どのようなデータ基盤を作ったのか? データ収集/蓄積/加工/活用、パイプライン管理の設計:開発現場に“データ文化”を浸透させる「データ基盤」大解剖(2)(3/3 ページ)
「ゼクシィ縁結び・恋結び」の開発現場において、筆者が実際に行ったことを題材として、「データ基盤」の構築事例を紹介する連載。今回は、データ基盤システムの構成要素や採用技術の選定理由などをお伝えします。
データ加工
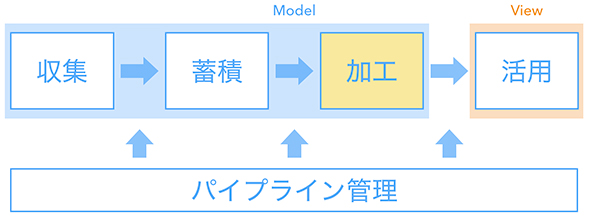
元データを集計・加工する処理です。売上や登録数、アクティブユーザー数などの指標を中間テーブルとして出力します。
これらのデータ処理はPythonスクリプトで簡易実装しました。Jupyter Notebookでデータの中身を確認しながらコーディングして、うまくいったものをPythonコードとして出力します。アプリケーション構成を最小限に済ませるため、フレームワークさえ利用していません。
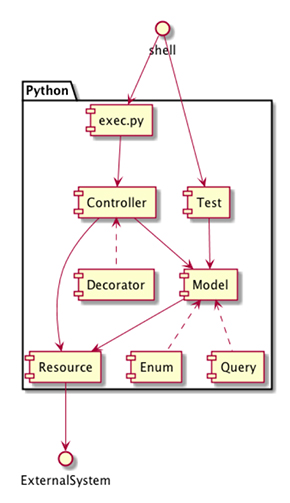
- exec.py
エンドポイントです。後述する「ワークフローエンジン」(パイプライン管理ツール)がexec.pyを呼び出すことで処理が始まります。シェル引数を基に「どの処理を実行するか」を動的に振り分けます。ジョブの並列実行やリトライ、そしてテストを行いやすいように処理はなるべく細分化しています。
- controller
処理ごとの全体像を記述します。「Facade」(窓口のこと:システム設計手法であるGoFデザインパターンの1つ)として他のコンポーネントの処理を呼び出します。
- model
ビジネス指標を表現します。中間テーブルと1対1で対応したクラスで、Create(データ作成)とRead(データ読み込み)をメソッドとして持ちます。値は全てBigQueryに持たせることでプログラム上ではデータの状態を管理しないようにしています。
- query
BiqQueryの読み書き内容となるSQLを管理します。複雑な加工処理をJupyter Notebook(Python)で模索したいきさつを受けて、発行するSQLをPythonで組み立てています。
- enum
データ固有のコード値を管理します。プロダクト本体がJavaを採用しているため、JavaのEnumをPythonに変換して利用しています。固有のコード値判別といった処理を共通の親クラスに置いています。
- resource
外部システムとの連携処理を扱います。例えば、BigQueryがエラーを返したときのリトライ処理はこのレイヤーで一元化しています。また、環境変数によってKPIレポートの出力先となるSlackチャンネルを本番/開発で切り替えるのもこのレイヤーです。
※decoratorについては後述の「データ活用」で、testについては次回の「開発プロセス」で言及します。
GoFデザインパターンをはじめとした古典的なシステム設計の手法、思想を参考にして構築しました。一般的なアプリケーションでデータを加工するのと役割は同じです。システム設計についても考え方は同じはずだと筆者は考えています。
データ活用
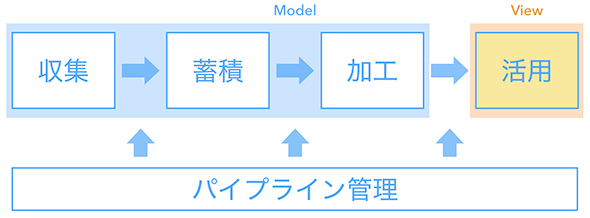
データの活用先は多岐にわたります。興味のある方はぜひ前回記事をご覧ください。

これらデータ活用施策を利用者観点で見て、Push型とPull型に分けて考えています。

Push型の例としてKPIモニタリングが挙げられます。データ基盤に必要なデータを収集できたら、そのまま押し出すように後続の処理を始めます。Pythonのジョブを実行してSlackにデイリーレポートを流したり、Google App Scriptを実行してSpreadSheetsに反映したりするといった具合です。
Pull型の例としてユーザー行動の可視化が挙げられます。アドホックなデータ分析をするときに、必要なタイミングで必要なデータを引っ張り出してもらいます。Jupyter NotebookやRedash、TableauといったツールからBigQueryにアクセスし、ユーザーの行動ログを取得します。その行動ログを基にサービス内の使い勝手が悪い箇所を特定して改善案を検討します。
システム観点では、特に以下の点に注意しています。
- Push型の処理はデータ基盤のパイプライン上に実装する必要がある
- Pull型の処理はデータ基盤のマイグレーション時に影響調査する必要がある
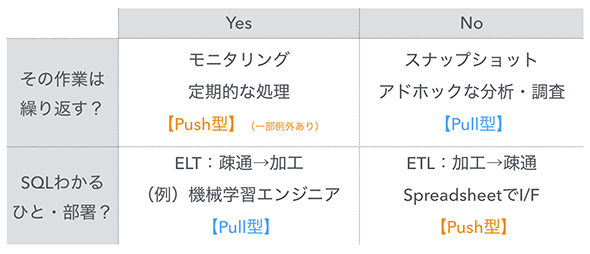
「データ活用のシステムをPush型とPull型のどちらで扱うか」は、その作業を繰り返すかどうか、担当者がSQLを書けるかどうかで判別しています。繰り返すなら自動化してPush型としてパイプラインに組み込みますし、単発の分析ならPull型で済ませます。担当者がSQLを書けなければPush型として加工済みデータを送りますし、SQLを書けるならPull型でデータに触ってもらいます。ある程度データ加工のパターンが見えてきたら、それをWarehouse層として中間テーブルで提供します。

Push型の処理については、Pythonスクリプトで専用のクラスを設けています。decoratorパターンで出力先のインタフェースに応じた変換処理の責務を持たせます。
例えば、毎朝Slackで売上グラフを表示していますが、これはmodel(中間テーブルと対応するクラス)で作った売上データを基に、decoratorにおいてMatplotlib(Pythonライブラリ)でグラフ描画し、resource(他システムとの連携に責務を持つ処理)でSlackのWeb APIをコールしています。
単にデータを1箇所に集めるだけでは「使われるデータ基盤」としては不十分ですが、PushとPullという運用におけるトリガーに注目することで、このような設計の勘所が見えてきました。
パイプライン管理
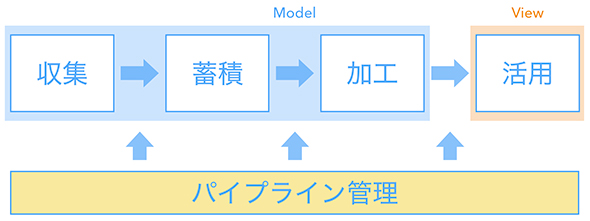
データの収集から活用までの流れを管理する仕組みです。ジョブAが終わったらジョブBを実行するといった形で一連の処理を定義します。ワークフローエンジン」とも呼ばれており、下記のようにさまざまなサービスが提供されています。あまりこの文脈で聞くことは少ないですがJP1(日立製作所)も該当するでしょう。
- Apache Airflow(元はAirbnb)
- Azkaban(LinkedIn)
- DigDag(TreasureData)
- Luigi(Spotify)
データパイプラインの管理において期待するのは以下のような機能です。
- 失敗した過去のジョブを一括でリトライ(backfil)したい
- ジョブ間の前後関係や並列処理(有向非巡回グラフ)を最適化したい
- サーバのオートスケールに対応させたい
- GUIとCUIの両方でログやパフォーマンスを確認したい
- 任意のプログラミング言語の処理を実行させたい
- ジョブの設定をソースコードとしてバージョン管理したい
全ての要求を満たせるのが理想ですが、サービスによって得手不得手もありますし、SaaS形式のサービスでなければ実行環境の構築や保守運用も必要になります。
「どのみち補助スクリプトを作るならば」と、初期構築時には筆者が使い慣れているJenkinsを採用しました。もともとはCIツールですが、パイプライン管理の機能が強化されており、ワークフローエンジンに近いことは実現できるためです。機能が弱い部分は自前で簡単なスクリプトを書いて補いました。Jenkinsジョブからシェル経由で各種処理をコールし、データの収集〜蓄積〜加工〜活用を実現しています。
技術要素の観点も含めて、システム面でこだわれる余地は多々ありますが、次回説明する「開発プロセス」を踏まえると、初期構築はこのくらいシンプルにしておいて良かったと思っています。「使われるデータ基盤」のためには、データの中身を1つ1つ綺麗にしたり、関係者一人一人のところへ足しげく通ったりと、他にもやるべきことがたくさんあるためです。
次回は、データ基盤における開発プロセスと文化醸成について
以上のようにしてデータ基盤と呼ばれる一連のシステム群を設計しました。実際にこのデータパイプラインを構築するに当たって開発プロセスが重要となります。次回は、データ基盤における開発プロセスと文化醸成についてお話しします。
※なお、今回紹介したデータ基盤はシステムを段階的に進化させていけるように構成し、一度構築した後も少しずつ手を入れています。今はPythonスクリプトなどの独自実装が減り、BigQueryと相性の良いGCPのソリューション群を活用する方向に切り替えています。
参考
筆者紹介
横山翔
リクルートテクノロジーズ プロダクトエンジニアリング部所属
途上国から限界集落まで各地放浪、ベンチャーキャピタルから投資を受けての起業や会社経営、リクルートグループ会社における複数の新規事業の立ち上げを経て、現職。
現在は急成長プロダクトを対象に、システムアーキテクチャの再構築やエンジニアチームの立ち上げ、立て直しに従事。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 ネット広告のデータ分析プロジェクトはどのように行われるのか
ネット広告のデータ分析プロジェクトはどのように行われるのか
広告宣伝費を各宣伝媒体へのコスト配分を調整することで効率化したいという事業部の課題に対してデータ分析のプロジェクトはどう進められるものなのか。筆者の経験を基に紹介する。 CVRをあと10%アップする、ビッグデータ分析とアダプティブUXの使い方
CVRをあと10%アップする、ビッグデータ分析とアダプティブUXの使い方
ABテストを利用したサイト改善の限界にぶつかっている人たちに向けて、リクルートグループ内で実践している改善ノウハウをお伝えする連載。今回は、中古車販売サイト「カーセンサー」を例に「検討フェーズ」を軸とした個別最適化やビッグデータ分析の有効な生かし方について解説する。 Hadoop+Embulk+Kibanaのデータ集計基盤によるデータ可視化と集計データを活用したキーワードサジェストの仕組み
Hadoop+Embulk+Kibanaのデータ集計基盤によるデータ可視化と集計データを活用したキーワードサジェストの仕組み
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。今回は、ログデータの分析および可視化の基盤を構成する5つの主なOSSや集計データを活用したキーワードサジェストの事例を紹介します。