Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか:Deep Learningで始める文書解析入門(1)(2/2 ページ)
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。
Recurent Neural Networkの場合
一方、RNNはFeedforward Neural Networkと違い、それまでインプットされた状態全てを隠れ層に統合します。その時点までのデータの情報を使用することで、インプットの系列情報をフルに活用できるモデルです。
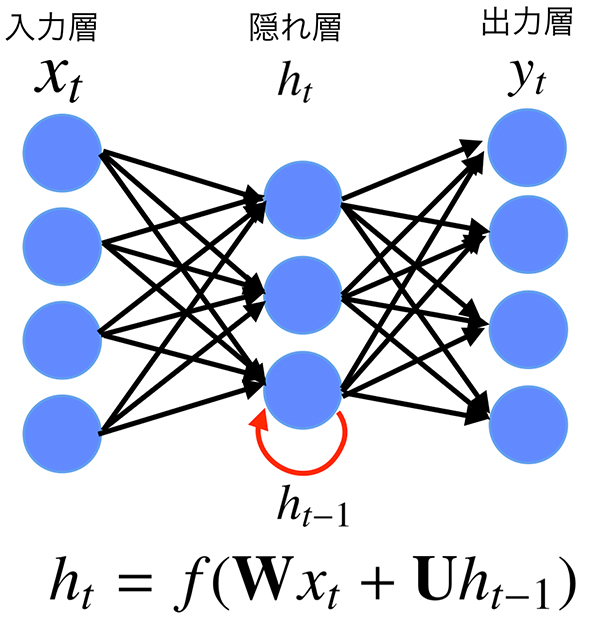
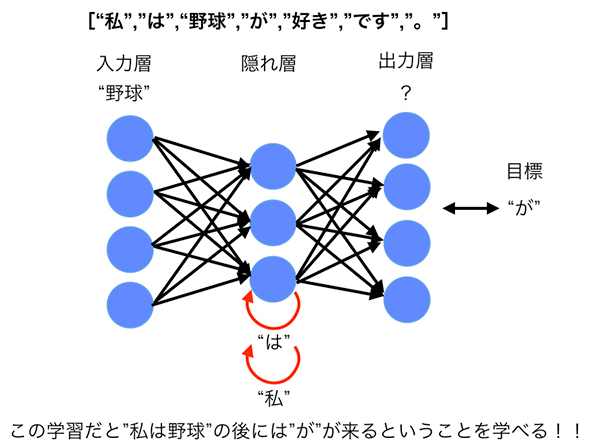
例えば、"野球"がインプットされたときに、直前に「"は"を入力とした状態」を考慮するため、隠れ層で表現されるベクトルは"野球"だけではなく、「"は"+"野球"を表すベクトル」になります。
"は"+"野球"→"が"
さらに、「"は"を入力したときの隠れ層」では、その前の時点の「"私"を入力としたときの隠れ層の状態」を加味しています。
"私"→"は"+"野球"→"が"
このため、最終的に"野球"をインプットにしたときの隠れ層は"私"+"は"+"野球"という単語列を表現したベクトルとして解釈できます(図4)。このため、「"野球"の後に"が"が来る」ことが、より自然なことになります。
"私"+"は"+"野球"→"が"
このようにRNNでは理論上、過去の状態全てを加味した学習が可能で、文脈によって次に来る単語が異なる場合において、特にその効果を発揮します。
「誤差逆伝播法」と「BPTT(BackPropagation Through Time)」
重みの更新には「誤差逆伝播法(BackPropagation)」というアルゴリズムを用いますが、RNNの場合も基本的に同じです。特にRNNの場合では、時間をさかのぼって伝播(でんぱ)するイメージから「BackPropagation Through Time(BPTT)」と呼ぶこともあります。
しかし実際は、BPTTを行う際に誤差が薄まったり、逆に膨大に膨らんだりするため、長期的な系列の学習には課題が残ります。そこで、長めの系列状態を学習させたい場合はRNNを発展させた「Long Short Term Memory(LSTM)」「Gated Recurrent Units(GRU)」利用します。
LSTMについては連載の後半で少し詳しく紹介する予定です。
Recurrent Neural Networkの利用例
RNNの代表的な利用例を紹介します。
【1】レコメンデーション
「Matrix Factorization」などのレコメンド手法では、まずアイテム同士の「共起」(あるユーザーが見ているアイテム群の組み合わせ)を基に、アイテムの特徴(もしくはユーザーの特徴)をベクトルで算出し、近いアイテムをレコメンドするという作りになっていました。その際、一般には、アイテムを閲覧した順序などは考慮されていませんでした。
RNNをレコメンドに応用する場合、先ほどの["私","は","野球","が","好き","です","。"]といった単語列を、あるユーザーが閲覧したアイテムに置き換えます。
例えば、ユーザーAさんがアイテム1を見た後にアイテム3を見てアイテム2を閲覧している場合、下記のような具合になります。
["アイテム1","アイテム3","アイテム2"]
この形のデータを大量のユーザーに対して取得し、学習させることで、「アイテム1→アイテム3」に遷移してきたユーザーにはアイテム2をレコメンドするといった系列ベースのレコメンドが可能になります。
"アイテム1"+"アイテム3"→"アイテム2"
RNNを用いたレコメンドについては『[1511.06939] Session-based Recommendations with Recurrent Neural Networks』で詳しく説明されています。
【2】文書分類
RNNの活用例として、もう1つ「文書分類」が挙げられます。文書分類とは、例えば、メールのスパム判定のようなタスクがイメージしやすいと思います。
文書分類において最も単純な方法は「Bag of Words」(各文書を単語に分解し、各単語が何回出現しているかをベクトルとして表現したもの)をとり、「ナイーブベイズ」を用いて分類をするものです。ナイーブベイズの詳細な説明は省きますが、簡単にいうと「ある単語Aがあるときに、スパムである確率を算出し、それを文書中の各単語分だけ求め掛け合わせる」手法です。
ナイーブベイズの問題点の1つに、「単語の出現順序を考慮できない」ことがあります。例えば、下記の2つの文章では人間が見ると全く違う意味を持ちます。
このメールは重要です。スパムではありません。 このメールはスパムです。重要ではありません。
しかし、ナイーブベイズでは単語の出現回数だけ見るので同じ文章として扱ってしまいます。そこで単語の並び順序=系列情報を利用するためにRNNを用いるわけです。
前述の説明では、「RNNはアウトプットとして次の単語を予測する」というものでしたが、分類の問題では系列全体のアウトプット(正確には隠れ層の状態)をまとめて1つのベクトルを作り、それをクラスラベルに近づけることで分類を行います。
RNNを用いた文書分類については『Recurrent convolutional neural networks for text classification』で詳しく説明されています。
chainerでの実装
冒頭で述べたように、今日ではDeep Learningに関するライブラリなどが充実しているため、比較的手軽に実装して試すことができます。
今回紹介するプロジェクトではPythonのニューラルネットワークライブラリである「chainer」を利用しています。
chainerの利点として、直感的にネットワークを書ける点、比較的多くのネットワークをサポートしている点があると筆者は考えています。例えば2層のFeedforward Neural Networkを作成する場合は以下のコードを書くだけでモデルを定義できます(図5)。

RNNのような少し複雑なネットワークも、これを元にして少し書き換えるだけで実装できます。
具体的には以下のようになります(図6)。

chainerでRNN(LSTM)を実装する際に参考となるのが、「ptbサンプル」です。
ぜひ、ptbサンプルを実際に動かしてみて「RNNがどういう学習をして、どういう予測を返すのか」を体感してみてください。筆者自身もこのプロジェクトをやり始めたころは、RNNについての知識はなかったのですが、実際にサンプルコードを動かすことで概要をつかむことができました。
次回から、RNNによる誤字脱字検知を具体的に
次回からは、具体的にこのRNNをどのように活用して誤字脱字を検知しているかについて述べていきます。
筆者紹介
高橋 諒(たかはし りょう)
リクルートテクノロジーズ ITソリューション統括部 ビッグデータ部所属
2015年入社。主にリクルートが抱えるサービスの行動ログ分析とエンハンス開発を行っている。その一方でR&Dとして、文書解析を用いた社内向けAPIサービスの開発推進を積極的に行っている。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか。GPUコンピューティングを推進するNVIDIAが、これらの違いを背景および技術的要素で解説した。 AlpacaDBがDeep Learningを使った自動取引アプリを公開
AlpacaDBがDeep Learningを使った自動取引アプリを公開
米AlpacaDBは、為替市場での自動取引アルゴリズムを設計できるiPhone向けモバイルアプリ「Capitalico(キャピタリコ)」の提供を開始した。 2015年に大ブレイクした「Deep Learning」「ニューラルネットワーク」を開発現場視点で解説した無料の電子書籍
2015年に大ブレイクした「Deep Learning」「ニューラルネットワーク」を開発現場視点で解説した無料の電子書籍
人気連載を1冊にまとめてダウンロードできる@ITの電子書籍。第16弾は、「いまさら聞けないDeep Learning超入門」だ。