「Observability(オブザーバビリティ)」「可観測性」とは何か――クラウドネイティブにおける監視で必要な理由と考慮点、お薦めのOSSの組み合わせ:Cloud Nativeチートシート(13)
Kubernetesやクラウドネイティブをより便利に利用する技術やツールの概要、使い方を凝縮して紹介する連載。今回は、「Observability(オブザーバビリティ)」「可観測性」について概要と考慮点、お薦めのOSSの組み合わせを紹介する。
※岡本、正野、宇都宮はNTTデータ所属
Kubernetesやクラウドネイティブをより便利に利用する技術やツールの概要、使い方を凝縮して紹介する本連載「Cloud Nativeチートシート」。連載第9回から第12回までは「サービスメッシュ」「Istio」を紹介してきました。今回から複数回に分けて「Observability(オブザーバビリティ)」「可観測性」にフォーカスして解説します。
今回は、Observabilityの概要と、その構成要素や考慮点を紹介し、次回以降Observabilityを構成する各要素に活用できるオープンソースソフトウェア(OSS)とその使い方を説明していきます。
目次
クラウドネイティブなシステムの監視の課題とObservability
Observabilityとは、システムを観測可能、つまり「いつ、何が、どこで起こっているのかを観測可能に保つ」考え方です。Observabilityを備えることで、複雑かつ動的にスケールするサービスでも、ワークロードの状態を正しく理解できるので、問題の検出やその根本原因の特定を行えます。
昨今、Observabilityという概念はクラウドネイティブな技術スタックの一つとして言及、検討されることが増えています。「CloudNative Difinition」や「マイクロサービスアーキテクチャパターン」の中にもそれぞれの技術要素の一つとして、Observabilityという単語が登場します。このことからも、クラウドネイティブな分散アーキテクチャを考慮する上で重要な概念となっていることが分かります。
なぜObservabilityはこういったクラウドネイティブ技術と一緒に語られることが多いのでしょうか? クラウドネイティブなシステムにおける監視の課題は、Kubernetesを例に取ると下記のようなシステムの複雑さによる課題があり、これらの課題をはらんだシステムを安定的に運用するには適切な技術を用いて「いつ、何が、どこで起こっているのかを観測可能に保つ」必要があるからです。
- 分散した多くのコンポーネントが多層に組み合わさる(複数のNode上で稼働する複数のPod)
- 下記2点の背景から、自動的にPodやNodeなどのコンポーネントをトラッキングする仕組みが必要
- コンポーネントの実行単位であるPodの数がオートスケールによって動的に変動したり、フェイルオーバー時にPod IDが変更されたりするので追跡が困難
- コンポーネントの追加や変更が頻繁にある
- コンポーネント同士の呼び出しがあると個々のコンポーネントの影響範囲をたどる必要がある
ここまでふわっと「観測可能に保つ」という表現でObservabilityについて説明しましたが、具体的にはどのような観点でそのような技術を使えばいいのでしょうか?
Observability自体はこれまでも多く議論され、いろいろな表現で説明されてきましたが、実は「Observability Whitepaper」(※)というドキュメントがCloud Native Computing Foundation(CNCF)から公開されており、Observability自体や要素の定義、ベストプラクティスがまとまっています。
※CNCFのTAG(Technical Advisory Group:特定の技術に対して、技術ガイドを提供するグループ)として、「Observability TAG」が発足しています。2021年にクラウドネイティブのObservabilityの集大成として、用語や定義とベストプラクティスの明文化がされたObservability Whitepaperを公開しました。
本稿では、こちらのWhitepaperを適宜参考にしながら、Observabilityの要点を押さえていきます。
Observabilityの構成要素(シグナル)
Observabilityをどのように実現していくかを考える上で重要なのが「何を観測すべきか」という点です。Whitepaperではシステムが生成する出力を「シグナル」と定義しています。このシグナルを観測することで、外部から「システムがどうなっているか」を推測できます。
Observabilityのシグナルの3本柱として広く認識されているのが、「メトリクス」「ログ」「トレース」です。Whitepaperには下図で表現されています。
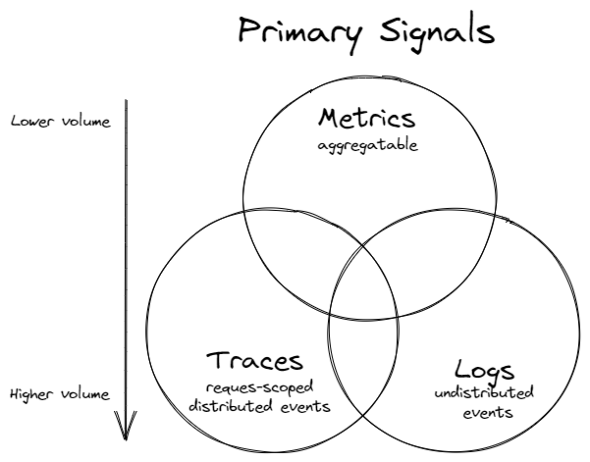
これらのシグナルが3本柱とされている理由には、複雑化したクラウドネイティブなアーキテクチャにおいて問題箇所の把握が従来型の監視だけでは難しく、ログやトレースとひも付けなければ問題の特定に至らないといった事情があります。それぞれ独立した要素ではなく、適宜ひも付けたり、変換したりしながら探索、可視化できることが重要です。上図で、各シグナルがそれぞれオーバーラップしているのはこういった理由からです。
ここからは、3本柱とその他取り上げられることのあるシグナルについて、それぞれのシグナルが何を指しているのか」「どういった観点が重要なのか」について簡単に説明ます。
なお、それぞれのシグナルのより具体的な使い方や実現技術(OSSなどのツール)については、別途次回以降の連載で触れます。
メトリクスとは?
メトリクスは、サーバのリソース状況(CPU使用率など)やサービス状況(レイテンシ、トランザクション量、エラーレートなど)といった、指標となる数値データで、これまでも古くから監視されてきた項目です。
次の特徴があります。
- 数値データのみに絞られているので、データ量が他のシグナルと比べて相対的に少なく送信や蓄積の処理や可視化が簡易で、状況のリアルタイムな把握や検知、絞り込みに活用できる
- 数値データなので、閾(しきい)値でアラートしたり、後から統計的な集計や分析をしたりすることができる
- 単一点の数値として確認するだけだと意味を成しにくく、時系列での傾向を確認したり、閾値と比較したりすることで利用可能となる
メトリクスは、基本的には時系列で数値データを扱うので、即時性があり、見やすい一方で、情報が不足することが多くあります(なぜその数値なのか、他とどういう関係なのか)。従って、メトリクスは必ずしも根本的な原因を明らかにするわけではなく、多くの場合、問題の方向付けと根本的な原因究明への出発点に必要な高レベルの概要を提供します。
通常「リアルタイム監視とアラート」「傾向分析、将来予測」の2つの方法で利用できます。
メトリクスの要素――「REDメソッド」「USEメソッド」
メトリクスと一口に言っても、取得できる項目は大きく二分できます。1つ目がサービスの稼働状況の監視、2つ目がサーバやコンテナのリソース状況の監視です、それぞれの代表的な監視項目の頭文字を取って「REDメソッド」「USEメソッド」といいます。
サービスの稼働状況について重要な指標となる次の3要素を監視するのが、REDメソッドです。
- Rate:毎秒リクエスト数(req/sec)
- Error Rate:エラー率
- Duration:レイテンシ、レスポンスタイム
そのサービスが、エンドユーザーから見てどのようなサービスレベルか(どれくらいアクセスが来ていて、どれくらい高速かつ正常にレスポンスを返しているのか)を監視します。
顧客体験(CX)に直結し、そのサービス自体の提供状況を定量的に表現できるので、SLI(Service Level Indicators)とSLO(Service Level Objectives)はこのメトリクスをベースに組み立てる必要があります。
アラートや障害対応時の優先度もこのメトリクスに基づいて実施するのが基本的には望ましいです。なぜなら、サーバのリソース使用状況がたとえ高くなっていてもユーザー影響が出ていなければ、それはその時点では「うまくリソースを活用できていて特に問題ではない」という評価ができないからです。「ユーザーに影響がある事象に優先度を起きましょう」ということです。
※参考
- https://grafana.com/blog/2018/08/02/the-red-method-how-to-instrument-your-services/
- https://www.weave.works/blog/the-red-method-key-metrics-for-microservices-architecture/
サーバのリソース状況について重要な指標となる次の3要素を監視するのが、USEメソッドです。
- Utilization:使用率(CPU使用率など)
- Saturation:飽和度、どれくらいキューに詰まっているか(ロードアベレージなど)
- Errors:エラーイベントの数(Pod再起動など)
サービス監視メトリクスと併せて確認することで、遅延時のボトルネック箇所など根本原因の特定に利用できます。また、事前に負荷テストなどでシステムのボトルネック特性をつかんで最初にボトルネックとなるコンポーネントを特定できていれば、そこを重点監視しておくことでユーザーへの影響が顕在化する前に検知と対応ができます。
ただし、何でもかんでもアラートを飛ばし過ぎるとオオカミ少年のようになってしまって、重要な情報を見落としてしまうので、選択と集中に気を付けましょう。
※参考
- https://www.brendangregg.com/usemethod.html
クラウドネイティブなアーキテクチャにおけるメトリクスの難しさ
冒頭でも触れましたが、クラウドネイティブなアーキテクチャでは、次のように幾つかの理由からメトリクスの収集作業が複雑化します。
- 分散した多くのコンポーネントが多層に組み合わさる(複数のNode上で稼働する複数のPod)
- 次の背景から、自動的にPodやNodeなどのコンポーネントをトラッキングする仕組みが必要
- コンポーネントの実行単位であるPodの数がオートスケールによって動的に変動したり、フェイルオーバー時にPod IDが変更されたりするので追跡が困難
- コンポーネントの追加や変更が頻繁にある
従って、多種多様なコンポーネントからのメトリクスの収集、スケールやリカバリーへの追随、それらのメトリクスに対する一貫性のあるメタデータ(≒ラベル)に添付することがメトリクス収集の技術として必要です。適切なメタデータ(≒ラベル)を付与することで、ダッシュボードの作成やトラブルシューティングの際に必要なメトリクスを簡単に抽出してグラフ化したり、確認したりすることができます。
このような、動的なコンポーネントを含む多種多様なコンポーネントからのメトリクスの収集を支援する機能(サービスディスカバリによるスクレイプとラベリング、多くの公開されたエクスポーター)を備えているOSSが「Prometheus」です。ダッシュボードの「Grafana」と併せてKubernetesにおけるデファクトのOSS監視スタックといえます。

ログとは?
ログもメトリクスと同様、従来ある概念で、各サーバやミドルウェア、アプリケーションなどにおいて、個別のイベント(何が発生しているのかの情報)を表す、人間が読める詳細な構造化情報です。こういったイベントの記録を保持することで、特定の状況が発生した原因について順序を追って理解でき、再現することも可能になります。
一口にログと言ってもいろいろあります。例えば下表のようなログがWhitepaperでは言及されています。
| ログ種別 | 概要 |
|---|---|
| システムログ | OS内部で発生するイベントを記録 ・カーネルレベルのメッセージ ・障害やステータスメッセージといった他のアクティビティー など |
| インフラストラクチャログ | オンプレミスやクラウドにおける、ITインフラに影響を与える物理的および論理的な機器のログ |
| アプリケーションログ | アプリケーション内でイベントが発生したときに作成される ※ロギングライブラリを使って実装されることが一般的 |
| 監査ログ | イベントと変更の記録 「誰がアクティビティーを実行したか」「どのアクティビティーが実行されたか」「システムがどのように応答したか」を記録 |
| セキュリティログ | システムで発生するセキュリティイベントに応答して作成されるログ |
これらのログを利用することで、システムやアプリケーションの状態を理解できるので、障害発生時の根本原因を分析するときに特に役立ちます。
これらのログは、ログ分析用のツールを介して視覚化、分析できます。ログレベル、エラーステータス、メッセージ、コードファイルなどの詳細についてログをGrep検索したり、秒間エラー数をカウントして可視化したり、アラートしたりなどが可能です。
ログにおいて一般的に考慮すべき点として、「ログレベル」「パースとログフォーマット」があります。
ログレベル
各ログステートメントに対してログレベルを設定することで、各ログステートメントの重要性を表せます。一般的には「ERROR」「WARNING」「INFO」「DEBUG」といったレベルが用いられ、ERRORが最も詳細ではないレベルで、DEBUGが最も詳細なレベルです。
- ERROR:障害が発生した理由とその詳細を通知する
- WARNING:障害ではないが、注意が必要な高レベルのメッセージ
- INFO:「システムがどのように機能しているか」を理解するのに役立つ
- DEBUG:各アクションの非常に詳細な情報が格納される。通常、トラブルシューティング中に使う。ストレージやパフォーマンスに影響があるので、短期間のみ使用される
ログの中には大量のテキストが含まれており、ログレベルをむやみに詳細にするとその量は膨大になり、その分検索時の性能劣化やストレージコスト増加につながっていきます。一方で、ログレベルが詳細ではないために情報が取れていないといったケースも起こり得ます。従って状況や重要性に応じて、適切にログレベルを設定することが重要です。
パースとログフォーマット
ログは、集計することでメトリクスに変換できます。例えば、秒間エラー数をカウントするなどのイメージが分かりやすいでしょう。
しかし、検索や可視化などのインタラクティブな分析、アラート、異常検知には、統一された形式で情報を表現する必要があります。通常、ログに含まれる情報はフリーテキストのデータです。そのままでは意味を機械的に抽出することが困難なので、フォーマットを統一するか、パース処理を介することが重要です。
共通に使えるログフォーマットについては、まだデファクトと呼べるものは特にない状況で、「Elastic Common Schema」「logfmt」などがあります。
こういった統一的なフォーマットを用いない場合、ログ収集/分析ツール上でパース処理をする方法もありますが、多種多様なログフォーマットに対してそれぞれパース処理を実装するのは困難なので、ある程度フォーマットをそろえる工夫も必要です。
クラウドネイティブなアーキテクチャにおけるログの難しさ
メトリクスと同様に、クラウドネイティブなアーキテクチャではログの収集、集約、分析(可視化/検索)も複雑化するので前述したような収集作業の複雑化はログ収集でも発生します。
またクラウドネイティブアーキテクチャにおいてコンポーネントが増加した環境だと、テキストで出力されるログについては、数値として集約されたメトリクスよりもデータ量が圧倒的に増加するので、大量のログを適切にラベリングした上で多様な観点で検索/可視化する必要があります。以下のような考慮点が重要です。
1.検索時に活用できるラベルを付与する仕組み
次のような観点で各ログ行を判別できるようにしなければ、後からフィルタリングすることが困難です。
- どのコンポーネント(コンテナ、Pod、Deployment、Namespace、アプリケーション)か
- 何が出力したログか
- ログレベル
2.複数のログを横断的に検索できる仕組み
ログを調査する際に、単一のログの単一行だけを確認することは“まれ”で、多くは複数のログの該当時間前後をひも付けて見ることが多いでしょう。従って、ログを検索するダッシュボードには、そういったクエリを投げられることが重要です。
3.ログのストレージをテナントごとに区切る
普段頻繁に利用するログはテナント境界ごとにそれぞれ別のストレージに配置することが望ましいです。理由としては2つあります。前述の通り、ログの量が多くなることによる、検索時の性能上の理由と「通常時にアプリケーション開発のエンジニアが見るべきログはそのエンジニアが担当するサービスのログのみにすべき」というセキュリティ上の理由です。
KubernetesのNamespaceでテナントを分割するケースは多いので、Namespaceごとにログのストレージを分けたり、それに加えてインフラチームのトラブルシューティング用に全アプリとインフラ関連のログが集約されたストレージを用意したりといった考慮が必要です。
OSSのログ集約ツール「Grafana Loki」で、各ログ行へのラベル付け(ログ収集エージェント「Promtail」や、柔軟な検索と可視化《Grepライクな検索、Prometheusの“それ”に似たクエリ言語による可視化》)をサポートしています。Lokiはクラウドネイティブなアーキテクチャにおけるログ集約ツールの選択肢の一つです。

トレースとは?
トレースとは、複数コンポーネントにまたがるリクエスト全体の流れを呼び出しの依存関係を考慮して可視化するものです。これはマイクロサービスアーキテクチャでコンポーネント間の呼び出しが頻発する状況において必要性が出てくる概念、技術です。
下図では、「A」というサービスを呼び出したことをきっかけに、内部ではAが依存している他のコンポーネント「B」「C」「D」「E」が連鎖的に呼び出される様子を示しています。

こういった呼び出し関係があった際に、リクエストの処理時間は図の右側のような包含関係になっています。これを可視化してくれるのがトレースという技術です。具体的にはリクエストの呼び出しの際に、「トレースID」という一意のIDをサービス間で伝搬させて、その呼び出し情報をデータベースに送信します。
例えば、次のような課題に対して監視やログのみで対応するには限界があります。
- 複数のマイクロサービス(あるいはDB、外部接続サービス)のどれが遅延の根本原因なのかの切り分けに時間がかかった
- コンテナを多数オーケストレーションしている場合、コンポーネントの数が多く、かつ多層化しているので、個々のコンポーネントのCPU使用率といったリソース状況を把握し続けることが困難
これらについてはトレースによるレイテンシベースでのアプローチが具体的な解決策です。
トレースを考える際には大きく分けて「呼び出し依存関係のグラフによる可視化」「分散トレーシング」の2つの観点があります。
呼び出し依存関係のグラフによる可視化
複雑なアーキテクチャでは、呼び出し元や呼び出し先が単一ではないケースが多く、どのサービスからどのサービスへの呼び出しが起こっているのかといった情報を整理することは困難です。

これに対するアプローチとして、トレースでは各サービスの呼び出し依存関係をグラフとして可視化して、それぞれの呼び出しにおけるリクエスト数、エラー数、レスポンスタイムをマッピングする手法が有効です。
例えば、OSSの「Kiali」は、下図のようにサービスメッシュ上の各Envoy Proxyから集約したREDメソッドのメトリクス(リクエスト数、エラー数、レスポンスタイム)をサービス依存グラフ上にマッピングして表示できます。

分散トレーシング
分散トレーシングとは、分散した一連のリクエストを収集して1つのトレースとしてひも付けて可視化する技術のことです。下図を見ると分かりやすいでしょう。

「A」というサービスへの呼び出しの中で、実は「B」と「E」を順に呼び出しており、さらにBの呼び出しの中では「C」と「D」を順に呼び出しているといったケースを想定します。この場合、Aの処理時間には図の右側のように、各呼び出し先の処理時間が包含されるはずです。仮にAというサービスへの呼び出しが遅延していたとしても、A自体の処理時間はほとんどないことが分散トレーシングから分かるので、後続のB〜Eの中で処理時間が支配的となっているものの解析が必要であることが分かります。
このような、呼び出し依存関係に基づいた処理時間ベースでのボトルネックの切り分けが分散トレーシングで可能となります。
例えば、OSS の「Jaeger」では、下図のようにトランザクション内で呼び出される各サービスの処理時間を分散トレーシングで表示できます。

その他のObservabilityシグナル
Observabilityの構成要素として、メトリクス、ログ、トレースを紹介しましたが、これ以外も構成要素に含める場合があります。
Whitepaperにはこれ以外のシグナルとして、より詳細に分析する情報取得「Dump」「Profile」が含められています。NewRelicによる定義では、「システムやアプリケーションで、どういった事象が、いつ発生したか」を表現する「Event」を含めて定義(ログよりも要約された情報。メトリクス、ログ、トレースと併せて「MELT」と表現)しています。このように、この辺りはまだまだ整理されていないので、今後の動向に注目です。
当然ですが、これらを1つのシグナルとして取得することは困難です。メトリクスに詳細情報を詰め込み過ぎるとコストがかかり、全ての運用をニアリアルタイムレイテンシでトレースするのもコストがかかるからです。従って、それぞれについて取得した後に、タイムスタンプや「どのコンポーネントから取得したか」などのメタデータを基にシグナル同士を関連付けて分析する必要があります。
Observabilityのシグナルについては、次回の記事で、複数のシグナルを関連付けながら分析する方法を紹介します。
Observabilityの各シグナルの取得にお薦めなOSSの組み合わせパターン
それぞれのObservabilityのシグナルを簡単に取得できるOSSの組み合わせパターンを筆者が幾つかピックアップして表にまとめました。

ピックアップした観点について、あくまで筆者の考えを簡単に記載します。今後の連載では、それぞれのシグナルやツールにフォーカスしてより深掘りするので、詳細は今後の連載を見てください。
メトリクス
- オススメ構成1:PrometheusとGrafanaを使った構成。OSSによるメトリクス収集のデファクト構成
- オススメ構成2:「OpenTelemetry」を利用することで、Prometheus以外のバックエンドの選択時(※)に、バックエンドの切り替えが可能。Prometheusより軽量なメトリクス収集というメリットを獲得できる構成
※Prometheus独自で運用していて、長期にわたって大量のメトリクスを保存することが性能的につらかったり、可用性を向上させたかったりする場合。高可用かつ水平スケールするPrometheus互換のOSSバックエンドストレージやSaaSに連携させたいようなシチュエーション
ちなみにOSS以外では、クラウドベンダーが提供するマネージドな監視サービス(「AWS CloudWatch」「Google Cloud Monitoring」など)や有料のAPMのSaaS(NewRelic、DataDog、Dynatraceなど)があります。最近はクラウドベンダー提供の監視サービスとして個人的に面白いと思っているのが、上述のような完全マネージドなものだけでなく、Prometheusをマネージドに提供するケース(「Amazon Managed Service for Prometheus」「Google Cloud Managed Service for Prometheus」)が出てきている点です。
これらのマネージドPrometheusを利用することにより、アップグレードやバックアップなどの運用タスクや、監視対象のシステム規模が大きくなったときのスケールアウトや可用性の向上を簡単できるようになり、面倒なPrometheusの運用管理から解放されます。
ログ
- オススメ構成1:Elastic スタック構成。全文検索が可能なので多角的な集計、フィルタリングが可能。「Elasticsearch」「Kibana」の扱いに慣れているなら、こちらが良さそう
- オススメ構成2:Lokiスタック構成。軽量に大量のログを扱える。Grafana Labsによる開発なので、GrafanaやTempoとのシームレスな連携が得意(「Prometheus メトリクス」やJaegerのトレーシングとログをGrafana上で統合的に確認するなど)
トレース
前述したように、トレースには依存関係グラフと分散トレーシングの2種類の表現があります。
依存関係グラフを表示するOSSはKialiです。Kialiが可視化する情報は、メッシュ内のEnvoyが公開するREDメトリクスを基にしています。
分散トレーシングについては次の観点です。
- オススメ構成1:JaegerのストレージをElasticsearchで実装している構成。JaegerのFAQで、Jaegerチームの推奨ストレージは機能と性能観点でElasticsearchとされている
- オススメ構成2:ストレージとしてElasticsearchやCassandraを運用するのが大変なので、Tempoを導入することでAmazon S3やGoogle Cloud Storageなどのオブジェクトストレージをバックエンドストレージとして利用できるようにした構成
現時点のObservabilityが抱える課題とそれに対するアプローチ
Whitepaperには、現時点のObservabilityとその実装方式が抱える課題、それに対するアプローチが記載されています。ここからは、その中から幾つかピックアップします。
複数のシグナルを扱う必要がある困難
Observabilityを構成するシグナルについては前述したように、これらを1つのシグナルとして収集することは非常に困難なので、複数のシグナルを収集する必要があります。ここまでで紹介したようなOSSをObservabilityのシグナルごとにセットアップして、運用するにはそれなりの苦労があります。OSSごとに技術やストレージシステム、インストール方法が異なるからです。
大きな組織だと各可観測性シグナルをインストール、管理、保守する個別の専門チームが存在したり、APMのSaaSを活用したりしている場合が多いでしょう。この課題について現状進んでいるアプローチとして2つのOSSプロジェクトが進んでいます。
- 「OpenTelemetry」:収集の標準化、統合
- メトリクス、トレーシングなどの複数のシグナルを計装、変換、転送する仕様と実装
- テレメトリーデータの収集方法やバックエンドへの送信方法を標準化するオープンな仕様
- 利用するメリットは次のように、Prometheus以外の入出力が期待できる点
- PrometheusだけではなくJaegerなど複数のテレメトリーデータフォーマットに対応(それにより単一のコレクタでテレメトリーデータが収集できる)
- Prometheusだけでなく複数のOSS/商用のバックエンドに送信できる(AWS CloudWatch、NewRelic、DataDog、「Splunk」など)
- 「Observatorium」:バックエンドの統合
- メトリック、ログ、トレースなど複数のシグナルを取り込んで保存、活用できるマルチシグナルバックエンド
- Prometheus(メトリクス)、Loki(ログ)、TempoやJaeger(トレーシング)などのAPIと相関機能を備えた単一の一貫したシステム
ログやトレースからメトリクスの生成
既に取得したログやトレースから、メトリクスを生成することで、より効率的かつ多角的にObservabilityを実装できます。OSSの中にはその仕組みを実装しているものがあり、次のような例があります。
例えば、一定間隔におけるエラー数や率のメトリクスをログから生成する活用方法が考えられます。ログから単発のエラーでアラートを仕掛けるとアラートに圧倒される場合があるので、10分間のエラー率といった目標を決めてアラートを設定する方が有意義です。
まとめ
今回は、Observabilityの初回として、Observabilityの概要とその構成要素、考慮点を説明しました。
分散かつスケールするクラウドネイティブなアーキテクチャを構成する上では、「いつ、何が、どこで起こっているのかを観測可能に保つ」というObservabilityの考え方とその実装は非常に重要です。一方でそれらを漏れなく実装するには、さまざまな観点での設計や実装が必要となります。
Observability周りのOSSプロジェクトが幾つもあり、今後もアップデートが続く分野なので、注視していきましょう。
本記事が、Observabilityを意識するきっかけになれば幸いです。今後も「Observability」を構成する各要素についてより深掘りするのでご期待ください。
次回は、「Observabilityでいろいろとデータが取れるのは分かったが、何からどう見ればいいか分からない」という方向けに、Observabilityの各シグナル(メトリクス、ログ、トレース)を、関連付けて分析(障害切り分け)する方法を解説します。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 New Relicがアプリの問題解決で開発者を助ける新機能、「開発者は本来の仕事に集中できる」
New Relicがアプリの問題解決で開発者を助ける新機能、「開発者は本来の仕事に集中できる」
New Relicの日本法人が可観測性プラットフォームで新機能「New Relic CodeStream」を発表した。 開発ツールを離れることなくソースコードの問題箇所を特定し、チーム内で情報を共有して迅速に解決できるという。 AWS、障害注入試験に向くフルマネージドサービス「AWS Fault Injection Simulator」を正式リリース
AWS、障害注入試験に向くフルマネージドサービス「AWS Fault Injection Simulator」を正式リリース
AWSはシステムに意図的に障害を発生させる障害注入試験に向いたフルマネージドサービス「AWS Fault Injection Simulator」の一般提供を開始した。CPUやメモリの使用量の急増といった破壊的なイベントを発生させてアプリケーションに負荷をかけ、システムの反応を監視して、改善できる。 ユーザーの幸福度を定量化――SLI、SLO実践の4ステップ
ユーザーの幸福度を定量化――SLI、SLO実践の4ステップ
SREは計測、自動化など取り組むことが多く、求められる知識量も少なくない。また周囲の理解が得られなければ、組織でSLI、SLOを定義してSREを実践するのも容易ではない。組織でSREに取り組む最初の一歩をどう踏み出せばいいのか。