及川卓也×山田誠二対談「機械が人に合わせる」時代から「人が機械に合わせる」時代へ――エンジニアのシンギュラリティーを考える:@ITソフトウェア品質向上セミナー2018
システム開発現場の在り方はAIや機械学習によってどのように変わるのか――@ITソフトウェア品質向上セミナーの特別講演「AI/機械学習、自動化で開発現場にも訪れるシンギュラリティーにどう備えるか」で、フリーランス エンジニアリング・プロダクトアドバイザーの及川卓也氏と、長年AIの研究に携わる国立情報学研究所教授の山田誠二氏が対談した。
主に機械学習/ディープラーニング技術の進化を受け、第三次人工知能(AI)ブームが到来した。その中でたびたび話題になる言葉が、AIが人の頭脳を超える「シンギュラリティー」だ。
だが、本当にシンギュラリティーは到来するのか。そして、その日が到来するにせよしないにせよ、システム開発現場の在り方はAIや機械学習によってどのように変わるのか、あるいはもう変わりつつあるのか――2018年12月14日に開催された@ITソフトウェア品質向上セミナーの特別講演「AI/機械学習、自動化で開発現場にも訪れるシンギュラリティーにどう備えるか」では、フリーランス エンジニアリング・プロダクトアドバイザーの及川卓也氏と、国立情報学研究所教授 総合研究大学院大学教授 東京工業大学特定教授の山田誠二氏が、こんな刺激的なテーマについて対談した。

長年AIの研究に携わり、どちらかといえばシンギュラリティー否定論者の山田氏によると、「実際には、AIは人間と一緒に作業しないと使いものにならないことが認識されつつある。過去のAIブームではルールベースのAIが注目されたが、世の中には暗黙知が多く、ルールとして記述できないことが大半だ。では、それが機械学習/ディープラーニングで解決されたかというと、表面的にはそのように見えるがそうではない」と述べた。
また、機械学習を実用に耐えるものにするには、まずデータを集め、クリーニングやラベリングといった処理を行って「教師データ」を作り、アルゴリズムを選んで学習させてモデルを作っていかなければならない。このようにフローを書くときれいに上流から下流へと流れるように見えるが、「実際にはうまくいかず、前に戻ってパラメーターを変え、チューニングしながらループを回すことがほとんどだ。ここを人間がやっており、一番ボトルネックになっている」(山田氏)。
AIは、ソフトウェア開発、運用の各プロセスをどのようにサポートできるのか?
及川氏は「私が社会人になった1980年代からずっと『シンギュラリティーが実現すればプログラマーはいらなくなる』と言われてきたが、今に至るまで実現していない。果たしてどこまで人間が楽をできるのか、AIや機械学習をどう活用できるかを掘り下げたい」と述べた。
そして、ソフトウェア開発/運用のプロセスをざっくりと「要件定義」「プロトタイピング/UIデザイン設計」「コーディング」「ビルド/バージョン管理」「コードレビュー/テスト/バグ修正」「デプロイ/リリース」「運用監視」「保守」という8つに分け、それにプロジェクト管理を加えた9つの分野において、どの程度AI/機械学習が活用されているか、幾つかの例を挙げながら紹介した。
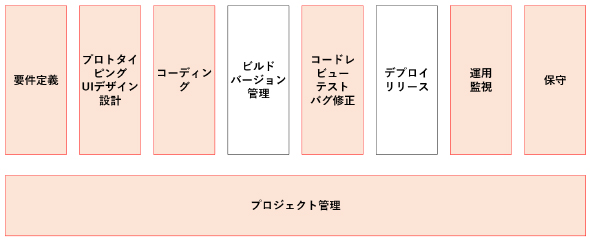
プロトタイピング/UIデザイン設計
プロトタイピング/UIデザイン設計の分野では、Adobe Systemsが積極的にAI技術に取り組み、「Adobe Sensei」のような技術を発表している。画像の修正作業を人間のデザイナー並みに行うだけではなく、3Dの画像に適切にテキスチャを貼り付けていくといった複雑な作業を人間よりも素早くこなしたり、さらにはデザイナーそれぞれのスタイルを学習し、個々のフレーバーに合わせたものを作成したりすることまで可能になりつつある。プロトタイピングツールのAdobe XDと組み合わせることで、Adobe Senseiに「iPhone用のレイアウトにして」とお願いすると自動でレイアウトを行う。
とはいえ、「スマートフォン向けに作成したデザインを、デザインガイドに沿ってタブレット向けにレイアウトし直すといった具合にフレームが決まっているものならともかく、今までにないもの、新しいものを打ち出していくクリエイティビティーが必要な分野にAIを適用するのはどこまで適切なのか」と及川氏は問い掛けた。

山田氏は、AIに奪われない仕事の上位にクリエイティブ系があるというオックスフォード大准教授の論文に言及した上で、「デザインや音楽がパターンの組み合わせにすぎないとすれば、無数にある組み合わせの中から良いものを見つけ出すのはAIが得意なところになる。だが、最後の価値判断は人間に残されているのでは」とした。
またMicrosoftのSketch2Codeのように、人が手でスケッチしたデザインの画像をHTMLに変換する技術も登場しているが、山田氏は「例えば手書きのものを見て、それが左ぞろえか、中央ぞろえかなどを判定するのは機械には難しい」とする。つまり、「機械がいかにコンテキストを読み取るか、裏返せば人間が機械に対してどれだけのコンテキストを与えられるかによって、どれだけ活用できるかが変わってくるだろう」と及川氏も述べた。

コーディング
コーディングの部分では、GitHub上で100以上のスターを集めた2000超のリポジトリのソースコードを学習し、コーディング中のコード補完の提案を、IntelliSenseよりもさらに高精度にしてくれるという「Microsoft Visual Studio IntelliCode」がある。
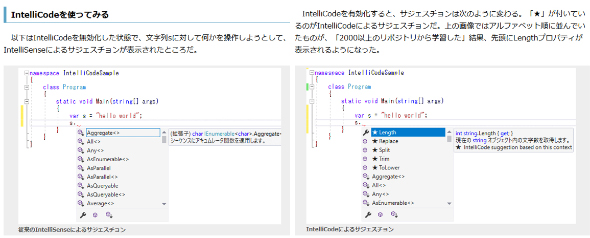
これについて、山田氏は「これは典型的な時系列予測の例。統計的に分析を行って次の文字列を予測しているだけで、意味も何も分かっていないし、教師データが質の高いコードである必要がある。そもそも『質の高いコード』とは何か、読みやすいものかどうか、それとも実行速度か……といった部分にまで踏み込まれることに期待したい」とした。
及川氏は、「そもそもAIが作成したコードは誰のものか、著作権はどうなるのか」といった部分も気になっているという。山田氏は「今の時点ではまだ何も考えられていないが、学習モデルに著作権を主張する動きは出てきているらしい」とした。
コードレビュー/テスト/バグ修正
同様にコードレビューの段階でも、富士通がソースコードの可読性を診断するツールを「KIWare」の一部としてリリースしたり、脆弱(ぜいじゃく)性を検出するファジングに機械学習とディープニューラルネットワークを適用する研究が登場したりするなど、幾つかの取り組みがある。このうちKIWareのソース診断ツールは、ソースコードを画像として学習し、インデントやネストの深さなどを基に読みやすさを判断するものだ。開発現場での長年の経験を持つ及川氏は「インデントが適切か、ネストが深過ぎないかといった事柄はソフトウェア開発において本質ではなく、自分としては言いたくないし言われたくもない。逆に、こういう事柄は機械に指摘してもらうのもいいのでは」とコメントした。

コード解析に関して及川氏は「従来、いわゆる『コード解析ツール』があり、大量のソースコードからバグや脆弱性を見つけるものがあったが、機械学習を使うことで、従来と何が違うのかがポイントになるだろう。また、きちんとした教師データを取っているかどうかが大事になるのではないか。例えば『Code Climate Velocity』というサービスは、GitHubにおいて『どのようなプルリクエストだとレビューが速いか』などの統計データを取っている。そのようなデータが機械学習の教師データとして使われればいいのではないか」と述べた。
これに対し山田氏も「いわゆる『ビッグデータ時代』ということでデータなら何でもかんでも残していた時代は終わった。『データを残すことで、どんなアルゴリズムを実現できるか』『機械学習によって、どんな機能を実現できるか』を考え、選択的に残さなければいけない」とした。
運用監視/保守/プロジェクト管理
運用監視/保守/プロジェクト管理の側面からは、機械学習による予兆検知と自然言語処理を中心に、研究やツールの紹介があった。
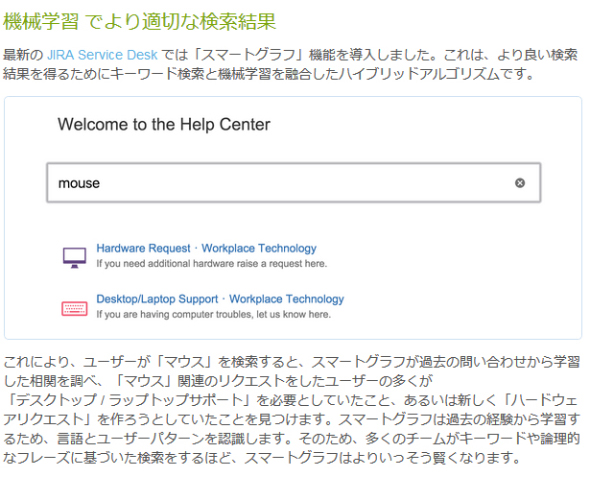
予兆検知では、同日行われたランチセッションでQTnetが紹介した、監視で取得したメトリクスを教師データにしてサーバ障害の予兆検知を行う取り組み(※詳細なレポート記事は後日公開予定)や、プロジェクト管理においても、プロジェクトリスクの予兆検知を行うようなツールがある。自然言語処理を活用するツールとして紹介されたのは、議事録の自動生成や、「JIRA Service Desk」が搭載した「スマートグラフ」機能などだ。
ソフトウェアをエンドユーザーが使うことによって、問い合わせが来ることがある。この問い合わせには、開発者が受けることがあるが、開発に限らず、多くのサービスがそうであるように、問い合わせ対応には同じような質問が来ることが多い。同じような質問とそれに対する回答をまとめたFAQ/サービスデスクを設けているサービスも多いが、大量の情報があるため、エンドユーザーには「欲しかった回答」が見つけにくい。検索精度の高さが重要となる。「JIRA Service Desk」というまさにサービスデスクを作るためのツールでは、ユーザーの質問内容を踏まえ、最適な答えに誘導できるように機械学習で検索精度を高めた。
問い合わせ対応は、何も開発者とエンドユーザーの間だけにあるものではない。開発者とプロジェクト管理者の間にもある。「IBM WatsonコグニティブPMO」には、開発者からプロジェクト管理者への問い合わせ対応をWatsonのチャットbotで自動化する機能を備えていることも紹介された。
山田氏は、「ディープラーニングはもともと、視覚野、つまり画像処理から始まった。だから空間データには強いが時間データには弱い。その意味で自然言語系の活用はまだ遅れている」と評価した。
人間が機械に合わせることで、より良い活用が可能に

このように開発/運用の各プロセスにおけるAI/機械学習の適用を検討した結果、全体を通じて及川氏は「いかにコンテキストを与えるかが大事ではないか」とコメントした。これに対し山田氏は「結局、今のAIはコンテキストフリーになっていない。決まったコンテキストの中では性能を発揮するけれど、想定しないコンテキストに変わると対応できない。現段階のAIをうまく使うには、人間の側がコンテキストを制限してあげる必要がある」と提言した。
これを踏まえて及川氏は「人が機械を使う一方で、人が機械に合わせるというアプローチもあると思う」と、山田氏が研究を進める「ヒューマンエージェントインタラクション」に言及。山田氏は「これまでのコンピュータやユーザーインタフェースの歴史は、機械が人に合わせる方向で進んできた。つまり『人にやさしい機械』を追求してきた。だが今度は、人間が機械に合わせる時代が到来しているかもしれない。機械にやさしい行動をいかに引き出すか、エモーショナルデザインや擬人化などを組み合わせ、いかに親近感を持たせるのが大事ではないか」と補足した。
及川氏は最後に、「私はちょっとひねくれているところもあるので、人間もAPIを公開してくれたらいいのになって思うこともある。けれど、これから求められるのはそうではなく、人が普通に行動しているだけで、そのコンテキストが機械側に渡るデザインやUXが必要ということではないか。機械の進化に合わせる形で人も進化していくことが、機械をより活用する際のポイントではないか」と対談を締めくくった。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 米ライス大学の研究者、ディープラーニングを用いたコーディング支援システム「Bayou」を開発
米ライス大学の研究者、ディープラーニングを用いたコーディング支援システム「Bayou」を開発
米ライス大学の科学者が、ディープラーニングを利用したコーディング支援システム「Bayou」を開発した。BayouはプログラマーがAPIを使いこなす際に特に役立つ。 クラウドへの移行を自動化する新サービスをIBMが発表、「IBM Cloud Migration Factory」を利用
クラウドへの移行を自動化する新サービスをIBMが発表、「IBM Cloud Migration Factory」を利用
IBMがクラウド関連の新サービスを発表した。ハイブリッドマルチクラウド戦略を採用した企業が、ビジネストランスフォーメーションを加速する際の複雑なプロセスを支援するという。 本当のFinTechは泥臭い――三菱東京UFJ銀行に見るセキュアで価値あるAPI開発
本当のFinTechは泥臭い――三菱東京UFJ銀行に見るセキュアで価値あるAPI開発
今やエンジニアは、ビジネス要件に応じた製品やサービスを「迅速」に、しかも「高い品質」で、できれば「低コスト」で開発し、リリースするという、相反する要求を同時に満たす必要に迫られている。そのヒントを三菱UFJフィナンシャル・グループの講演などから探る。