第6回 カスタマイズするための、TensorFlow 2.0最新の書き方入門:TensorFlow 2+Keras(tf.keras)入門
TensorFlow 2.0以降では「サブクラス化」という基本パターンに従って簡単にカスタマイズができる。その全カスタマイズ方法を紹介し、最後にtf.estimator高水準APIについても言及する。
前々回と前回は、TensorFlow 2.x(2.0以降)の書き方を説明した。既に全3種類4通りの書き方を説明済みだが、基本はそれらで修了である。
今回は、応用編として残り2つの書き方を紹介する。※脚注や図、コードリストの番号は前回からの続き番号としている(前々回・前回・今回は、切り離さず、ひとまとまりの記事として読んでほしいため連続性を持たせている)。
今回の内容と方針について
TensorFlowのメリットは、初心者向けからエキスパート向けまでさまざまな書き方が用意されており、誰でも簡単に学んで使いこなせるだけでなく、必要に応じて応用発展的な実装も可能なことである。
逆に、そのメリットがデメリットでもあり、人によって書き方が大きく違うこととなり、初心者から見ると理解の妨げになりやすい。例えばTensorFlowの公式チュートリアルやドキュメント、ネット上/GitHub上のサンプルコードを見ると、実にさまざまな書き方がなされている。
それに拍車をかけるのが、TensorFlow 1.x時代のコードである(例えば、こちらの記事が1.x時代のコード)。1.x時代は、TensorFlowライブラリ内にさまざまな高水準APIが乱立した。2.0になった段階で、高水準APIのほとんどが廃止され、tf.kerasとtf.estimatorという2つのみが高水準APIとして残った。このように1.xから2.xへと移行した段階で大変革が起きている。ネット上には、今後は2.xベースのコードが増えていくだろうが、依然として1.x時代のコードが大量に残っているため、TensorFlowのコードに関する誤解や混乱状態はしばらく続くだろう(と筆者は予想している)。
そういった点を踏まえ、あえて本連載の読者ターゲットである「ディープラーニング初心者向け」を想定して、TensorFlow 2.x時代の書き方を今回までの全3回でまとめている。全ての書き方を「マスターしてほしい」という意図ではなく、知識として書き方のバリエーションを知ってもらうことで、初心者でも「世界中にあるドキュメントやサンプルコードを戸惑わずに読めるようになってほしい」というのが意図である。
今回は、ニューラルネットワークのモデル設計〜学習〜評価までをフルカスタマイズする方法を紹介する。
しかしこれは(繰り返しになるが)「マスターしてほしい」というわけではなく、「知識として知っておいてほしい」というのが目的である。よって今回は書き方を、ざっと紹介するにとどめ、具体的な解説は割愛する。たとえコードの中身が分からなくても気にせず、本当に必要になってから本稿の内容を再読したりして、本当のフルカスタマイズを実践すればよい。
また、初心者が扱う機能は基本的にライブラリ内に存在するので、まずはそれを探せるように、既存機能の情報を箇条書きで提示する。“車輪の再発明”をする必要はないので、実践ではまず既存機能を確実にチェックするようにしてほしい。
コードの書き方を実行するための準備
前提条件
今回も前々回/前回に引き続き、Python(バージョン3.6)と、ディープラーニングのライブラリ「TensorFlow」の最新版2.1を利用する。また、開発環境にGoogle Colaboratory(以下、Colab)を用いる。
前提条件の準備は前々回/前回と同じなので、説明を割愛する。詳しくはColabのノートブックを確認してほしい。
それでは準備が整ったとして、(5)の書き方を説明していこう。
(5)TensorFlow低水準APIでカスタム実装[TensorFlow Low-level API]
TensorFlow 2.xでフルカスタマイズを行う場合、カスタマイズのベースとなるのが、前回説明した(4)Subclassing(サブクラス化)モデルである。その書き方では、tf.keras.Modelクラスをサブクラス化して独自のモデルを作成した。これは、「モデルをカスタマイズした」と見ることができる。これがTensorFlow 2.x時代のカスタマイズの基本パターンである。
基本パターン
TensorFlow 2.xでは、
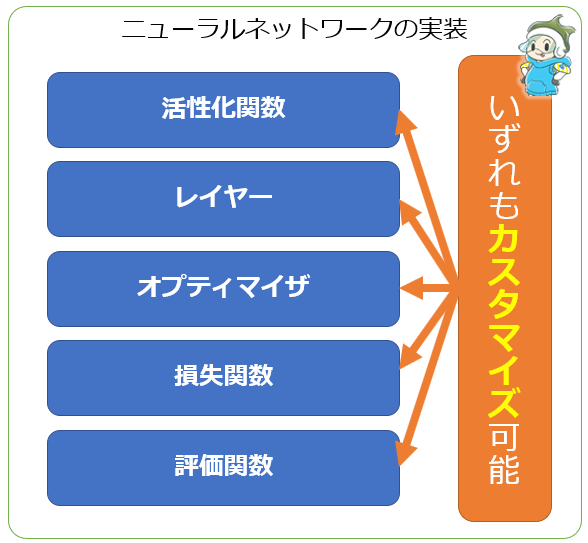
- 活性化関数: tf.keras.layers.Layerクラスをサブクラス化
- レイヤー: tf.keras.layers.Layerクラスをサブクラス化
- オプティマイザ(最適化アルゴリズム): tf.keras.optimizers.Optimizerクラスをサブクラス化
- 損失関数: tf.keras.losses.Lossクラスをサブクラス化
- 評価関数: tf.keras.metrics.Metricクラスをサブクラス化
などの機能がカスタマイズ可能である(図5-1)。

上記の箇条書きに示したように、いずれも何らかのクラスをサブクラス化することで実装できる。これが本稿で伝えたい「フルカスタマイズの本質」である。サブクラス化の中で実装すべきメンバーメソッドは少しずつ異なるので、以下ではそれらを見ていく。
活性化関数のカスタム実装
まずは、活性化関数の既存機能を確認しよう。
TensorFlow 2.xの活性化関数は、Keras由来のAPIと、TensorFlow由来のAPIの2種類がある。非常に充実しているので、カスタム実装を行う必要性はほとんど発生しないはずである。具体的には以下のものがある。
【Keras由来】
- 'sigmoid': tf.keras.activations.sigmoid()関数
- 'hard_sigmoid': tf.keras.activations.hard_sigmoid()関数
- 'tanh': tf.keras.activations.tanh()関数
- 'relu',: tf.keras.activations.relu()関数
- 'elu': tf.keras.activations.elu()関数
- 'selu': tf.keras.activations.selu()関数
- 'swish': tf.keras.activations.swish()関数
- 'softsign': tf.keras.activations.softsign()関数
- 'softplus': tf.keras.activations.softplus()関数
- 'softmax': tf.keras.activations.softmax()関数
- 'linear': tf.keras.activations.linear()関数
- 'exponential': tf.keras.activations.exponential()関数
【TensorFlow由来】
- tf.nn.sigmoid()関数
- tf.nn.tanh()関数
- tf.nn.relu()関数
- tf.nn.relu6()関数
- tf.nn.leaky_relu()関数
- tf.nn.elu()関数
- tf.nn.selu()関数
- tf.nn.swish()関数
- tf.nn.softsign()関数
- tf.nn.softplus()関数
- tf.nn.softmax()関数
前々回説明した、
- Sequentialモデル(リスト1-1/2-1)では'tanh'という文字列を
- Functional API(リスト3-1)やSubclassingモデル(リスト4-1)ではtf.keras.layers.Activationクラスを
使用した。それらの代わりに、tf.keras.activations.tanh()関数やtf.nn.tanh()関数を使用することも可能である。
既存の活性化関数やそのサブクラス化について詳しくは下記のリンク先を参照してほしい。
以上を探しても目的の活性化関数が見つからない場合は、次のようにしてカスタム(独自)のものを作成することが可能だ(リスト5-1)。
# カスタムの活性化関数のPython関数を実装
def custom_activation(x):
return (tf.exp(x)-tf.exp(-x))/(tf.exp(x)+tf.exp(-x))
# カスタムの活性化関数クラスを実装(レイヤーのサブクラス化)
# (tf.keras.layers.Activation()の代わり)
class CustomActivation(tf.keras.layers.Layer):
def __init__(self, **kwargs):
super(CustomActivation, self).__init__(**kwargs)
def call(self, inputs):
return custom_activation(inputs)
tf.keras.layers.Layerクラスをサブクラス化して、独自のCustomActivationクラスを実装している(※前回説明したモデルのサブクラス化と非常に似ている方法であることに気付くだろう)。クラス内部のメンバーメソッドは以下のようになっている。
- __init__()メソッド: 初期化処理
- call()メソッド: 活性化関数の処理
tf.keras.layers.Layerクラスのサブクラス化についてより詳しくは、
を参照してほしい(※ページ内を「subclass」で検索するとよい)。
リスト5-1では、活性化関数をPython関数(custom_activation()関数)として切り出すことで、tf.keras.activations.tanh()関数やtf.nn.tanh()関数と同じような感覚でも使えるようにも実装したが、もちろんcall()メソッド内に直接実装してもよい。
また、custom_activation()関数の中では、tf.exp()関数や+-/といった四則演算が記載されている(※なお、関数の引数に渡されるxは、TensorFlowテンソルである)。このように数学計算は、基本的にはNumPyと同じように行える。こういったtf.xxxという関数や演算子はTensorFlow低水準APIと呼ばれる。それぞれ詳しくは下記のドキュメントを参照してほしい。
- 数学関数の公式ドキュメント「Module: tf.math | TensorFlow Core v2.x」
- 演算子の公式ドキュメント「tf.Tensor | TensorFlow Core v2.x」
リスト5-1では、TensorFlow低水準APIで記述したが、Keras backend APIを使うこともできる。tf.kerasではなく、スタンドアロンKerasを使う場合は、Keras backend APIを使うことになる(リスト5-2)。
import tensorflow.keras.backend as K
# カスタムの活性化関数のPython関数を実装
def custom_activation(x):
return (K.exp(x)-K.exp(-x))/(K.exp(x)+K.exp(-x))
# ……独自クラスの実装は同じなので割愛……
と言っても、リスト5-1と5-2を比較すると分かるように、ほぼ同じコードとなる。以下では、TensorFlow低水準APIのみで記述する。Keras backend APIの参考実装は、冒頭で示したColabノートブックの方にコメントで含めておいたので、必要に応じて参考にしてほしい。
レイヤーのカスタム実装
次に、レイヤーの既存機能を確認しよう。
TensorFlow 2.xのレイヤーは、全てKeras由来のものに統一されている。これも非常に充実しているので、カスタム実装を行う必要性はほとんど発生しないだろう。代表的なものには以下のものがある。
- Denseクラス
- Activationクラス
- Dropoutクラス
・SpatialDropout1Dクラス
・SpatialDropout2Dクラス
・SpatialDropout3Dクラス - Flattenクラス
- InputLayerクラス
- Reshapeクラス
- Permuteクラス
- RepeatVectorクラス
- Lambdaクラス
- ActivityRegularizationクラス
- Maskingクラス
レイヤーは多種多様なものが用意されており、数が多すぎてここで列挙するととても長くなってしまうので、一部だけを抜粋した。既存のレイヤーについて詳しくは下記のリンク先を参照してほしい。
以上を探しても目的のレイヤーが見つからない場合は、次のようにしてカスタム(独自)のものを作成することが可能だ(リスト5-3)。
# カスタムの全結合層(線形変換)のPython関数を実装
def fully_connected(inputs, weights, bias):
return tf.matmul(inputs, weights) + bias
# カスタムのレイヤークラスを実装(レイヤーのサブクラス化)
# (tf.keras.layers.Dense()の代わり)
class CustomLayer(tf.keras.layers.Layer):
def __init__(self, units, input_dim=None, **kwargs):
self.input_dim = input_dim # 入力の次元数(=レイヤーの入力数)
self.units = units # ニューロン数(=レイヤーの出力数)
super(CustomLayer, self).__init__(**kwargs)
def get_config(self):
# レイヤー構成をシリアライズ可能にするメソッド(独自の設定項目がメンバー変数としてある場合など、必要に応じて実装する)
config = super(CustomLayer, self).get_config()
config.update({
'input_dim': self.input_dim,
'units': self.units
})
return config
def build(self, input_shape):
#print(input_shape) # 入力形状。例えば「(2, 2)」=2行2列なら入力の次元数は2列
input_data_dim = input_shape[-1] # 入力の次元数(=レイヤーの入力数)
# 入力の次元数をチェック(デバッグ)
if self.input_dim != None:
assert input_data_dim == self.input_dim # 指定された入力次元数と実際の入力次元数が異なります
# 重みを追加する
self.kernel = self.add_weight(
shape=(input_data_dim, self.units),
name='kernel',
initializer='glorot_uniform', # 前々回のリスト1-3のような独自の関数も指定できる
trainable=True)
# バイアスを追加する
self.bias = self.add_weight(
shape=(self.units,),
name='bias',
initializer='zeros',
trainable=True)
#self.built = True # Layerクラスでビルド済みかどうかを管理するのに使われている(なくても大きな問題はない)
super(CustomLayer, self).build(input_shape) # 上と同じ意味。APIドキュメントで推奨されている書き方
def call(self, inputs):
return fully_connected(inputs, self.kernel, self.bias)
tf.keras.layers.Layerクラスをサブクラス化して、独自のCustomLayerクラスを実装している。クラス内部のメンバーメソッドは以下のようになっている。
- __init__()メソッド: 初期化処理。渡された引数をメンバー変数に保存したりする
- get_config()メソッド: オプション(実装しなくてもよい)。メンバー変数を含む構成情報をPython辞書形式にシリアライズする(保存→ロード用)
- build()メソッド: オプション。基本的に重みやバイアスなどのパラメーターを作成する
- call()メソッド: レイヤーの処理。この例では全結合の線形変換を、fully_connected関数に実装して、それを呼び出している
tf.keras.layers.Layerクラスのサブクラス化についてより詳しくは、
を参照してほしい(※ページ内を「subclass」で検索するとよい)。
オプティマイザ(最適化アルゴリズム)のカスタム実装
続いて、オプティマイザの既存機能を確認しよう。
TensorFlow 2.xのオプティマイザも、全てKeras由来のものに統一されている。tf.optimizers名前空間は、Keras由来のtf.keras.optimizers名前空間のエイリアスになっている。
これも充実しているので、カスタム実装を行う必要性はほとんどない。具体的には以下のものがある。
- SGDクラス(確率的勾配降下法)
- RMSpropクラス
- Adagradクラス
- Adadeltaクラス
- Adamクラス
- Adamaxクラス
- Nadamクラス
- Ftrlクラス
既存のオプティマイザについて詳しくは下記のリンク先を参照してほしい。
以上を探しても目的のオプティマイザが見つからない場合は、次のようにしてカスタム(独自)のものを作成することが可能だ(リスト5-4)。
# カスタムの最適化アルゴリズムクラスを実装(オプティマイザのサブクラス化)
# (tf.keras.optimizers.SGDの代わり)
class CustomOptimizer(tf.keras.optimizers.Optimizer):
def __init__(self, learning_rate=0.01, name='CustomOptimizer', **kwargs):
super(CustomOptimizer, self).__init__(name, **kwargs)
self.learning_rate = kwargs.get('lr', learning_rate)
def get_config(self):
config = super(CustomOptimizer, self).get_config()
config.update({
'learning_rate': self.learning_rate
})
return config
def _create_slots(self, var_list):
for v in var_list: # `Variable`オブジェクトのリスト
self.add_slot(v, 'accumulator', tf.zeros_like(v))
# 参考実装例。※ここで作成したスロットは未使用になっている
def _resource_apply_dense(self, grad, var):
# 引数「grad」: 勾配(テンソル)
# 引数「var」: 更新対象の「変数」を示すリソース(“resource”データ型のテンソル)
# var.device の内容例: /job:localhost/replica:0/task:0/device:CPU:0
# var.dtype.base_dtype の内容例: <dtype: 'float32'>
acc = self.get_slot(var, 'accumulator') # 参考実装例(スロットは未使用)
return var.assign_sub(self.learning_rate * grad) # 変数の値(パラメーター)を更新
def _resource_apply_sparse(self, grad, var, indices):
# 引数「grad」: 勾配(インデックス付きの、スパースなテンソル)
# 引数「var」: 更新対象の「変数」を示すリソース(“resource”データ型のテンソル)
# 引数「indices」: 勾配がゼロではない要素の 「インデックス」(整数型のテンソル)
raise NotImplementedError("今回は使わないので未実装")
# return ……変数の値(パラメーター)を更新する「操作」を返却する……
tf.keras.optimizers.Optimizerクラスをサブクラス化して、独自のCustomOptimizerクラスを実装している。クラス内部のメンバーメソッドは以下のようになっている。
- __init__()メソッド: 初期化処理。渡された引数をメンバー変数に保存したりする
- get_config()メソッド: オプション(実装しなくてもよい)。メンバー変数を含む構成情報をPython辞書形式にシリアライズする(保存→ロード用)
- _create_slots()メソッド: オプション。スロット(=トレーニングする変数に関連付けられた追加の変数)を作成する。スロットは「Adam」や「Adagrad」などで必要となる
- _resource_apply_dense()メソッド: 最適化処理。勾配が「(通常の)密なテンソル」である場合の、パラメーター(重みやバイアス)の更新処理
- _resource_apply_sparse()メソッド: 最適化処理。勾配が「スパースなテンソル(=要素の多くが0である疎な状態)」である場合の、パラメーターの更新処理
tf.keras.optimizers.Optimizerクラスのサブクラス化についてより詳しくは、
を参照してほしい(※ページ内を「subclass」で検索するとよい)。
学習のカスタム実装について
学習のカスタム実装については、前回説明済みである。これはフルカスタマイズの手法であるが、tf.kerasモデル内部の一部の関数を拡張して、tf.kerasモデルのfit()メソッド/evaluateメソッド/predictメソッド実行時の挙動を変えることも可能である。
具体的には、tf.keras.Modelクラスをサブクラス化したモデルの基底クラス内にある、
- train_step()メソッド
- test_step()メソッド
- predict_step()メソッド
をオーバーライドすることになる。
前回説明したフルカスタマイズの場合は、全て自分の世界観で全てを制御することになる。自分で考えたロジック内容だから、影響範囲も管理しやすい。
一方、tf.kerasモデル内部の部分的な拡張の場合は、あくまでKerasの世界観を壊さないように作る必要がある。よって考え方によっては、「こちらの実装の方が難しい」とも言えるだろう。

部分的な拡張の実装方法については、(筆者が確認した限り)ほとんど説明資料がない。唯一、「TensorFlow Dev Summit 2020」のセッション「Learning to read with TensorFlow and Keras (TF Dev Summit '20) - YouTube」でPaige Bailey氏が簡単に言及したのを確認したのみである。よって、tf.keras.Modelのソースコードを読んで理解したうえで実装する必要があり、あまりお勧めできない。そのため本稿では割愛する。
損失関数のカスタム実装
さて次に、損失関数の既存機能を確認しよう。
TensorFlow 2.xの損失関数も、全てKeras由来のものに統一されている。tf.losses名前空間は、Keras由来のtf.keras.losses名前空間のエイリアスになっている。
同じく充実しているので、カスタム実装を行う必要性はほとんどない。具体的には以下のものがある。
- MeanSquaredErrorクラス(略記:MSE): mean_squared_error()関数
- MeanAbsoluteErrorクラス(略記:MAE): mean_absolute_error()関数
- MeanAbsolutePercentageErrorクラス(略記:MAPE): mean_absolute_percentage_error()関数
- MeanSquaredLogarithmicErrorクラス(略記:MSLE): mean_squared_logarithmic_error()関数
- SquaredHingeクラス: squared_hinge()関数
- Hingeクラス: hinge()関数
- CategoricalHingeクラス: categorical_hinge()関数
- LogCoshクラス: logcosh()関数
- Huberクラス: huber_loss()関数
- CategoricalCrossentropyクラス: categorical_crossentropy()関数
- SparseCategoricalCrossentropyクラス: sparse_categorical_crossentropy()関数
- BinaryCrossentropyクラス: binary_crossentropy()関数
- KLDivergenceクラス(略記:KLD): kullback_leibler_divergence()関数
- Poissonクラス: poisson()関数
- CosineSimilarityクラス: cosine_proximity()関数
既存の損失関数について詳しくは下記のリンク先を参照してほしい。
以上を探しても目的の損失関数が見つからない場合は、次のようにしてカスタム(独自)のものを作成することが可能だ(リスト5-5)。
# カスタムの損失関数のPython関数を実装
def custom_loss(y_true, y_pred):
return tf.reduce_mean(tf.square(y_true - y_pred))
# カスタムの損失関数クラスを実装(レイヤーのサブクラス化)
# (tf.keras.losses.MeanSquaredError()の代わり)
class CustomLoss(tf.keras.losses.Loss):
def __init__(self, name="custom_loss", **kwargs):
super(CustomLoss, self).__init__(name=name, **kwargs)
def call(self, y_true, y_pred):
y_pred = tf.convert_to_tensor(y_pred) # 念のためTensor化
y_true = tf.cast(y_true, y_pred.dtype) # 念のため同じデータ型化
return custom_loss(y_true, y_pred)
tf.keras.losses.Lossクラスをサブクラス化して、独自のCustomLossクラスを実装している。クラス内部のメンバーメソッドは以下のようになっている。
- __init__()メソッド: 初期化処理
- call()メソッド: 損失関数の処理
tf.keras.losses.Lossクラスのサブクラス化についてより詳しくは、
を参照してほしい(※ページ内を「subclass」で検索するとよい)。
評価関数(正解率や損失)のカスタム実装
さて最後に、評価関数の既存機能を確認しよう。
TensorFlow 2.xの評価関数も、全てKeras由来のものに統一されている。tf.metrics名前空間は、Keras由来のtf.keras.metrics名前空間のエイリアスになっている。
これも充実しているので、カスタム実装を行う必要性はほとんどない。具体的には以下のものがある。
- Accuracyクラス: accuracy()関数
- BinaryAccuracyクラス: binary_accuracy()関数
- CategoricalAccuracyクラス: categorical_accuracy()関数
- SparseCategoricalAccuracyクラス: sparse_categorical_accuracy()関数
- TopKCategoricalAccuracyクラス: top_k_categorical_accuracy()関数
- SparseTopKCategoricalAccuracyクラス: sparse_top_k_categorical_accuracy()関数
- FalsePositivesクラス
- FalseNegativesクラス
- TrueNegativesクラス
- TruePositivesクラス
- Precisionクラス
- Recallクラス
- SensitivityAtSpecificityクラス
- SpecificityAtSensitivityクラス
- PrecisionAtRecallクラス
- AUCクラス
※なお評価関数としては、正解率などの精度だけでなく、損失も評価対象となる。損失については、損失関数と同じものがtf.keras.metrics名前空間内にも多く実装されている。先ほど示した損失関数と同じ名前になるため、上記の箇条書きでは省略した。
既存の評価関数について詳しくは下記のリンク先を参照してほしい。
以上を探しても目的の評価関数が見つからない場合は、次のようにしてカスタム(独自)のものを作成することが可能だ(リスト5-6)。
# 正解かどうかを判定する関数を実装
def custom_matches(y_true, y_pred): # y_trueは正解、y_predは予測(出力)
threshold = tf.cast(0.0, y_pred.dtype) # -1か1かを分ける閾値を作成
y_pred = tf.cast(y_pred >= threshold, y_pred.dtype) # 閾値未満で0、以上で1に変換
# 2倍して-1.0することで、0/1を-1.0/1.0にスケール変換して正解率を計算
return tf.equal(y_true, y_pred * 2 - 1.0) # 正解かどうかのデータ(平均はしていない)
# カスタムの評価関数クラスを実装(サブクラス化)
# (tf.keras.metrics.BinaryAccuracy()の代わり)
class CustomAccuracy(tf.keras.metrics.Mean):
def __init__(self, name='custom_accuracy', dtype=None):
super(CustomAccuracy, self).__init__(name, dtype)
# 正解率の状態を更新する際に呼び出される関数をカスタマイズ
def update_state(self, y_true, y_pred, sample_weight=None):
matches = custom_matches(y_true, y_pred)
return super(CustomAccuracy, self).update_state(
matches, sample_weight=sample_weight) # ※平均は内部で自動的に取ってくれる
tf.keras.metrics.Metricクラス(リスト5-6ではその派生クラスであるMeanクラス)をサブクラス化して、独自のCustomMetricクラスを実装している。クラス内部のメンバーメソッドは以下のようになっている(※Metricクラスをサブクラス化した場合は、以下に2つのメソッドに加えて、メトリクス値の計算結果を返すresult()メソッドも実装する必要がある)。
- __init__()メソッド: 初期化処理
- update_state()メソッド: 評価関数の処理。メトリクス統計を累積していく
tf.keras.metrics.Metricクラスのサブクラス化についてより詳しくは、
を参照してほしい(※ページ内を「subclass」で検索するとよい)。
今回は、原型となるMetricクラスではなく、平均処理が実装済みのtf.keras.metrics.Meanクラスをサブクラス化することで、平均に関する手間を軽減した。この例だと「Meanクラス内部がどのようになっているか」には注意が必要だが、こういった派生クラスを利用した実装も可能である。
ちなみに、既存のBinaryAccuracyクラスの実装内容を見るとMeanMetricWrapperクラスを継承しているが、このクラスはtf.keras.metrics名前空間からアクセスできないので利用しづらい。MeanMetricWrapperクラスを使いたい場合は、TensorFlowコミュニティが作るアドオン「tfa.metrics.MeanMetricWrapper」に同内容のものがあるので、それを使うとよいだろう(※実装方法の説明は割愛する)。
ここまでのカスタム実装の使用例
以上で全てのカスタマイズ方法を説明した。あとは実行するだけである。これは前回と同じコードとなるため説明は割愛し、コードと実行結果だけを示すこととする。
# 活性化関数の定義
activation1 = CustomActivation(name='activation1')
activation2 = CustomActivation(name='activation2')
acti_out = layers.Activation('tanh', name='acti_out')
# モデルの設計
class NeuralNetwork(tf.keras.Model):
def __init__(self, *args, **kwargs):
super(NeuralNetwork, self).__init__(*args, **kwargs)
self.layer1 = CustomLayer(units=LAYER1_NEURONS, name='layer1')
self.layer2 = CustomLayer(units=LAYER2_NEURONS, name='layer2')
self.layer_out = CustomLayer(units=OUTPUT_RESULTS, name='layer_out')
def call(self, inputs, training=None):
x1 = activation1(self.layer1(inputs))
x2 = activation2(self.layer2(x1))
outputs = acti_out(self.layer_out(x2))
return outputs
# モデルの生成
model = NeuralNetwork()
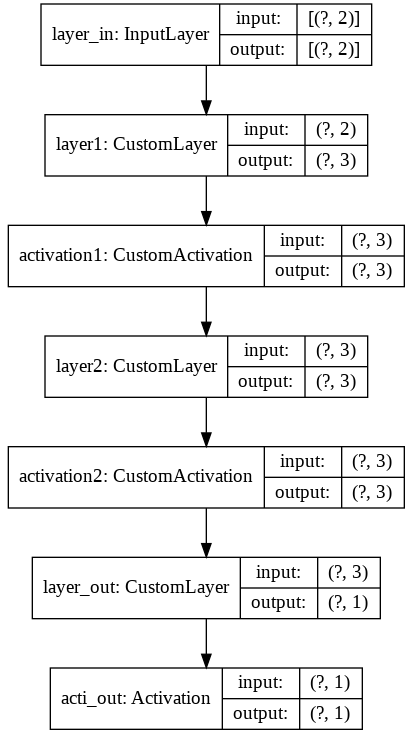
# モデルの概要と構成図の出力
def get_functional_model(model):
x = layers.Input(shape=(INPUT_FEATURES,), name='layer_in')
temp_model = tf.keras.Model(inputs=[x], outputs=model.call(x), name='cusotm_model')
return temp_model
f_model = get_functional_model(model)
f_model.summary()
tf.keras.utils.plot_model(f_model, show_shapes=True, show_layer_names=True, to_file='model.png')
from IPython.display import Image
Image(retina=False, filename='model.png')

# 最適化アルゴリズムと損失関数の定義
optimizer = CustomOptimizer(learning_rate=0.03)
criterion = CustomLoss()
# 評価関数(損失と正解率)の定義
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = CustomAccuracy(name='train_accuracy')
valid_loss = tf.keras.metrics.Mean(name='valid_loss')
valid_accuracy = CustomAccuracy(name='valid_accuracy')
# ミニバッチ用データの準備
X_train_f32 = X_train.astype('float32')
y_train_f32 = y_train.astype('float32')
X_valid_f32 = X_valid.astype('float32')
y_valid_f32 = y_valid.astype('float32')
train_sliced = tf.data.Dataset.from_tensor_slices((X_train_f32, y_train_f32)) # 訓練用
valid_sliced = tf.data.Dataset.from_tensor_slices((X_valid_f32, y_valid_f32)) # 精度検証用
train_dataset = train_sliced.shuffle(250).batch(15)
valid_dataset = valid_sliced.batch(15)
import tensorflow.keras.backend as K
# 1回分の訓練(学習)の処理
@tf.function
def train_step(train_X, train_y):
training = True
K.set_learning_phase(training)
with tf.GradientTape() as tape:
pred_y = model(train_X, training=training)
loss = criterion(pred_y, train_y)
gradient = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(gradient, model.trainable_weights))
train_loss(loss)
train_accuracy(train_y, pred_y)
# 1回分の精度検証(評価)の処理
@tf.function
def valid_step(valid_X, valid_y):
training = False
K.set_learning_phase(training)
pred_y = model(valid_X, training=training)
loss = criterion(pred_y, valid_y)
valid_loss(loss)
valid_accuracy(valid_y, pred_y)
# エポック数分、訓練(学習)と精度検証(評価)を実行
EPOCHS = 100
train_history = []
valid_history = []
for epoch in range(EPOCHS):
train_loss.reset_states()
train_accuracy.reset_states()
valid_loss.reset_states()
valid_accuracy.reset_states()
for train_X, train_y in train_dataset:
train_step(train_X, train_y)
for valid_X, valid_y in valid_dataset:
valid_step(valid_X, valid_y)
n = epoch + 1
avg_loss = train_loss.result()
avg_acc = train_accuracy.result()
avg_val_loss = valid_loss.result()
avg_val_acc = valid_accuracy.result()
train_history.append(avg_loss)
valid_history.append(avg_val_loss)
print(f'[Epoch {n:3d}/{EPOCHS:3d}]' \
f' loss: {avg_loss:.5f}, acc: {avg_acc:.5f}' \
f' val_loss: {avg_val_loss:.5f}, val_acc: {avg_val_acc:.5f}')
print('Finished Training')
print(model.get_weights())
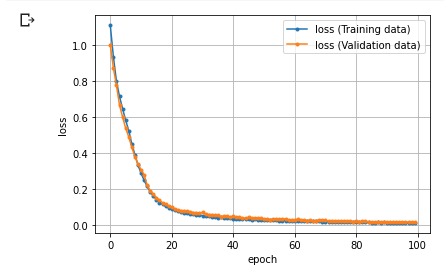
# 学習結果(損失)のグラフを描画
import matplotlib.pyplot as plt
epochs = len(train_history)
plt.plot(range(epochs), train_history, marker='.', label='loss (Training data)')
plt.plot(range(epochs), valid_history, marker='.', label='loss (Validation data)')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
# 推論
model(tf.constant([[0.1,-0.2]]))
# <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.99654746]], dtype=float32)> ……などと表示される
(6)作成済みEstimatorsの利用[tf.estimator](※非推奨)
作成済みEstimatorsについては、基本的に非推奨(主に互換性目的で存在するため)ではあるが、公式ドキュメント「Estimators | TensorFlow Core」に含まれており、全く無視するわけにもいかず、書き方の一つとして取り上げた。
しかし「あえてここで詳しく説明することは、逆に弊害である」と考え、
の中だけに参考実装を載せるにとどめた。ちなみにtf.estimatorの実装方法はあまり資料や情報がないので、その点でも学びにくいのでお勧めできない(※Colabノートブックのサンプルコードも、筆者がソースコードを読んだうえで構造を理解し、必要な情報を書き起こしたものである)。
次回以降について
今回は、Subclassing(サブクラス化)モデルを使ったフルカスタマイズの書き方について説明した。以上で、TensorFlowの書き方を一通り制覇したことになる。
次回以降は、ここで学んだSubclassingモデルとcompile()&fit()関数などを使って、ディープラーニングについての各種モデルについて学んでいく。次回は回帰問題を扱う。
Copyright© Digital Advantage Corp. All Rights Reserved.