データでも利用できるようにする他、IBM社内でもさまざまなプロジェクトでSparkを使い、コミュニティにノウハウをフィードバックしてきた。
さらにIBMは、MOOC(Massive Open Online Course)の「Big Data University」上で、教育プログラムを提供し、Sparkのテクノロジを正しく理解するための啓蒙活動も行っている。

IBMは、なぜSparkというオープンソーステクノロジに投資を行い、活用を推進しているのだろうか。土屋氏によると、その理由は二つある。一つは、SparkがHadoopと比べて処理が高速であること。もう一つは、エンジニアだけが使えるテクノロジではなく事業部門のデータ分析者でも扱いやすく、クラウドでも利用できるなど、導入のハードルが低いという特徴があり、分析者とエンジニアの架け橋となり得ることだ。
「IBMは、データ活用・機械学習の仕組みの手段の一つとしてSparkが有効だと考え、推進しています。ディスラプティブテクノロジ(破壊的技術)を持つIoTのプレーヤーが多数出てくる中で、『テクノロジの鍵』となり得るのがSparkであり、これらの技術を使ってリアルタイム分析などを行っていかなければ、今後は新しいプレーヤーやビジネスに対応していけないと考えています」
Sparkを企業や組織で活用しているIoT事例
IBMでは、実際に自社の製品にもSparkを組み込み、Sparkをエンタープライズで使えるようなソリューションの提供や導入のコンサルティングも行っている。製品としては、オンプレミス型とクラウド型の2種類が提供され、オンプレミス型は「IBM BigInsights for Apache Hadoop」の1コンポーネントとして、クラウド型は「IBM Bluemix」の一部として「Spark as a Service」が提供されている。
海外では、多くの企業や公共交通機関などですでにSparkやストリーミング処理を使った分析が行われている。例えば、高速ボートレースチームの「SilverHook Powerboats」では、IBM Bluemixとストリーミング処理を利用し、「IBM Internet of Things Foundation」でセンサーからデータを収集し、デバイスで可視化してボート操縦者に伝える他、短い間隔で分析を行うことでエンジン出力や油圧系の異常などを検出することを実現している。

「Sparkなどの新しい技術を使ったさまざまなアイデアを、自社の業務にどのように合わせていくかを考えることが重要です。ニアリアルタイムに近い分析や機械学習を行うことで、企業にさまざまな可能性が生まれてきます」
例えば、位置情報を活用して、店舗などに近づいた顧客のスマートフォンにレコメンドする仕組みなどが数年前から注目されているが。ただ従来は1カ月前の分析結果を基にレコメンドしていたものを、リアルタイムに分析することで、より短い間隔、適切なタイミングでレコメンドすることが可能になる。これによりレコメンド効果を大きく上げることができる。
また、工場のパイプラインなどの管理や、空調管理・電源管理などもリアルタイムかつ適切に行えるようになれば、コスト削減や生産性向上を目指すことができるようになるだろう。
「リアルタイム処理やストリーム処理を行うことで、既存のサービスの質を向上させたり、新たなビジネスを創出したりすることが可能になる。これまで実現できなかったものを実現するような、新しい試みを行うプロジェクトにこそSparkを活用するメリットがある」
クラウドで簡単に始められる
「オンプレミス型は、これまでHadoopを使っていてSparkにも挑戦したいと考えるお客さまが多く、これから新規にSparkを始められる場合はクラウドのSpark as a Serviceを使うお客さまがほとんどです」と話す土屋氏は、企業がSparkを導入する理由について次のように説明する。
「これからの分析は、データベース、Hadoop、Sparkのいずれかのテクノロジだけを使っても、うまくはいきません。これまでトランザクション系や業務系で行ってきた一意的なデータ処理ではなく、処理が多様化してきているため、さまざまなテクノロジを組み合わせて使う必要が出てきています。Hadoopだけでは実現できない場合は、HadoopとSparkを組み合わせたり、ストリーム処理を行う『Spark Streaming』を組み合わせたりすることで、さまざまな処理ができるようになります」
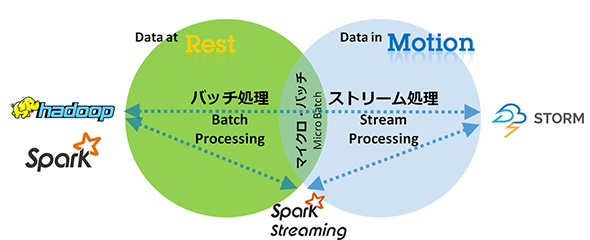
例えば、オンプレミス型のIBM BigInsights for Apache HadoopのコンポーネントとしてSparkを利用する場合は、「IBM SPSS Modeler」や、さまざまなミドルウエアとも連携が可能。Sparkを利用することで、Hadoopよりも高速に分析の繰り返し処理を行うなど、HadoopとSparkを使い分けて利用することが可能となる。
一方で、前述のように「これからSparkを始めたい」と考えているユーザーに対して土屋氏は、「クラウド型のSpark as a Serviceをお勧めする」と説明する。クラウドで利用できるため、インフラを気にすることなく、素早く始めることができ、必要に応じてクラウド上でスケールアウトすることも可能。必要であれば、オンプレミス型に移行して、Hadoopと共に利用することもできる。Sparkを使った分析からビジネスのアイデアを生み出せるかどうかを試すことができ、結果が出せれば、本格的な導入へと進めることができるわけだ。
また、前述のSilverHook Powerboatsの事例のように、データ分析をIBM Bluemixの各機能と連携させて、分析結果をアクションへとつなげることが可能だ。IoTでは、センサーデバイスからのデータ取得、クラウドへのデータ蓄積、データ解析結果をサービス改善に生かすトータルなソリューションが必要となるが、これらとの連携のしやすさがSparkの強みとなる。
加えて、分析の行いやすさも、Sparkの魅力の一つとなっている。Sparkは、SQL、R、Python、Java、Scalaといった言語で使うことができ、「Notebook」などのGUIもあるため、Hadoopに比べて取り組みやすい仕様となっている。これによって、マーケティング担当者など、社内のさまざまな役割の人や分析者がSparkを利用でき、多角的に分析を行うことで、より多くのビジネスアイデアを生み出すことができるようになる。
Sparkの分析結果をアクションにつなげることが重要
IBMはこれまで、中立的なコミュニティベースでSparkと向き合っており、勉強会などでも自社製品の話をするのではなく、Sparkをどのように活用するかという話に重きを置いてきた。IBM BigInsights for Apache HadoopのSparkコンポーネントも100%オープンソースソフトウエアとなっている。これについて土屋氏は「Sparkやクラウドがもたらすメリットがあまりにも大きいからです。『Sparkといえば、まずIBM』というふうに思っていただきたい」と理由を述べる。
加えて土屋氏は、「お客さまにとっては、ソフトウエアを導入して終わりではありません」とも指摘。「一緒に分析を行って、どのようにアクションにつなげて効果を出すかを共に考え、スキルトランスファーを行うことも大切です。つまり、コンサルチームがいなくなっても、お客さま自身で継続して分析を行えるようにすることが重要なのです」と、コンサルチームの役割と意義を力説する。もしデータ基盤や分析基盤を組織横断的に利用できるようになったとしても、「誰が何のためにどう使うのか?」つまり「何を実現しようとしているのか?」を明確にできることが重要になります。
エンタープライズでSparkのような新しいテクノロジを活用するためには、Sparkやインフラのことだけ知っていてもビジネスに活用できない。システム間連携やデータ連携でアクションをどのようにつなげるかを考えるためには、エンタープライズでIBMが培ってきた知識が必要になるというわけだ。
「われわれは、分析結果の活用方法から展開時の組織体制まで、柔軟にサポートを行えます。まずは、クラウドでSparkを試してみてください。分析の選択肢にSparkを加えることで、これまでバッチで分析していたものをニアリアルタイムに近づけることができます。例えば、マーケティング部門など現場のリクエストに応える分析を行って、アクションにつなげることができるようになります」
このように、IoTがビジネスを拡大する現代において、その有力な武器となるSparkを導入するハードルは確実に下がっている。いわばスタートアップ企業でもSparkのような高速なデータ分析基盤を導入しやすくなっているのだ。大量かつリアルタイムに発生するデータを収集して、有効活用することでビジネスを拡大したい方は、チャレンジしてみてはいかがだろうか。
おすすめホワイトペーパー
Hadoopよりも高速なSparkの活用を積極推進するIBMは何をしようとしているのか?
「Apache Spark」は、Hadoopよりも高速で、ほぼリアルタイムに大規模データを分析できるシステム として注目されている。目前に迫るIoT時代に向けて、IBMはSparkの活用を積極推進している。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 Apache Sparkに注力するIBM、目指すは「データ分析のOS」
Apache Sparkに注力するIBM、目指すは「データ分析のOS」
北米トヨタ販売子会社での採用事例の発表などもあり、日本国内でも注目を集めつつある「Apache Spark」。具体的にはどんな特徴があって、何ができるのだろうか。Sparkへの大規模投資を発表したIBM(日本IBM)を取材した。 Hadoop→Redshift→その先は?――IoT/ハイブリッド時代の最新トレンドを整理する
Hadoop→Redshift→その先は?――IoT/ハイブリッド時代の最新トレンドを整理する
人間や機械の活動をデータとして取り込むIoTの出現で、クラウド上の「データベースサービス」をエンタープライズでも利用する場面が増えてきた。データベースとクラウドの関係、データ活用のリアルを、ITジャーナリスト 谷川耕一氏の視点でひも解く。 Hadoopは「難しい・遅い・使えない」? 越えられない壁がある理由と打開策を整理する
Hadoopは「難しい・遅い・使えない」? 越えられない壁がある理由と打開策を整理する
ブームだったHadoop。でも実際にはアーリーアダプター以外には、扱いにくくて普及が進まないのが現状だ。その課題に幾つかの解決策が出てきた。転換期を迎えるHadoopをめぐる状況を整理しよう。
関連リンク
提供:日本アイ・ビー・エム株式会社
アイティメディア営業企画/制作:@IT 編集部/掲載内容有効期限:2015年12月29日

