簡単なサーバレスアプリ構築で分かるAWS Lambdaの実装方法の基本:AWS Lambdaで始めるサーバレスアーキテクチャ入門(2)(1/2 ページ)
システム開発の常識を覆す「サーバレスアーキテクチャ」について「AWS Lambda」を使って構築方法を学ぶ連載。今回は、サンプルとなるサーバレスアプリケーションの構築を例にAWS Lambdaの実装方法の基本を解説します。
システム開発の常識を覆す「サーバレスアーキテクチャ」について「AWS Lambda」を使って構築方法を学ぶ本連載「AWS Lambdaで始めるサーバレスアーキテクチャ入門」。前回の「アプリ開発者もインフラ管理者も知っておきたいサーバレスとAWS Lambdaの基礎知識」ではサーバレスアーキテクチャのコンセプトや特徴、そしてAWS Lambdaの概要を紹介しました。
今回は、サンプルとなるサーバレスアプリケーションの構築を例にAWS Lambdaの実装方法の基本を解説します。
簡単なサーバレスアプリケーションを作ってみよう
今回は、Amazon S3 バケット(以下、S3 Bucket)にコンテンツをアップロードすると、自動で別のS3 Bucketにコピーするという簡単なサーバレスアプリケーションを構築します。処理の流れは以下の通りです。
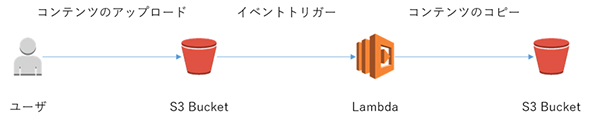
- ユーザーがS3 Bucketにコンテンツをアップロードする
- コンテンツアップロードをトリガーに Lambda関数が実行される
- 別のS3 Bucketにコンテンツが自動でコピーされる
それでは、実際にサーバレスアプリケーションを作っていきましょう。構築は以下の流れで行います。
S3 Bucketの作成
まずは、AWSのマネジメントコンソールにサインインし、適当な名前で2つのS3 Bucketを作成してください。ここではコンテンツアップロード用の「sample-upload-bucket」とコンテンツコピー先の「sample-copy-bucket」を東京リージョンに作成しました。以降の手順では、S3 Bucketの名前は適宜置き換えてください。
IAMロールの作成
続いて、Lambda関数で利用するIAMロールを作成します。ロールタイプはAWSサービスロールの中から「AWS Lambda」を選択します。

ポリシーには以下2つの権限を付与します。
- AWSLambdaBasicExecutionRole
- AmazonS3FullAccess
ここでは「sample-lambda-role」という名前でIAMロールを作成しました。
Lambda関数の作成
続いて、S3 Bucketにアップロードされたコンテンツを別のS3 BucketへとコピーするLambda関数を作成します。AWS Lambdaのコンソールを開いてください。Lambda関数を作成したことがない方は、「今すぐ始める」というボタンが表示されているのでクリックします。

既にLambda関数を作成したことがある方は、「Lambda関数の作成」をクリックします。すると設計図の選択画面が表示されますが、今回blueprintは利用せずブランク関数として作成します。

トリガーの設定はAmazon S3から実施するので「次へ」をクリックします。

関数の設定画面が表示されるので、まずはLambda関数に名前を付け説明書きを入力します。ここでは「sample-lambda」としました。また、利用する言語は「Node.js 6.10」とします。

コードについては、今回は外部モジュールを利用しないのでインラインエディタで編集していきます。以下のコードをコピー&ペーストしてください。その際、変数copyBucketの値は、S3 Bucketの作成で準備したコピー先のS3 Bucketへと修正してください。
'use strict';
// AWS SDK モジュールの読み込み
const aws = require('aws-sdk');
const s3 = new aws.S3();
exports.handler = function(event, context) {
console.log('Received event:', JSON.stringify(event, null, 2));
// アップロードされたS3 Bucketの名前とコンテンツのパスを取得
const uploadBucket = event.Records[0].s3.bucket.name;
const key = event.Records[0].s3.object.key;
// getObject APIを使用してS3のコンテンツを取得
const params = {
Bucket: uploadBucket,
Key: key
};
s3.getObject(params, function(err, data) {
if (err) {
console.log(err, err.stack);
context.done(err, err.stack);
} else {
console.log('data: ', data);
// コピー先のS3 Bucketの名前を定義してアップロード
const copyBucket = 'sample-copy-bucket';
const params = {
Bucket: copyBucket,
Key: key,
Body: data.Body
};
s3.putObject(params, function(err, data) {
if (err) {
console.log(err, err.stack);
context.done(err, err.stack);
} else {
console.log('data: ', data);
context.succeed('complete!');
}
});
}
});
};
今回利用するコードを簡単に解説します。Lambda関数実行時に受け取るeventパラメータの中に、S3 Bucketの情報やアップロードされたコンテンツの情報がJSONデータとして詰まっています。変数uploadBucketにS3 Bucketの名前を、変数keyにコンテンツのパスをセットし、Amazon S3のAPI(getObject)を使用して実際のコンテンツを取得しています。
取得したコンテンツを、変数copyBucketで定義したS3 Bucketに書き込みます。コンテンツ書き込みの際にも、Amazon S3のAPI(putObject)を使用します。コンテンツをアップロードするS3 Bucketとコピー先のS3 Bucketを同じにしてしまうと、コンテンツのコピーが無限に実行されるので、必ずS3 Bucketは別々としてください。
コード内のhandlerがLambda関数ハンドラとなります。ここではデフォルト(index.handler)のままとします。
続いて、Lambda関数の実行時に利用するIAMロールを設定します。プルダウンから、先ほど作成したIAMロールを選択してください。

詳細設定を開きメモリとタイムアウトをそれぞれ設定します。メモリはデフォルトの128MBで十分だと思います。タイムアウトはLambda関数の処理時間に余裕を持たせるため10秒とします。

「次へ」をクリックし、確認画面で「関数の作成」をクリックしたら、Lambda関数の作成が終了です。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 AWS Lambdaの実現するイベントドリブンなプログラミングが、IoTへの扉を開く
AWS Lambdaの実現するイベントドリブンなプログラミングが、IoTへの扉を開く
米Amazon Web Servicesは、IoTアプリケーションの今後をどう描き、開発者にどのように構築してもらいたいのか。同社でモバイルとIoTを統括するモバイル担当副社長、マルコ・アルジェンティ氏へのインタビューの前編をお届けする。 米マイクロソフト、AWS Lambda的なサービス「Azure Functions」を発表
米マイクロソフト、AWS Lambda的なサービス「Azure Functions」を発表
米マイクロソフトは2016年3月31日(米国時間)、AWS Lambda、Google Cloud Functionsと同様なイベントドリブン、サーバレスなコンピュートサービス、「Azure Functions」を発表した。同社はさらに、Azure Functions関連コードをオープンソースとして公開するため、Azure以外のプラットフォームでも動かせる。 米IBMがAWS Lambda的なサービスOpenWhiskを発表、オープンソース提供も
米IBMがAWS Lambda的なサービスOpenWhiskを発表、オープンソース提供も
米IBMは2016年2月22日(米国時間)、AWS Lambdaに似たイベントドリブンなプログラミングサービス「Bluemix OpenWhisk」を発表した。同時にこれを、Apache 2.0ライセンスに基づくオープンソースコードとして公開。同社は特徴として、オープン性とエコシステムの展開を強調している。