Hadoopは「難しい・遅い・使えない」? 越えられない壁がある理由と打開策を整理する:転換期を迎えるHadoop(1/2 ページ)
ブームだったHadoop。でも実際にはアーリーアダプター以外には、扱いにくくて普及が進まないのが現状だ。その課題に幾つかの解決策が出てきた。転換期を迎えるHadoopをめぐる状況を整理しよう。
ビッグデータの申し子のように騒がれた「Hadoop」。以前ほどメディアを騒がせてはおらず、それほど広範囲に普及したようにも思えないものの、いまだ注目されるにふさわしい存在なのは間違いありません。しかし、今日の、あるいはこれからのHadoopがどのように進化しているのかを知れば、Hadoopを諦めていた方々も再度注目しようと思われるのではないでしょうか。
そもそもHadoopとは……? の禅問答っぽさ
突然ですが、「Hadoopとは何ですか?」と説明を求められたら、皆さんならどう答えますか?
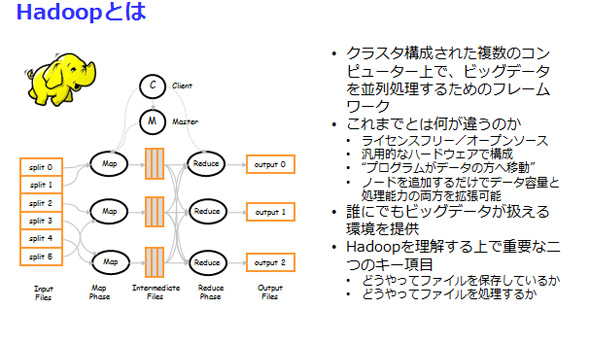
Q.「Hadoopとは何ですか?」
Ans.
- 複数のサーバーで構成され、MapReduceと呼ばれる仕組みで分散処理を行う環境であること
- データも共有ストレージではなく、各サーバーの内蔵ディスクに分散して格納されること
- HDFSと呼ばれる独自のファイルシステムがあり、データの分散については自動的に行われること
- ディスクやサーバーの障害に備えて、3カ所にコピーが存在すること
私ならこのように説明しますが、これでは不足しているともいえますし、最初の説明としては十分だともいえるでしょう。
いずれにしても、いざこの先を理解しよう、実際に環境を構築してみようとなると、突然ハードルが上がってしまう。そんなイメージを筆者は持っていますが、この連載を読み進めるに当たっては、上記が分かっていれば十分です。
むしろ、それ以上を求められて挫折してしまう(しまった)方たちにこそ、いま転換期を迎えているHadoopを知っていただきたいのです。
Hadoopは何を転換しようというのか
誕生してわずか数年とはいえ、拡大と進化を続けるHadoopにとって、大きな課題がいくつか挙げられます。今回は、主となる三つの課題のうち二つを取り上げて、どのように転換期を迎えているのかを紹介します。残る一つについては次回、詳しく紹介します。
1:HDFSが従来のファイルシステムと比べて扱いづらい
Hadoopで利用するHDFSは、LinuxやWindowsなどで一般に用いられるファイルシステムとは異なるため、そこにあるファイルを既存のツールからは読み書きできません。
従って、Webサーバーにたまったログにしても、データベースに蓄えられたデータにしても、Hadoopで扱うためにはファイルの移動またはコピーという面倒が発生するのです。それも、一般的なファイルコピーの方法が使えるわけではなく、HDFS独特なAPIを呼び出す方法で行わなくてはなりません。
大容量のデータを、安く、しかも高い可用性で取り扱うことを優先した結果ではあるのですが、一般に受け入れられるには課題となりました。たいていの場合、Hadoopにいきなりデータが蓄えられるのではなく、どこかから持ってくるでしょうから、こうした手間と時間がかかることはHadoopを使いづらいと評価する要因となったのです。
この点については、Hadoopを製品化して有償で提供するベンダーの中には、独自のファイルシステムを提供して解決を図っているものがあります。代表的な例としては、IBMのBigInsightsが提供するGPFS-FPO、あるいはMapRが提供するファイルシステムが挙げられます。それらを使えば、一般的なファイルシステムと同様の操作性を手に入れられ、課題を解決できます。
2.MapReduce処理が遅い、扱いづらい
ファイルシステムの問題だけでなく、肝心のMapReduceについても、その扱いづらさと処理の遅さが指摘されることがありました。
扱いづらさは、MapReduceのフレームワークやAPIに対する慣れの問題も大きく、プログラミングの経験を積むことで解消する面もあります。しかし、処理の遅さについてはチューニングの余地などもなく、改善を期待する声が多くありました。実際問題、MapReduceはJavaで書かれていることも手伝って、あるいは大規模なデータをバッチ処理的に扱う前提であるがゆえに、いくつものオーバーヘッドがあるのです。
これについても、有償でHadoopを製品として提供するベンダー各社は、独自にC言語で書かれたものと置き換えるなどの工夫をしてきました。また、オープンソースのプロジェクトとしても、YARNやMR2(MapReduce Version2)、はたまたSparkなど、この問題を解消する取り組みが活発に行われています。特にYARNが追加されたHadoopは、Hadoop 2.x系と呼ばれていて、まさに大きな転換点となったのです。
Copyright © ITmedia, Inc. All Rights Reserved.