レビュー効果はそのままに、時間と手間を大幅削減する方法:レビューがうまくいかない理由(2)(3/4 ページ)
レビューには時間がかかるものというイメージがある。しかし案外省略できる部分は多い。レビューの無駄取りの方法を紹介する。
レビューでの検出を省略したり、確認箇所を減らしたりする方法
重視すべきことを見直すことで、「検出シナリオ」そのものを省略する
まず、レビューでの検出を省略できないか吟味します。具体的には、重視すべきことを見直すことで、「この手の欠陥や問題をレビューで検出するのはやめよう」と言えそうな欠陥や問題を探すのです。
言い換えると、必要の薄いレビュー観点を省略するということです。その際に、「これを確認するのは時間がかかるからやめよう」「めんどうだからやめよう」という考え方で省略すると単なる手抜きになります。レビューの手抜きはテストをはじめ、後の開発作業での手戻りにつながり、結果として余計に時間がかかったり作業が増えたりします。
ここでは、そうした例を比較的分かりやすく説明するために、レビューで検出する欠陥や問題を見つけるための方針を説明した「検出シナリオ」を用いて説明しましょう。検出シナリオとは「レビューで何をどのように確認するか」を記述したものです(ただし、検出を省略するためには、まず検出シナリオを考えなければいけないという意味ではありません。検出シナリオの詳細はレビューで失敗しない8つのポイント (3/4)や“読み方”を知って、レビューをもっと効果的に(3/4)を参照してください)。
以下が例です。これまでは、「システムやソフトウェアの構成要素に新技術を活用したときに、下のような検出シナリオで問題がないかを確認していた」とします。
従来の検出シナリオ
システムやソフトウェアの構成要素に、これまで使ったことがない技術を活用する場合、その構成要素が期待通り動作しなかったときの影響範囲を調べる。まず、他の構成要素とのデータの受け渡しを調べ、データの依存関係による影響を調べる。次に、実行順序を調べ制御の依存関係による影響を明らかにする。この2種類の影響を踏まえて、これまでになかった新たな影響範囲が生じていないかを確かめる。
しかし、例えば以下のような事情があったとしたらどうでしょう?
- プロジェクトファイルの共有用に、クラウド事業者が提供するネットワークファイルシステムを使うことになった。
- クラウド事業者が提供するネットワークファイルシステムはこれまで使った実績がない。クラウド事業者のサービスは不定期にアップデートされる。
こうした場合、従来の検出シナリオのように逐一問題を検出することが、必ずしも不可欠だとは言い切れません。
これを受けて、「もちろん、利用するサービス自体の評価や検証は実施するが、アップデートされるたびに、従来のように影響範囲を1つ1つ調べていては求められるスピードに対応できない」と判断すれば、この検出シナリオを省略した方が合理的だということになります。つまり、メリットとコストを勘案して「何を重視するか」を考えることで、省略できる検出シナリオを発見できるわけです。
重視すべきことを見直すことで、確認する箇所を絞ってみる
検出シナリオ自体を省略できなくても、「確認する箇所を減らせないか吟味する」アプローチもあります。同様に、例で説明しましょう。まずは変更前の検出シナリオを見てみましょう。
従来の検出シナリオ
- オペレーターの問い合わせ実行画面と結果表示画面を確認し、実行されるSQL問い合わせを想定する。
- 問い合わせにより、データベースの負荷が大きくなるデータ項目のうち、「必ずしも同一の結果表示画面に表示する必要のないデータ項目」がないか確認する。
- 「結果をソートしなくても支障のないデータ項目」をソートしようとして、負荷を大きくしていないか確認する。
- 3つ以上のテーブルへの問い合わせの結果を表示する画面の場合、問い合わせ実行画面や結果表示画面を2画面以上に分割することで、問い合わせ対象のテーブル数を減らすことができないか確認する。
以上のように、現行システムでは、データベースへのアクセス集中を低減するために、「オペレーターが使う問い合わせ画面」からのデータベースへのアクセスが過度に増えていないか、画面仕様書の各画面の情報を使ってレビューで確認することとしています。
現状、問い合わせ画面は20画面ほどありますが、まずはこのうち「アクセスが集中する時間帯に使われる画面」をより分けることで、確認箇所を減らすことを考えてみます。データベースへのアクセスが集中する時間帯は日次の締めの時間帯と、月次の締め日の13時以降であり、「アクセスが集中する時間帯に使われる画面」は限られているからです。
次に、「3つ以上のテーブルへの問い合わせ」がデータベースのスループットに影響を与える可能性があるため、そうした問い合わせを減らせないか、確認しています。
しかし「同時に3つ以上のテーブルに問い合わせをする」場合でも、テーブルのレコード数が小さければ影響は少ないわけです。そこで、「レコード数の小さいテーブル」はレビュー対象から省き、「テーブルのレコード数が1万件以上あり、3テーブル以上に同時に問い合わせをする場合」に限って確認しようと考えてみます。これら2つにより、レビューで確認する箇所を減らすことができます。
では、減らした後の検出シナリオを見てみましょう。変更した部分をグレーの背景で示しています。
確認箇所を絞り込んだ検出シナリオ
- オペレーターの問い合わせ実行画面と結果表示画面を確認し、実行されるSQL問い合わせを想定する。
- 「アクセスが集中する時間帯がある画面」のみをレビュー対象とする(日次の締め時間帯と月次の締め日の13時以降)。
- 問い合わせにより、データベースの負荷が大きくなるデータ項目のうち、「必ずしも同一の結果表示画面に表示する必要のないデータ項目」がないか確認する。
- 「結果をソートしなくても支障のないデータ項目」をソートしようとして負荷を大きくしていないか確認する。
- 「レコード数が1万件を超えているテーブル3つ以上へ問い合わせを実行する画面」がないかを確認し、ある場合には、問い合わせ実行画面や結果表示画面を2画面以上に分割することで、問い合わせ対象のテーブル数を減らすことができないか確認する。
いかがでしょう。確認の必要性が低いものを省くことで、レビューでの作業が減ることが分かるのではないでしょうか。
では次に、より具体的なイメージを持っていただくために、「検出シナリオを省略する」「検出シナリオのうち、確認すべき個所を省略する」という以上2つのアプローチを、現実にありそうな事例を使って説明しましょう。
検出シナリオや確認箇所を省略する、より具体的な例
ではまず、事例とするシステムについて簡単に説明しましょう。
システムと前提
システムは、前日の販売実績(と在庫情報)から、翌日の発注や生産指示を出すためにA社グループが使っているシステムです。日次で商品の販売実績を収集し、翌日に仕入れ先に発注する商品と、その数を決める判断材料としています。日次の実績は19時で締めています。
A社グループはここ2年で、B社グループ、C社グループと経営統合しました。システム統合はまだ完了しておらず、A、B、C社グループ、それぞれがもともと使っていた販売実績収集システムにそれぞれ情報を集約し、3つのシステムから情報を集めることで集計しています(図3)。
今後は、さらに他の会社も統合する可能性があるため、A、B、C社グループのシステム統合は5年後以降を予定しています。旧A社、旧B社、旧C社のシステムから実績を収集するシステムも、少なくとも5年間は必要に応じて改修しながら使い続けることとしています。ただし、集計、分析サーバについては5年後の更改後も使い続けることとしています。
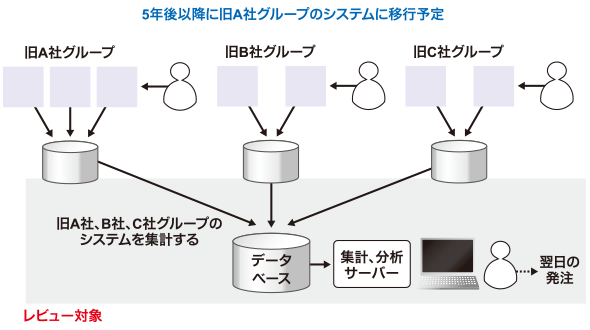
レビューは、この「3社のシステムから実績を集計するシステム」のインフラを対象としています。
その検出シナリオの一部が表1です。これはA社グループの標準的な検出シナリオの一部であり、A社グループの旧サブシステムでもこの検出シナリオを使っています。これまでのシステム更改の際も、この検出シナリオに沿って設計レビューをしてきました。
| ID | 分類 | 検出シナリオ |
|---|---|---|
| 1 | 拡張性 | 集計結果のレコードが現行の10倍に増えたときでも一括集計に関わるソフトウェアに大きな変更を加えず対応できるか調べる。現行の集計、分析サーバーの機能一覧と対応するSQLクエリのリストを使ってチェックする。 |
| 2 | 拡張性 | データベースのテーブルのデータ型やカラムを変更する際にドキュメント変更、プログラム変更、テストを含め10日程度で変更できるか調べる。ID長の拡張、列挙型の追加、新たな正規化の必要が出てきた場合を想定し、データベースのマイグレーションにおいてシーケンス番号の振り直しや商品コードの変更といった稼働中のデータの変換や移行作業は土日で完了できるか調べる。 |
| 3 | 保守性 | ソースコードの流用、変更時のデグレード防止を目的として、ソースコードモジュールの間で依存度合い(結合度)が小さくなっているか確かめる。 |
| 4 | 移植性 | DBMSや通信ミドルウェアが変更になった場合でも、大きな変更なく移行できるか調べる。ソースコードを調べ、データベース、他のシステムとの通信部分が新たに増えていないか、すでにある通信部分が現行DBMSの固有の機能や通信ミドルウェアに特化した形式になってしまわないか調べる。 |
| 5 | 障害回復 | 集計の途中で旧A社、旧B社、旧C社のシステムのいずれかに障害が起き復帰した場合に、最初のデータから集計し直すのではなく、障害が起きた直前のデータから集計できる方法となっているか調べる。旧A社、B社、C社のシステムに指定した位置からのデータを要求できるか、集計がどこまで終わったかを内部状態として保持する仕組みがあり1件集計するごとに更新されるか調べる。 |
| 6 | 問題切り分け | 性能低下が起こったときに、どの社のシステムのどの拠点からのデータが原因となっているか1日程度で切り分けることができるか切り分けの手順とともに確認する。 |
さて、では以上をどう効率化すれば良いのでしょうか? その1つの解答例が以下です。
| ID | タイプ | 変更内容と理由 |
|---|---|---|
| 1 | 検出シナリオ自体を省略 | 5年以内にレコードが10倍になる可能性は低いので、システム統合までの5年間はこのシナリオでの欠陥検出はしない。 |
| 2 | 検出シナリオ自体を省略 | 新たな企業を経営統合する可能性があり、統合相手のテーブル定義やデータ項目を予想するのは難しい。システム統合までの5年間はこのシナリオでの欠陥や問題の検出はしない。 |
| 3 | 確認箇所を絞り込み | 確認する箇所を集計、分析サーバの部分のみにして、それ以外の箇所を省略する。5年後のシステム統合後も集計、分析サーバは使うため。「集計、分析サーバのソースコードの流用、変更時のデグレード防止を目的として、ソースコードモジュールの間で依存度合い(結合度)が小さくなっているか確かめる。」と変更する。 |
| 4 | 確認箇所を絞り込み | 確認箇所を集計、分析サーバの部分のみにし、「集計、分析サーバが使うDBMSや通信ミドルウェアが変更になった場合でも、大きな変更なく移行できるか調べる。ソースコードを調べ、データベース、他のシステムとの通信部分が新たに増えていないか、すでにある通信部分が現行のDBMSの固有の機能や通信ミドルウェアに特化した形式になってしまわないか調べる」と変更する。 |
| 5 | 継続 | システム統合までの5年間においても障害は起こる可能性があるため継続とする。 |
| 6 | 継続 | システム統合までの5年間においても性能低下は起こる可能性があるため継続とする。過去にシステムの性能低下が起き原因究明に時間がかかり、業務に大きな支障を及ぼしたため。 |
いかがでしょうか? この他にも、「レビューのコストを考えなければ確認した方がよいが、コストを踏まえると必ずしもレビューする必要のない」検出シナリオ、確認箇所があるはずです。
どのようなソフトウェアにも通用する万能なレビューチェックリストがないように、どのようなレビューにも共通して優先順位の低い検出シナリオ、確認箇所はありません。そのため、対象ソフトウェア、求められる品質、かけられるコストといった点を加味して、レビュー対象の優先順位を決める必要があります。
より具体的には、「5年で再構築する」といった場合はもちろんですが、「これはテストでも検出できる」「ここをがんばってレビューしても得られる効果は薄い」といった判断をしてレビュー対象に優先順位を付け、優先順位の低い検出シナリオ、確認箇所を省くのです(優先順位を決める際には、「レビューを「数」だけで管理しているからコストが膨らむ」が参考になると思います)。
ここまでが「欠陥検出における効率化」の方法です。次に、「レビュー会議の効率化」に向けて、効果を維持したまま会議の時間を短くする方法を紹介します。
Copyright © ITmedia, Inc. All Rights Reserved.