複数話者でも個別に音声をテキストへ、日立が音源分離技術を製品化:音声認識率で世界第2位の評価
日立製作所は会話音声をテキスト化する「音声書き起こし支援サービス」の販売を開始した。雑音が含まれていたり、複数人の音声が重なっていたりしても、話者を識別して、話者ごとに分離したテキストを生成できる。
日立製作所は2018年10月16日、会議や商談などの会話音声をテキスト化する「音声書き起こし支援サービス」の販売を開始した。同年6月27日に発表したAI活用の「チャットボットサービス」に続く、対話型botを活用して業務改革や新たな価値の創出を支援する「デジタル対話サービス」の第2弾と位置付ける。
音声書き起こし支援サービスは、音声認識技術を利用して、会話の音声データをテキストに変換するクラウドサービス。日立製作所独自の2つの技術を用いる。一つは雑音や反響音を除去して認識対象の音声のみを抽出する雑音除去技術。もう一つは複数方向からの音声を別々に認識する音源分離技術。
これらの技術によって、雑音を含んでいたり、複数人の音声が重なっていたりしても、話者を識別して、話者ごとに分離したテキストを生成できるという。

従来の音声認識技術では、口元とマイクの距離が大きく離れると認識率が低下することがあった。そのため音声認識の精度を高めるには、個人ごとにマイクを用意する必要があった。
これに対し、音源方向を特定する日立製作所の技術を組み込んだマイクでは、1台だけで、録音した音声データから複数話者の音声を音源方向から識別し、話者ごとに音声をテキスト化できる。
日立製作所によれば、一般のマイクやICレコーダー、スマートフォンなどで録音した音声でも、今回のサービスを利用すれば容易にテキスト化できるという。
なお、音声書き起こし支援サービスではユーザーが単語や例文を登録でき、固有名詞や専門用語などを追加すれば、ユーザーの業務に合わせて音声認識精度を高められるという。
サービスの提供開始は2018年10月31日。価格は個別見積もり。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 音声→テキスト変換のSpeech Recognition APIの使い方と、2017年4月におけるWatson、Google Cloud Speech APIとの違い
音声→テキスト変換のSpeech Recognition APIの使い方と、2017年4月におけるWatson、Google Cloud Speech APIとの違い
コグニティブサービスのAPIを用いて、「現在のコグニティブサービスでどのようなことができるのか」「どのようにして利用できるのか」「どの程度の精度なのか」を検証していく連載。今回は、Speech Recognition APIの概要と使い方を解説し、他のサービスとの違いを3パターンで検証する。 Google、Cloud AutoMLでテキスト分析と翻訳に対応、認知系AIサービスも強化
Google、Cloud AutoMLでテキスト分析と翻訳に対応、認知系AIサービスも強化
Googleは2018年7月24日(米国時間)、年次イベント「Google Cloud Next ’18」で、GoogleCloud Platform(GCP)における認知系AIサービスの強化を発表した。Cloud AutoMLではテキスト分析と翻訳が追加。また、既存の認知系APIサービスにおける強化も発表された。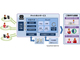 AIが回答精度を高めて運用を支援――日立がチャットbotサービスを販売開始
AIが回答精度を高めて運用を支援――日立がチャットbotサービスを販売開始
日立製作所は、「チャットbotサービス」を販売開始する。FAQや業務シナリオなどから適切な回答を自動的に返す。人工知能を活用して、回答精度を高める機能も備える。