なぜ人工知能研究でNVIDIAのGPUが使われるのか――安くて速いGeForceが尊ばれる理由:ものになるモノ、ならないモノ(76)
最近、人工知能(AI)の研究開発における「計算」の分野でGPUメーカーNVIDIAの名前を見掛ける機会が増えた。グラフィックの表示を行うGPUが、なぜAI研究の計算で活躍するのかを、AIについてズブの素人である筆者が、超初心者目線で取材し、調べ、まとめた。

自作PC派にとってなじみ深い「NVIDIA」のロゴ。ビデオカード(GPU)のドライバをインストールする際に目にした人は多いはずだ。そんなNVIDIAの名前を意外なところで見掛ける機会が増えた。2017年5月、日本経済新聞は、「トヨタの自動運転、米エヌビディア提携で開発加速」と報じた。GPUのメーカーが「なぜ、トヨタと提携?」と不思議だった。
調べてみると、Ford Motor、Volvo Car、Mercedes-Benz、Audi、Teslaなど、名だたる自動車メーカーと自動運転研究の分野で提携済みであり、その後も、Robert Bosch、ZF Friedrichshafen、Continentalといった大手自動車部品メーカーと提携を加速させている。NVIDIAのパートナー紹介サイトには、多くのグローバル企業のロゴが誇らしげに並んでいる。筆者は、恥ずかしながら“ある分野”におけるNVIDIAの活躍をそれまで知らなかった。
その“ある分野”とは、人工知能(AI)の研究開発における「計算」である。グラフィックの表示を行うGPUが、なぜAI研究の計算で活躍するのかを、AIについてズブの素人である筆者が、超初心者目線で取材し、調べ、まとめたのが本コラムである。その過程でなるほど、NVIDIA躍進の理由が理解できた気がした。
NVIDIA躍進の理由について端的には「高速なグラフィック処理を必要とする3Dゲームの分野で鍛え、そして、磨かれ、高性能に進化したGPUの汎用計算処理の能力に、機械学習や深層学習(ディープラーニング)の研究者が着目し、利用し始めた」ということである。
機械学習やディープラーニングの研究には膨大な計算機パワーが必要なのは有名だが、数万円から10万円程度で購入できるビデオカードが使えることで、研究が急速に進んだ側面もある。「AIの研究にはお高いスパコン(スーパーコンピュータ)が必要不可欠なんでしょ?」と漫然と考えていただけに、秋葉原で普通に売られているGPUのボードが活躍しているとは目からウロコだったのだ。

AIによる完全自動運転の未来は近い
冒頭でNVIDIAと自動車メーカーの提携を紹介したが、AIと自動運転の関係について触れておこう。自動運転の実現にはAIの搭載が不可欠だという。ドライバーは、運転中、常に次に起きることについて、さまざまな予測を行っている。例えば、交差点に差し掛かろうとしたときに歩行者の青信号が点滅していれば、自動車用信号も間もなく黄色から赤色になると「予測」する。そして、止まるかそのまま通過するかの「判断」を行う。この「予測」して「判断」する能力は、自動車の運行には欠かせないものであり、これをコンピュータで行うには、高度なセンサーと複雑なプログラムが必要で、その延長線上にAIがあるのだろう。
筆者は、つい先ごろ、自動運転のようで自動運転ではないクルマを運転する機会を得た。正確には「準自動運転走行システム(加速、操舵、制動のうち複数の操作をシステムが行う状態)」(レベル2の自動運転)というらしいが、カーブに差し掛かるとハンドルが自動で切れるし、信号や渋滞で前のクルマが停車すると自動で止まる。
「これって自動運転じゃん!」と興奮したものの、ハンドルから手を離すとディスプレイに「ハンドルから手を離すな」的な注意喚起のアラートが表示され、それを無視していると徐々に速度が低下する。また、前車を追従していない状態だと、赤信号になっても自動では止まってくれない。なるほど、「準」である理由がよく理解できた。
筆者が運転したクルマは、センサー類(レーダーやカメラ)からの情報に対し、あくまでも「あらかじめプログラムされた制御を行っているだけ」という印象だった。センサー類から吸い上げられた情報に意味付けをした上で、「予測」と「判断」を繰り返しながらクルマを「運転」しているように感じられなかった。それを実現するために、さらに高度なプログラム=AIが必要なのであろうことは理解できた。だが、現時点でここまでの運転支援が可能になっているのであれば、「AIによる完全自動運転の未来は近い」と感じたのも事実だ。完全自動運転の実現に自動車系の企業が、ITの大手とタッグを組みたがって当然だと思う。

ハンドルから手を離すとメーター中央のディスプレイに「ハンドルに手を添えろ」を意味するグラフィックが表示される。Mercedes-Benzの「C200」という車種で複数のミリ波レーダーと2つのカメラで周囲の状況を捉え半自動運転を実現している
それは日本の長崎から始まった
話をGPUに戻そう。さかのぼること10年余、2007年春ごろ、GPUの高性能化に着目し、汎用計算処理に利用しようとした日本人がいる。長崎大学の濱田剛准教授である。NVIDIAのGeForce 8800GTXをクラスタ化することで、低予算でスパコン並みの計算資源の構築を実現しようというプロジェクトが始まった。このプロジェクトは後に「DEGIMA」(長崎の出島)と命名される。
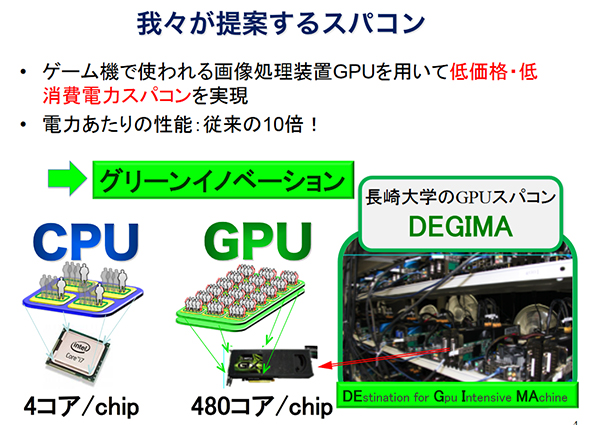
DEGIMAプロジェクトは、GPUの台数を増強するなど段階を追って進化した。本来なら数十億、数千億規模の予算が投じられる国家的事業のスパコンに匹敵するコンピュータを3800万円で構築したことが話題となり、ニュースなどでも取り上げられ、その名が知られるようになった。以下、DEGIMAプロジェクトにおける導入機種と台数である。
- 2007年春:GeForce 8800GTXでプロトタイピング
- 2008年春:GeForce 9800GTX×128基で構築
- 2009年春:GeForce 9800GTX×256基で構築
- 2009年秋:GeForce GTX 295×380基で構築(このとき初めてDEGIMAと命名される)
『単精度190Tflops GPUクラスタ(長崎大)の紹介』(PDF)という濱田准教授のプレゼン資料もあるので、ご覧いただきたい。資料12ページのむき出しの状態でラックにPCのボードがたくさん並んだ写真は、手作り感満載で圧巻である。キャプションには、「1人で1週間もあれば組み立て可能」と説明されている。まさに自作PC感覚である。
このDEGIMAプロジェクトに触発され、機械学習の研究にGPUを導入する研究者が増加した。今では、「安く」て「速い」GPUなしには、ディープラーニングの研究は成り立たないと言っても過言ではない。
2018年4月にも本格稼働が予定されている産業技術総合研究所(経済産業省所管)の「AI橋渡しクラウド(ABCI)」は、世界有数のAI研究の計算基盤として研究者たちの関心を集めている。千葉県柏市の東京大学キャンパス内のデータセンターに設置されるABCIには、4基の「NVIDIA Tesla V100」を搭載した1088台のサーバが稼働し合計4352基のNVIDIAのGPUボードが日本のディープラーニングの研究をリードすることになる。
このコンピュータは富士通が受注したという。詳細は、富士通発表のリリースを参照されたし。
ちなみに「Tesla」は、NVIDIAの産業分野向けのGPUで、GeForceの上位機種との比較で約10倍のプライスタグ(百十数万円程度)が付けられている。コンシューマー用途のGeForceに比べ、倍精度浮動小数点計算(詳細は後述)に対応するなど、信頼性が高いことが特徴であり、NVIDIA自身、データセンターなどの業務利用には、Teslaの導入を推進している。
勝因は、汎用計算向けのソフトウェア環境の整備
ここで、1つの疑問にぶち当たる。なぜ、AI研究の分野ではNVIDIAのGPUばかりが注目されるのであろうか。一説には、「ほぼ独り勝ち」だという。GPUには、AMDという有名なライバルメーカーも存在する。PCのビデオカード分野では、「AMD Radeon」もGeForceに負けない性能を誇り同様にコスパも高い。ちなみに、Radeonは、ATI Technologiesの製品だったが、2006年にAMDに買収されATIブランドは消滅した。
NVIDIA圧勝の理由の1つにソフトウェア環境の整備が挙げられる。GPUをゲーム分野だけではなく、汎用計算にも使えるようにと、2006年に「CUDA(Compute Unified Device Architecture:クーダ)」と呼ばれる統合開発環境を発表した。GPUというハードウェアだけではなく、汎用計算向けの開発環境を早くから提供したことで、現在の躍進がある。先見の明があったということだろうか。
卑近なケースに例えると、iPhoneとiOSアプリの関係にも似ている。Appleは、iPhoneというハードを売るだけではなく、Xcodeという開発環境を世界中の開発者のために無料で提供した。それにより多くの開発者がiPhone向けアプリ分野に参入。たくさんのアプリが登場することで、ハードウェアとしてのiPhoneの魅力を高める一助となっている。ハードウェアとソフトウェアの相乗効果によるエコシステムを築き上げることに成功したわけだ。
NVIDIAのCUDAにも同様のことがいえるだろう。ライバルのAMDは、この部分で出遅れてしまった。あるデータセンター技術者は筆者に「AMDの技術力が劣っているわけではない。将来を見据えた戦略を早い段階から立てて、着実に実行したNVIDIAは立派だと思う」と耳打ちする。
安くて速いGeForceが尊ばれる理由
先ほど、「倍精度浮動小数点」など普段使い慣れない言葉を用いてしまい、文系印象派である筆者としては、幾分後悔しているのだが、「使った以上は解説せねばなるまい」ということで筆者なりに「GPU」という視点から、この専門用語をそしゃくする。ただし計算式は出てこないので、あしからず。
「倍精度浮動小数点(倍精度)とは、コンピュータが計算を実行する際の方式(ルール)の1つです。以上終わり」なんて書き方をすると「ばかにしているのか!」と怒られそうだが、この方式がどのような分野で用いられているのか、大枠での理解を得るべく調べてみた。
倍精度とは、スパコンを利用して実施するような科学技術計算に向いた計算方式だ。科学技術計算というのは、天体の重力干渉、流体シミュレーション、気象予測といった用途における計算の総称である。なるほど、これらの用途を見ると、さまざまな物理現象からもたらされる膨大な数値を扱わなければならないことは想像に難くない。つまり、相対的に「大きな桁数を扱う」ことに向いているということは素人にも想像できる。
これは余談だが、近年、天気予報の的中率が向上したのは、スパコンの進化によるところが大きい。今では、全球の大気のシミュレーションを行うことで、高い精度を実現している。「天気予報の歴史はコンピュータの歴史である」ともいえるそうだ。
「倍」=ダブルがあるならシングルもあるのだろうか。あります。「単精度浮動小数点(単精度)」という計算方式も存在する。こちらは、3Dゲームの3次元の描画処理に利用されている。GeForceシリーズなどは、まさにこのために存在するGPUであり、「単精度」での利用を意識した製品といえる。
さて、ここで、機械学習やディープラーニングの登場である。機械学習では「桁数が小さいほど計算の効率を上げることができる」(研究者)という意見もある。つまり、「倍精度より単精度」というわけだ。速くて安価な上に、単精度による演算処理を意識したGeForceが尊ばれる理由がここにある。
「単」と「倍」の両方に対応した産業分野向けのオールマイティー型GPU「Tesla」でも機械学習やディープラーニング利用は可能なのだが、「AI研究者にとって、Teslaはオーバースペック」(研究者)であり、何にも増してGeForceの方が10分の1のコストで済むことの意味は大きい。
また、機械学習の研究では、あらゆる仮説を立て、多くのコンピュータを同時並行で走らせて処理を行うことで、自分がたどり着きたい答えに早く到達できる可能性が高くなるそうだ。そうなると、学術研究の世界では「1台のTeslaよりも10台のGeForce」という話になり、同じNVIDIAのGPUの中でも、GeForceの導入が進む結果となった。
ただ、近年は、科学技術計算の世界でも「単精度」を活用する動きと、ディープラーニングの研究手法を科学・工学分野の研究にも活用する流れが同時並行で起きており、前出のABCIのスパコンはAI研究の計算基盤とはいうものの「単精度」と「倍精度」の両方の性能を重視した要件で構築されている。「倍単両にらみ」といったところだ。
筆者のオフィスでは、いまだに10年前に購入したMac Proが現役で動作している。このレガシーなマシンには、「NVIDIA GeForce GT 120 Graphics Upgrade Kit for Mac Pro(early 2009)」というビデオカードが搭載されている。「512MBメモリ搭載」と、今となっては鼻で笑われるようなスペックなのだが、このような市中で普通に購入できるPCのパーツが、近未来のAI生活を実現するための研究に使われているかと思うと、ちょっとだけ幸せな気分になるではないか。
著者紹介
山崎潤一郎
音楽制作業を営む傍らIT分野のライターとしても活動。クラシック音楽やワールドミュージックといったジャンルを中心に、多数のアルバム制作に携わり、自身がプロデュースしたアルバムが音楽配信ランキングの上位に入ることもめずらしくない。ITライターとしては、講談社、KADOKAWA、ソフトバンククリエイティブといった大手出版社から多数の著書を上梓している。また、鍵盤楽器アプリ「Super Manetron」「Pocket Organ C3B3」などの開発者であると同時に演奏者でもあり、楽器アプリ奏者としてテレビ出演の経験もある。音楽趣味はプログレ。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 NVIDIAとGoogle、「TensorRT」と「TensorFlow 1.7」を統合
NVIDIAとGoogle、「TensorRT」と「TensorFlow 1.7」を統合
「NVIDIA TensorRT」とオープンソースソフトウェアの機械学習ライブラリの最新版「TensorFlow 1.7」が統合され、ディープラーニングの推論アプリケーションがGPUで実行しやすくなった。 NVIDIAとArmがディープラーニングで提携――NVDLAをProject Trilliumに適用へ
NVIDIAとArmがディープラーニングで提携――NVDLAをProject Trilliumに適用へ
NVIDIAとArmは、モバイル機器やIoT機器などへのディープラーニング導入に向けて提携し、NVIDIA Deep Learning AcceleratorをArmのProject Trilliumに適用すると発表した。両社は、「IoTチップ企業による自社製品へのAI導入を容易にする」としている。 NVIDIA、AI自動運転プラットフォーム「NVIDIA DRIVE」の機能安全技術の詳細を発表
NVIDIA、AI自動運転プラットフォーム「NVIDIA DRIVE」の機能安全技術の詳細を発表
NVIDIAは、AI自動運転車プラットフォーム「NVIDIA DRIVE」の機能安全アーキテクチャの詳細を発表した。オペレーター、環境、システム関連の問題発生時も、車両の安全稼働を実現するとしている。